做一些C端业务,不可避免的要引入一级缓存来代替数据库的压力并且减少业务响应时间,其实每次引入一个中间件来解决问题的同时,必然会带来很多新的问题需要注意,比如缓存一致性问题。
那么其实还会有一些其他问题比如使用Redis作为一级缓存时可能带来的热key、大key等问题,本文我们就热key(hot key)问题来讨论,如何合理的解决热key问题。
背景
热key是什么问题,如何导致的?
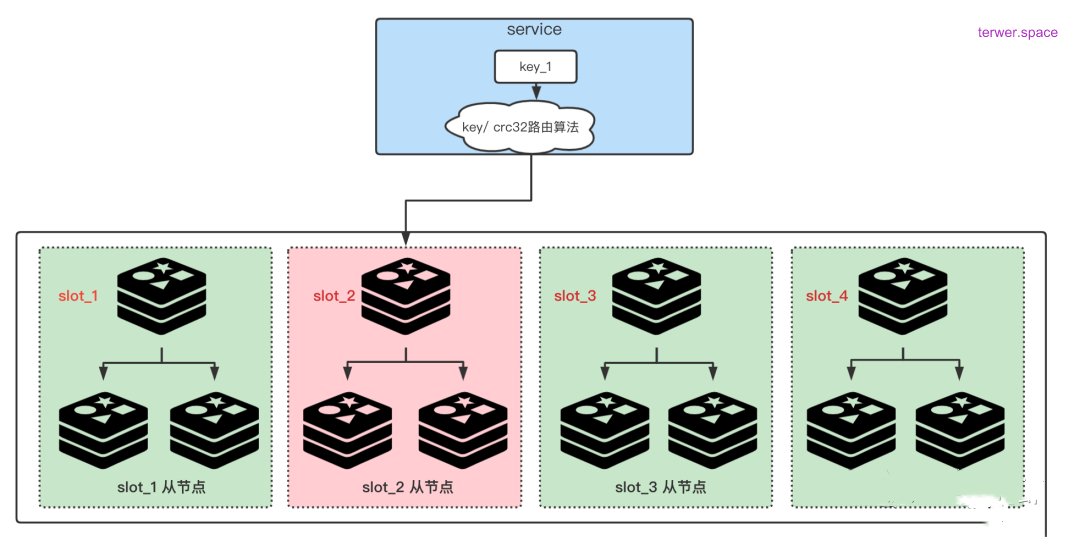
一般来说,我们使用的缓存Redis都是多节点的集群版,对某个key进行读写时,会根据该key的hash计算出对应的slot,根据这个slot就能找到与之对应的分片(一个master和多个slave组成的一组redis集群)来存取该K-V。但是在实际应用过程中,对于某些特定业务或者一些特定的时段(比如电商业务的商品秒杀活动),可能会发生大量的请求访问同一个key。
所有的请求(且这类请求读写比例非常高)都会落到同一个redis server上,该redis的负载就会严重加剧,此时整个系统增加新redis实例也没有任何用处,因为根据hash算法,同一个key的请求还是会落到同一台新机器上,该机器依然会成为系统瓶颈2,甚至造成整个集群宕掉,若此热点key的value 也比较大,也会造成网卡达到瓶颈,这种问题称为 “热key” 问题。
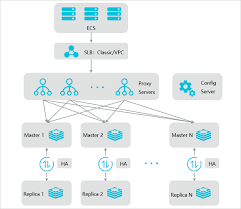
如下图1、2所示,分别是正常redis cluster集群和使用一层proxy代理的redis 集群key访问。
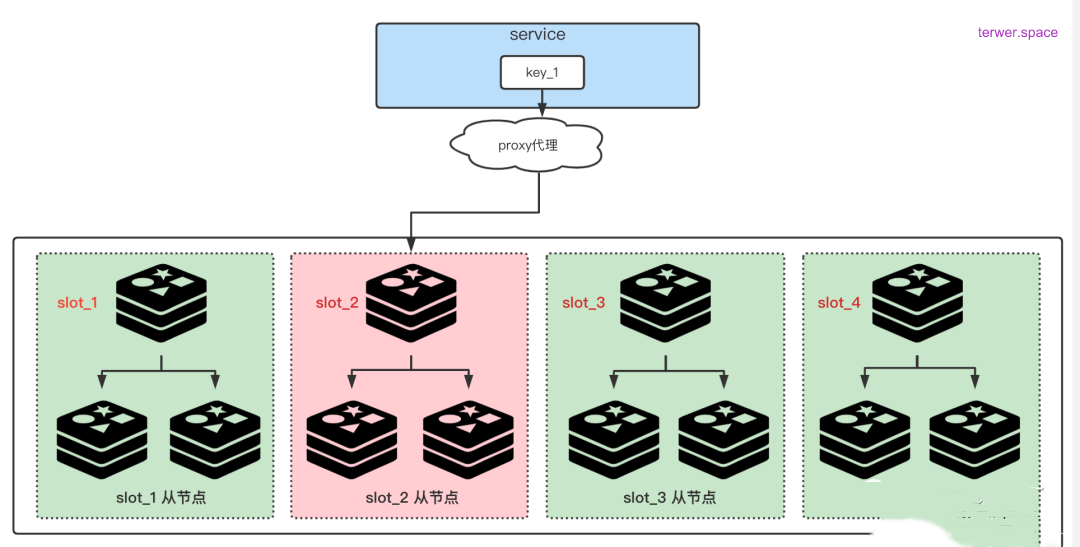
如上所说,热key会给集群中的少部分节点带来超高的负载压力,如果不正确处理,那么这些节点宕机都有可能,从而会影响整个缓存集群的运作,因此我们必须及时发现热key、解决热key问题。
1.热key探测
热key探测,看到由于redis集群的分散性以及热点key带来的一些显著影响,我们可以通过由粗及细的思考流程来做热点key探测的方案。
1.1 集群中每个slot的qps监控
热key最明显的影响是整个redis集群中的qps并没有那么大的前提下,流量分布在集群中slot不均的问题,那么我们可以最先想到的就是对于每个slot中的流量做监控,上报之后做每个slot的流量对比,就能在热key出现时发现影响到的具体slot。虽然这个监控最为方便,但是粒度过于粗了,仅适用于前期集群监控方案,并不适用于精准探测到热key的场景。
1.2 proxy的代理机制作为整个流量入口统计
如果我们使用的是图2的redis集群proxy代理模式,由于所有的请求都会先到proxy再到具体的slot节点,那么这个热点key的探测统计就可以放在proxy中做,在proxy中基于时间滑动窗口,对每个key做计数,然后统计出超出对应阈值的key。为了防止过多冗余的统计,还可以设定一些规则,仅统计对应前缀和类型的key。这种方式需要至少有proxy的代理机制,对于redis架构有要求。
1.3 redis基于LFU的热点key发现机制
redis 4.0以上的版本支持了每个节点上的基于LFU的热点key发现机制,使用redis-cli –hotkeys即可,执行redis-cli时加上–hotkeys选项。可以定时在节点中使用该命令来发现对应热点key。
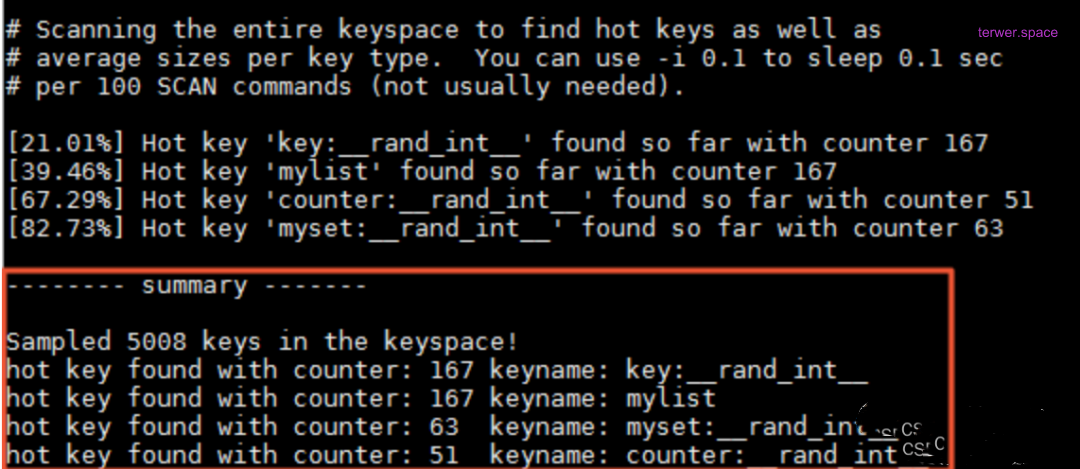
如下所示,可以看到redis-cli –hotkeys的执行结果,热key的统计信息,这个命令的执行时间较长,可以设置定时执行来统计。
1.4 基于Redis客户端做探测
由于redis的命令每次都是从客户端发出,基于此我们可以在redis client的一些代码处进行统计计数,每个client做基于时间滑动窗口的统计,超过一定的阈值之后上报至server,然后统一由server下发至各个client,并且配置对应的过期时间。
这个方式看起来更优美,其实在一些应用场景中并不是那么合适,因为在client端这一侧的改造,会给运行的进程带来更大的内存开销,更直接的来说,对于Java和goLang这种自动内存管理的语言,会更加频繁的创建对象,从而触发gc导致接口响应耗时增加的问题,这个反而是不太容易预料到的事情。
最终可以通过各个公司的基建,做出对应的选择。
2.热key解决
通过上述几种方式我们探测到了对应热key或者热slot,那么我们就要解决对应的热key问题。解决热key也有好几种思路可以参考,我们一个一个捋一下。
2.1 对特定key或slot做限流
一种最简单粗暴的方式,对于特定的slot或者热key做限流,这个方案明显对于业务来说是有损的,所以建议只用在出现线上问题,需要止损的时候进行特定的限流。
2.2 使用二级(本地)缓存
本地缓存也是一个最常用的解决方案,既然我们的一级缓存扛不住这么大的压力,就再加一个二级缓存吧。由于每个请求都是由service发出的,这个二级缓存加在service端是再合适不过了,因此可以在服务端每次获取到对应热key时,使用本地缓存存储一份,等本地缓存过期后再重新请求,降低redis集群压力。以java为例,guavaCache就是现成的工具。以下示例:
本地缓存对于我们的最大的影响就是数据不一致的问题,我们设置多长的缓存过期时间,就会导致最长有多久的线上数据不一致问题,这个缓存时间需要衡量自身的集群压力以及业务接受的最大不一致时间。
2.3 拆key
如何既能保证不出现热key问题,又能尽量的保证数据一致性呢?拆key也是一个好的解决方案。
我们在放入缓存时就将对应业务的缓存key拆分成多个不同的key。如下图所示,我们首先在更新缓存的一侧,将key拆成N份,比如一个key名字叫做“good_100”,那我们就可以把它拆成四份,“
good_100_copy1”、“good_100_copy2”、“good_100_copy3”、“good_100_copy4”,每次更新和新增时都需要去改动这N个key,这一步就是拆key。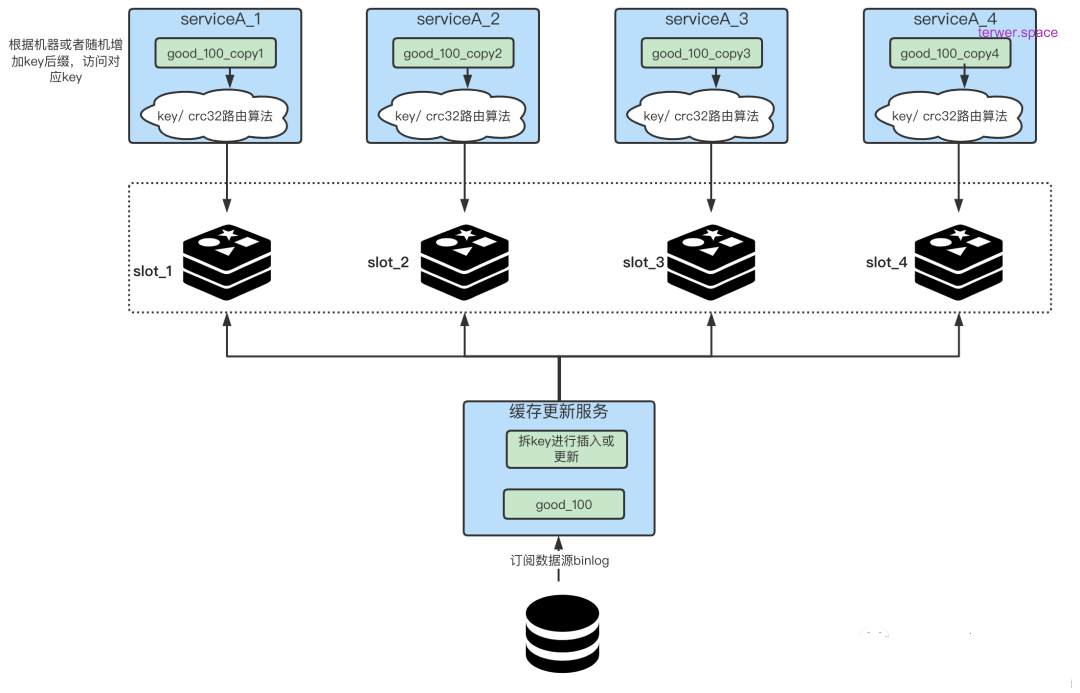
对于service端来讲,我们就需要想办法尽量将自己访问的流量足够的均匀,如何给自己即将访问的热key上加入后缀。几种办法,根据本机的ip或mac地址做hash,之后的值与拆key的数量做取余,最终决定拼接成什么样的key后缀,从而打到哪台机器上;服务启动时的一个随机数对拆key的数量做取余。
2.4 本地缓存的另外一种思路 配置中心
对于熟悉微服务配置中心的伙伴来讲,我们的思路可以向配置中心的一致性转变一下。拿nacos来举例,它是如何做到分布式的配置一致性的,并且相应速度很快?那我们可以将缓存类比配置,这样去做。
长轮询+本地化的配置。首先服务启动时会初始化全部的配置,然后定时启动长轮询去查询当前服务监听的配置有没有变更,如果有变更,长轮询的请求便会立刻返回,更新本地配置;如果没有变更,对于所有的业务代码都是使用本地的内存缓存配置。这样就能保证分布式的缓存配置时效性与一致性。
2.5 其他可以提前做的预案
上面的每一个方案都相对独立的去解决热key问题,那么如果我们真的在面临业务诉求时,其实会有很长的时间来考虑整体的方案设计。一些极端的秒杀场景带来的热key问题,如果我们预算充足,可以直接做服务的业务隔离、redis缓存集群的隔离,避免影响到正常业务的同时,也会可以临时采取更好的容灾、限流措施。
一些整合的方案
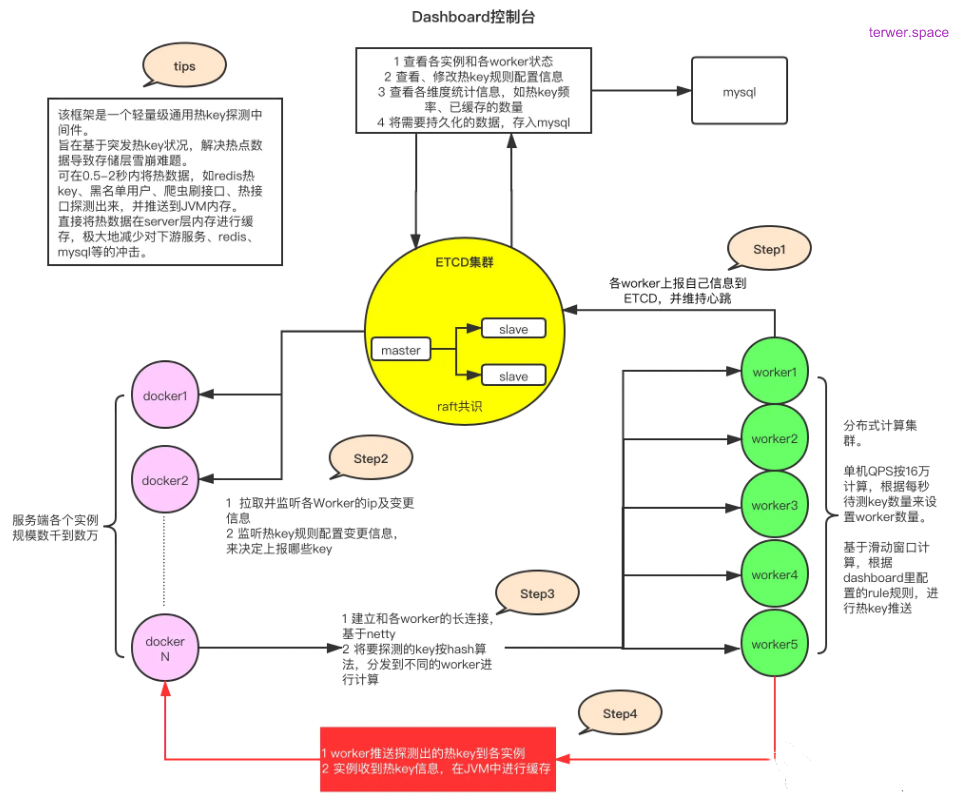
目前市面上已经有了不少关于hotKey相对完整的应用级解决方案,其中京东在这方面有开源的hotkey工具,原理就是在client端做洞察,然后上报对应hotkey,server端检测到后,将对应hotkey下发到对应服务端做本地缓存,并且这个本地缓存在远程对应的key更新后,会同步更新,已经是目前较为成熟的自动探测热key、分布式一致性缓存解决方案
总结
以上就是笔者大概了解或实践过的的如何应对热key的一些方案,从发现热key到解决热key的两个关键问题的应对。每一个方案都有优缺点,比如会带来业务的不一致性,实施起来较为困难等等,可以根据目前自身业务的特点、以及目前公司的基建去做对应的调整和改变。