
前言
在上一小节中,我们介绍channel,channel 的主要功能有处理网络IO读写,处理连接。这里需要注意的是channel仅仅是负责读写操作,在NIO中真正负责传输数据的是Buffer(缓冲区)。在NIO中,缓冲区的作用也是用来临时存储数据,可以理解为I/O数据的中转站。缓冲区直接对接channel,为其提供写入和读取的数据。通过操作buffer批量进行数据传输提高效率。在NIO中主要有八种缓冲区(ByteBuffer、CharBuffer、ShortBuffer,IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer)。在网络中传输中,字节是基本单位,NIO使用的ByteBuffer作为Byte的字节容器,但是NIO中实现过于复杂,因此Netty又写了一套ByteBuf来代替NIO的ByteBuffer,这一小节我们将深入ByteBuf源码,探究ByteBuf底层原理与实现细节。
ByteBuffer 快速回顾
所有的缓冲区都有4个属性:
capacity、limit、position、mark,并遵循:mark <= position <= limit <= capacity。capactiy | 容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变。 |
limit | 表示缓冲区的当前终点,不能对缓冲区超过极限的位置进行读写操作,且极限是可以修改的。 |
position | 位置,下一个要被读或写的元素的索引,每次读写缓冲区数据都会改变该值,为下次读写做准备 |
mark | 标记,调用mark()来设置mark=position,再次调用reset()可以让position恢复到标记的位置 |
实例化方法
ByteBuffer 是一个抽象类不能被实例化,ByteBuffer也提供了基础的构造方法,这些构造方法如下:
这个构造方法中需要传入6个入参,除了我们上面介绍的4个参数,还有hb(heap buffer)和offset(偏移量)。同时ByteBuffer类提供了4个静态工厂方法来获得ByteBuffer的实例:
这4个构造方法描述如下:
allocateDirect(int capacity):不使用JVM堆栈而是通过操作系统来创建内存块用作缓冲区,它与当前操作系统能更好的耦合,因此能进一步提高I/O操作速度。但是分配直接缓冲区的系统开销很大,因此只有在缓冲区较大并长期存在或者需要经常重用时,才使用这种直接缓冲区。
allocate(int capacity):从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器。
wrap(byte[] array):缓冲区的数据会存放在byte数组中,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就是一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组。
wrap(byte[] array, int offset, int length):在上一个方法的基础上可以指定偏移量和长度,这个offset也就是包装后byteBuffer的postion,length是limit-postion的大小,我们可以计算得出limit的位置为length+postion(offset)。
常用方法
byteBuffer提供了一些常用的方法,通过这些方法我们可以操作设置我们的buffer,也可以通过这些方法完成buffer的读写。这些方法的简单介绍如下:
limit(), limit(10):读取或者设置limit的值,并且4个基础属性都有这个方法。这两个方法一个get,一个set。
reset():把position设置成mark的值,相当于之前做过一个标记,现在要退回之前标记的地方。
clear():position=0;limit=capacity;mark=-1;将指针位置初始化,但是并不影响底层数据。
flip():limit=position;position=0;mark=-1;翻转,也就是让flip之后的position到limit这块区域变成之前的0到position这块,flip操作就是将一个准备写数据状态的缓冲区,变成一个准备读状态的缓冲区。
rewind():把postion设置为0,mark设置为-1,不改变limit的值。(从头开始。。)
remaining():return limit - position; 返回limit和position之间的相对位置差。
hasRemaining():return position < limit 返回是否还有未读内容。
compact():把从position到limit中的内容移到0到limit-position的区域,position和limit的取值也分别变成limit-position、capacity。如果先把position设置到limit,再compact,那么相当于clear。(把还没读的部分压缩到最前面。真“压缩”)
get():相对读,从position位置读取一个byte,并将position+1,为下次读写作准备。
get(int index):绝对读,读取byteBuffer底层的bytes中下标为index的byte,不改变position。
get(byte[] dst, int offset, int length):从position位置开始相对读,读length个byte,并写入dst下标从offset到offset+length的区域。
put(byte b):相对写,向position的位置写入一个byte,并将position + 1,为下次读写作准备。
put(int index,byte b):绝对写,向byteBuffer底层的bytes中下标为index的位置插入byte b,不改变postion。
ByteBuf 源码剖析
在网络传输中,字节是基础单位,NIO使用ByteBuffer作为Byte容器,前面我们也对其进行了简单的回顾,但是NIO的实现过于复杂,因此Netty写了一套Channel代替NIO的Channel,也写了一套ByteBuf代替NIO的ByteBuffer。和ByteBuffer一样。Netty实现的ByteBuf的子类也非常多,这里我们只针对ByteBuf进行详细的剖析。下图展示了ByteBuf的主要特性,图中列出的类都是在本小节中要重点梳理的类。其中前三个特性针对ByteBuffer的缺点进行了改进。
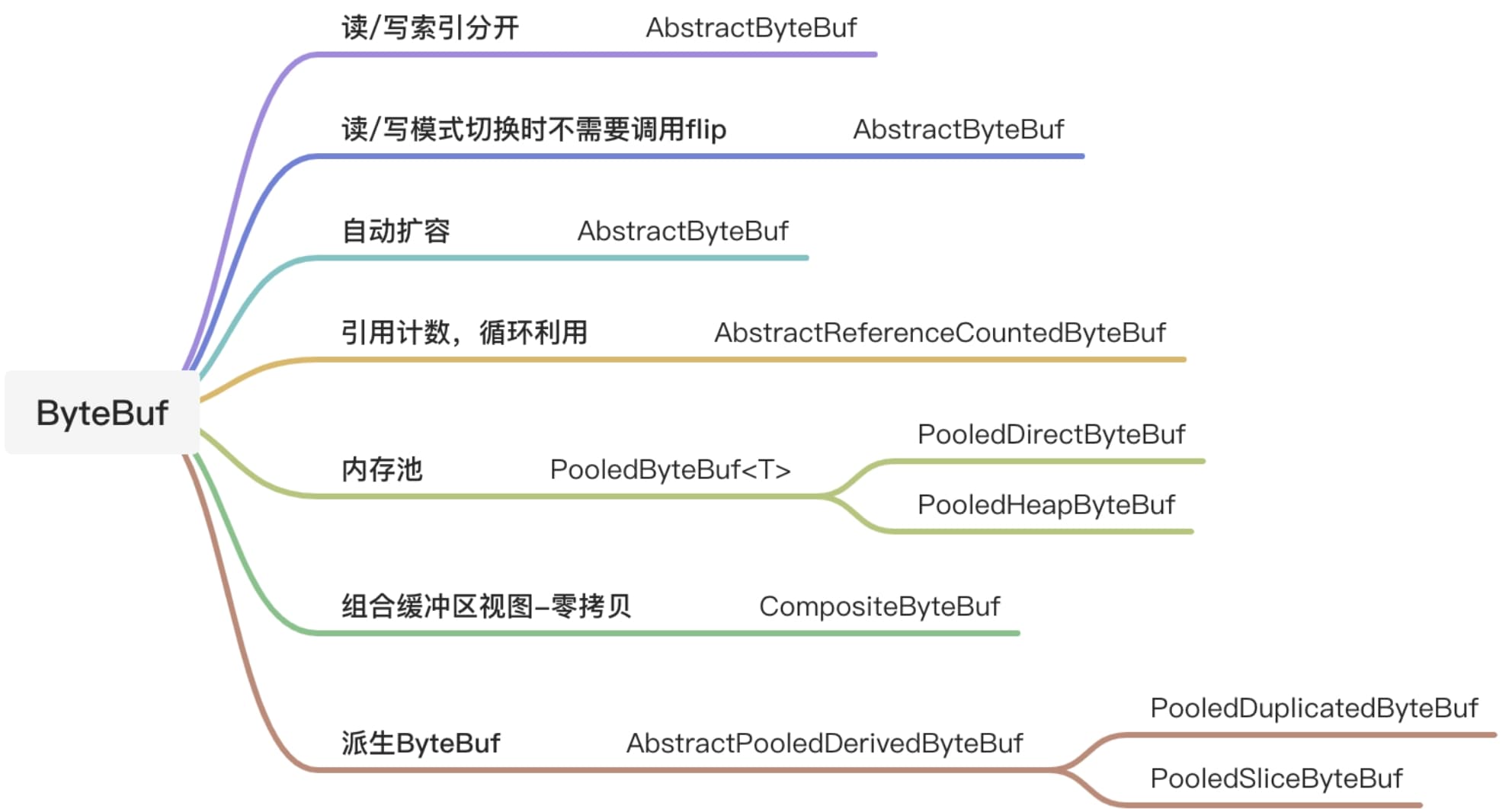
NIO ByteBuffer 只有一个位置指针position,在切换读写状态时,需要手动调用flip()方法或rewind()方法,已改变position的值,而且ByteBuffer的长度是固定的,一旦分配完成就不能再进行扩容和收缩,当需要放入对象大于ByteBuffer的容量时会发生异常。每次编码都要进行可写空间校验。Netty的AbstractByteBuf将读写指针分离,同时在写操作进行自动扩容。对其使用而言,无须关心底层实现,且操作简便、代码无冗余。NIO ByteBuffer的duplicate()方法可以复制对象,复制后的对象与原对象共享缓冲区的内存,但其position指针独立维护。Netty的ByteBuf也采用了这功能,并设计了内存池。内存池是由一定大小和数量的内存块ByteBuf组成的,这些内块的大小默认为16MB。当从Channel中读取数据时候,无需每次都分配新的ByteBuf,只需要从大的内存块中共享一份内存,并初始化其大小及独立维护读/写指针即可。Netty采用对象引用计数,需要手动回收。每复制一份ByteBuf或派生出新的ByteBuf,其引用都需要增加。
AbstractByteBuf 源码剖析
AbstractByteBuf是ByteBuf的子类,它定义了一些公共属性,如读索引、写索引、mark、最大容量等。AbstractByteBuf实现了一套读写操作的模版方法,其缓冲区真正的数据读写由其子类完成。AbstractByteBuf的核心功能如下,接下来我们对其的核心功能进行源码剖析。
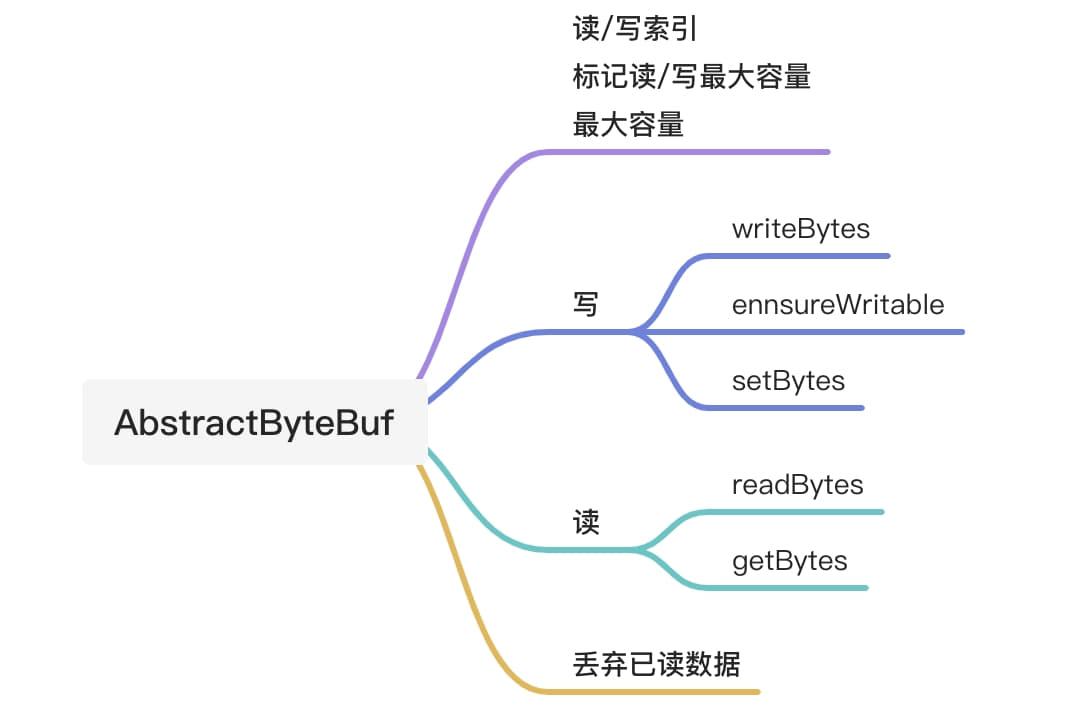
AbstractByteBuf的写操作 writeBytes()方法涉及扩容,在扩容时,除了合法的校验,还需要计算新的容量值,若内存大小为2的整数次幂,则AbstractByteBuf的子类比较好分配内存,因此扩容后的大小必须是2的整数次幂。具体代码解读如下:
读操作 readBytes() 方法源码分析如下:
readBytes()方法调用getBytes()方法从当前的读索引开始,将length个字节复制到目标,byte数组中。由于不同的子类对应不同的复制操作,因此AbstractByteBuf中的getBytes()是一个抽象方法,留给子类实现。下面是一个具体子类PooledHeapByteBuf对getBytes()的实现。
另一子类PooledDirectByteBuf对getBytes()方法的实现如下:
通过上面的梳理,对AbstractByteBuf的核心部分已经有了一个大致的了解,下面通过对AbstractReferenceCountedByteBuf类进行深入剖析来了解Netty是如何运用引用计数法管理ByteBuf生命周期的。
AbstractReferenceCountedByteBuf 源码剖析
Netty在进行I/O读写时候使用了堆外内存,实现了零拷贝,堆外直接内存DirectBuffer的分配与回收效率都远远低于JVM堆内存上对象的创建与回收速率。Netty使用引用计数法来管理Buffer的引用与释放。Netty采用了内存池设计,先分配一块大内存,然后不断地重复利用这块内存。例如,当从SocketChannel 中读取数据时,先在大内存块中切一小部分来使用,由于与大内存共享缓存区,所以需要增加大内存的引用值,当用完小内存后,再将其放回发内存块中,同时减少其引用值。
运用到引用计数法的ByteBuf大部分都需要继承AbstractReferenceCountedByteBuf类,该类有一个引用值属性—refCnt,其大部分功能与此属性有关系。
由于ByteBuf操作可能存在多线程并发使用的情况,其refCnt属性的操作必须是线程安全的,因此采用了volatile 来修饰,以保证多线程可见。在Netty中,ByteBuf会被大量地创建,为了节省内存开销,通过AtomicIntegerFieldUpdater来更新refCnt的值,而没有采用AtomicInteger类型。因此AtomicInteger类型的创建的对象比int类型多占用16B的对象头,当有几十万或几百万ByteBuf对象时候,节约的内存可能有几十MB或几百MB。一下是AbstractReferenceCountedByteBuf的功能图。
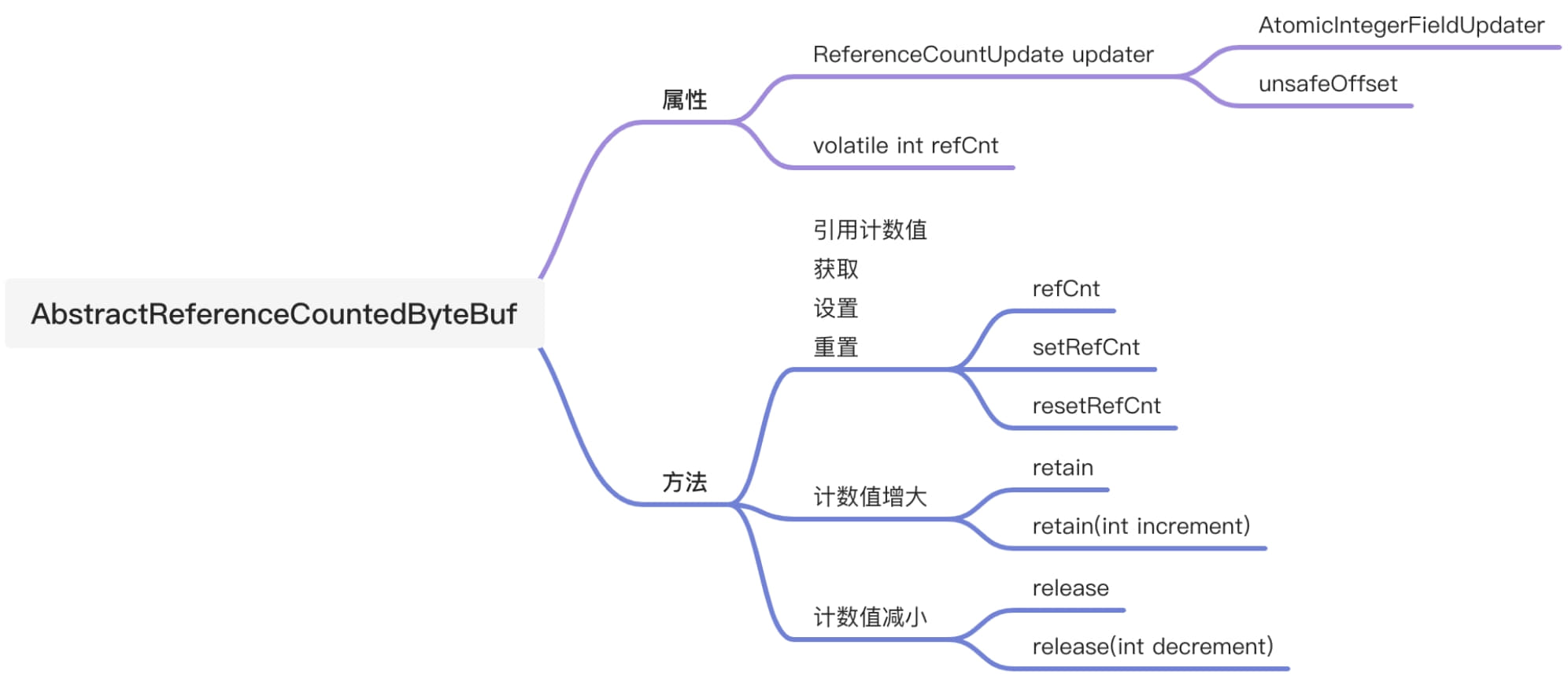
AbstractReferenceCountedByteBuf的大部分功能都是由updater属性完成,其核心属性解读如下:
在旧的版本中,refCnt引用计数的值每次加1或减1,默认为1,大于0表示可用,等于0表示已释放。在Netty v4.1.38.Final版本中,refCnt的初始值为2,每次操作也不同。在下面源码剖析中会得到答案。
ReferenceCountUpdater 源码剖析
ReferenceCountUpdater是AbstractReferenceCountedByteBuf的辅助类,用于完成对引用计数制进行操作。虽然它的大部分功能都是和引用计数有关,但与Netty之前的版本相比有很大的改动,主要是Netty v4.1.38.Final 版本采用了乐观锁方式来修改refCnt,并在修改后进行校验。例如,retain()方法在增加了refCnt后,如果出现了溢出,则回滚并抛出异常。在旧版本中,采用的似乎原子性操作,不断地提前判断,并尝试调用compareAndSet。与之相比,新版本的吞吐量有所提高,但若还是采用refCnt的原有方式,从1开始每次加1或减1,则会引发一些问题,需要重新设计。这也是新版本改动较大的原因。一下是ReferenceCountUpdater的功能图。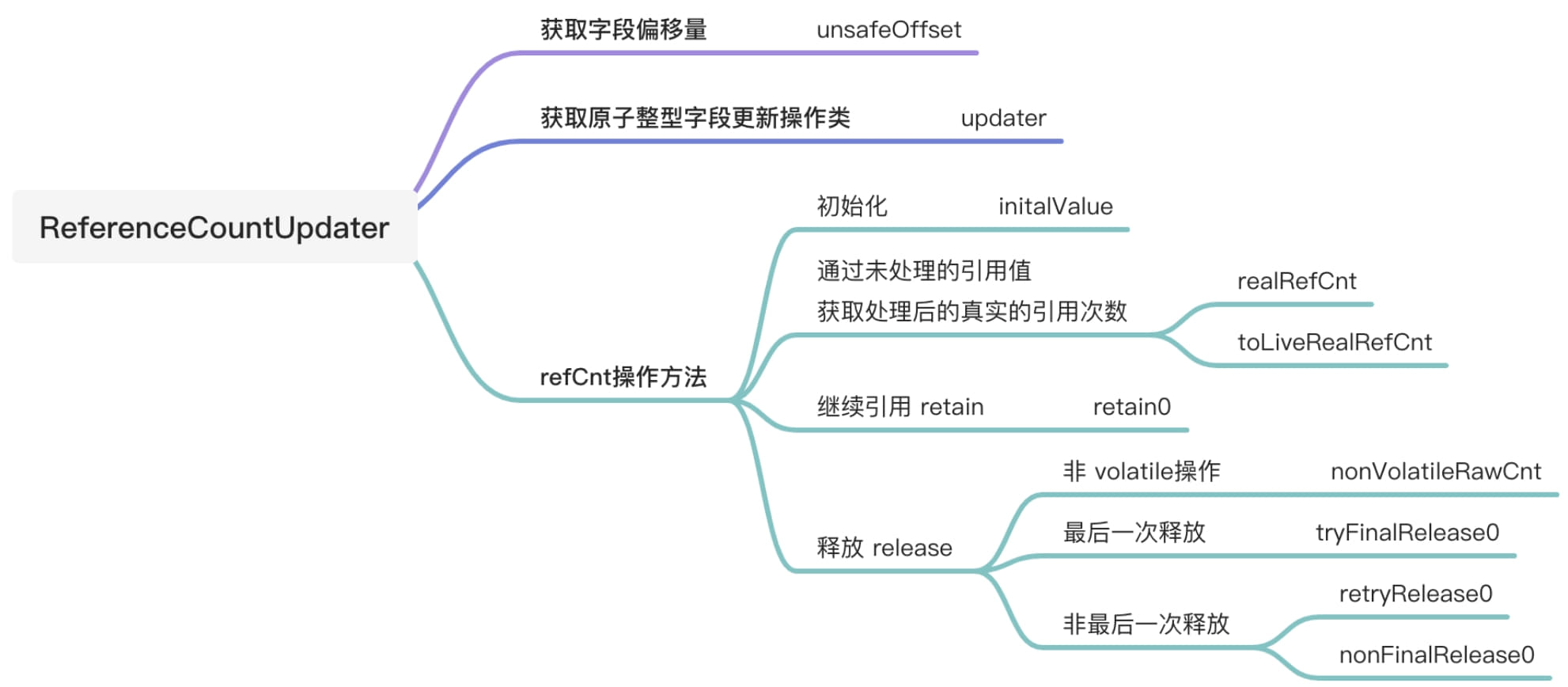
由duplicate()、slice()衍生的ByteBuf与原生对象共享底层的Buffer,原对象的引用可能需要增加,引用增加的方法为retain0()。
retain() 剖析解读
retain0()方法为retain()方法的具体实现,其代码解析如下:
旧版本代码如下:
在进行引用计数的修改时,并不会先判断是否会出现溢出,而是先执行,执行完成之后再进行判断,如果溢出则进行回滚。在高并发情况下,与之前版本对比,Netty v4.1.38.Final的吞吐量会有明显的提升,但refCnt不是每次都进行加1或减1的操作,主要原因是修改前无法判断(因为场景没有加锁,所以修改前判断没有意义,可能正在修改时候已经不是判断时的值,还是会造成溢出。如果已经出现了溢出,再循环判断修改依旧没有意义了)。
release() 剖析解读
若有多条线程同时操作,则线程1调用ByteBuf的release()方法,线程2调用retain()方法,线程3调用release()方法,会导致ByteBuf出现多次销毁操作。若采用奇数表示销毁状态,偶数表示正常状态,则该问题得以解决,最终释放后会变成奇数。ByteBuf使用完后需要执行release()方法,release()方法的返回值为true或false,false表示还有引用存在,true表示无引用,此时会调用ByteBuf的deallocate()方法进行销毁。相关代码解读如下:
奇偶数表示不同状态的巧妙使用。
ReferenceCountUpdater 主要运用JDK的CAS来修改计数器,为了提高性能,还引入了Unsafe类,可直接操作内存。至此,ByteBuf的引用计数告一段落,下面会对Netty的另一种零拷贝方式组合缓冲区视图 CompositeByteBuf进行详细剖析。CompositeByteBuf 源码剖析
CompositeByteByteBuf的主要功能是组合多个ByteBuf,对外提供统一的
redaIndex和writeIndex。由于它只是将多个ByteBuf的实例组装到一起形成了一个统一的视图,并没有对ByteBuf中的数据进行拷贝,因此也属于Netty零拷贝的一种,主要应用与编解码。例如,将消息头和消息体两个ByteBuf组合到一块进行编码,可能会觉得Netty有写缓存区,其本身就会存在多个ByteBuf,此时只需把两个ByteBuf分别写入缓冲区 ChannelOutboundBuffer即可,没必要使用组合ByteBuf。但是在将ByteBuf写入缓存区之前,需要将整个消息进行编码解码,如消息长度,此时需要把两个ByteBuf合并成一个,无须额外处理接可以知道其整体长度,因此使用CompositeByteBuf是非常合适的。在解码时,由于Socket通信传输数据会产生粘和半包问题,因此需要一个读半包字节的容器,这个容器采用CompositeByteBuf比较合适。将每次从Socket中读取到的数据直接放入此容器中,少了一次数据拷贝。Netty的解码类ByteToMessageDecoder默认的读半包字节容器Cumulator未采用CompositeByteBuf,此时可在其子类中调用 setCumulator 进行修改。但需要注意的是,CompositeByteBuf 需要依赖使用场景。因为CompositeByteBuf使用了复杂的逻辑算法,所以其效率有可能比使用内存拷贝的低。CompositeByteBuf内部定义了一个Component类型的集合,实际上,Component是ByteBuf的包装实现类,它聚合了ByteBuf对象并维护了ByteBuf对象在集合中的位置偏移信息等。下图展示了CompositeByteBuf功能。
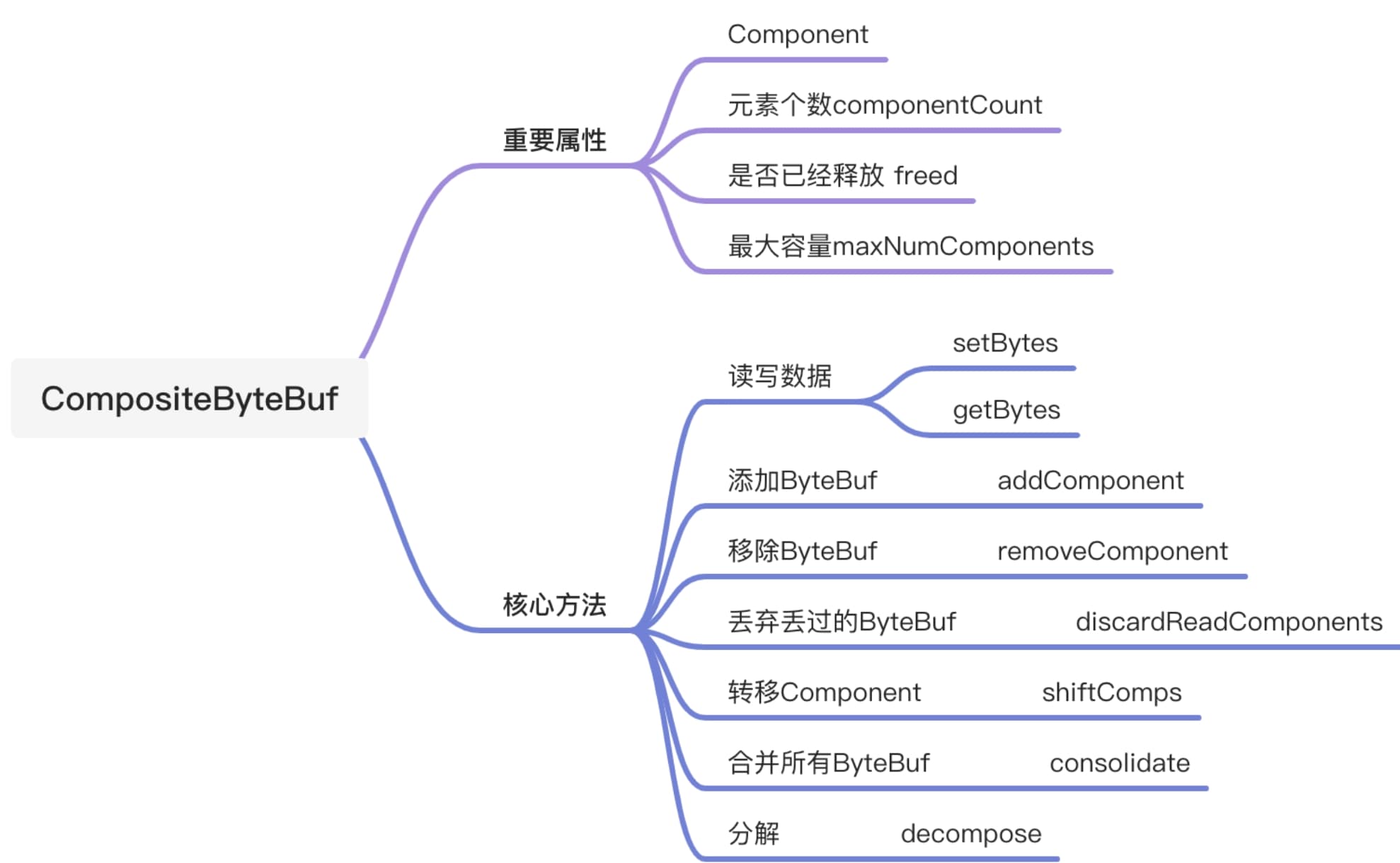
在开始分析CompositeByteBuf之前,我们先来了解下它的基本结构和属性。
基本结构与属性
CompisteByteBuf中有两个重要的属性:
CompositeByteBuf的大致结构如下图,里面有一个Component数组,Component里面放着缓冲区,还有各种索引。外部操作好像是只操作了CompositeByteBuf,其实具体操作Component中的缓冲区。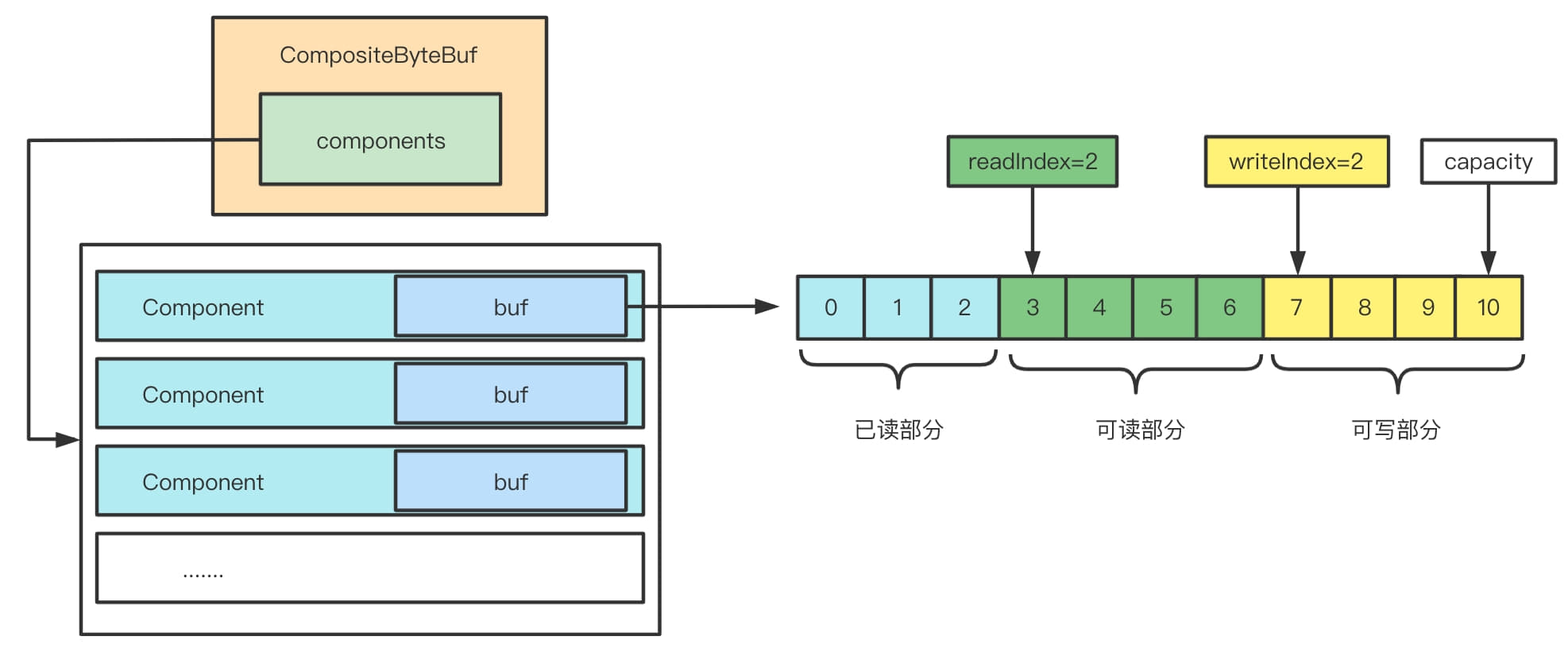
Component是CompositeByteBuf的核心组建,CompositeByteBuf也叫做组合ByteBuf,通过Component数组将多个ByteBuf合并成一个逻辑上一个BytBuf,避免了各个ByteBuf之间的相互拷贝,提高了整体的效率。想要深入理解CompositeByteBuf,Component是一个绕不开的对象,Component有以下一些属性:
addComponent() 剖析解读
下面是关于
addComponent()方法及相关方法的代码解读:在这里会调用一个
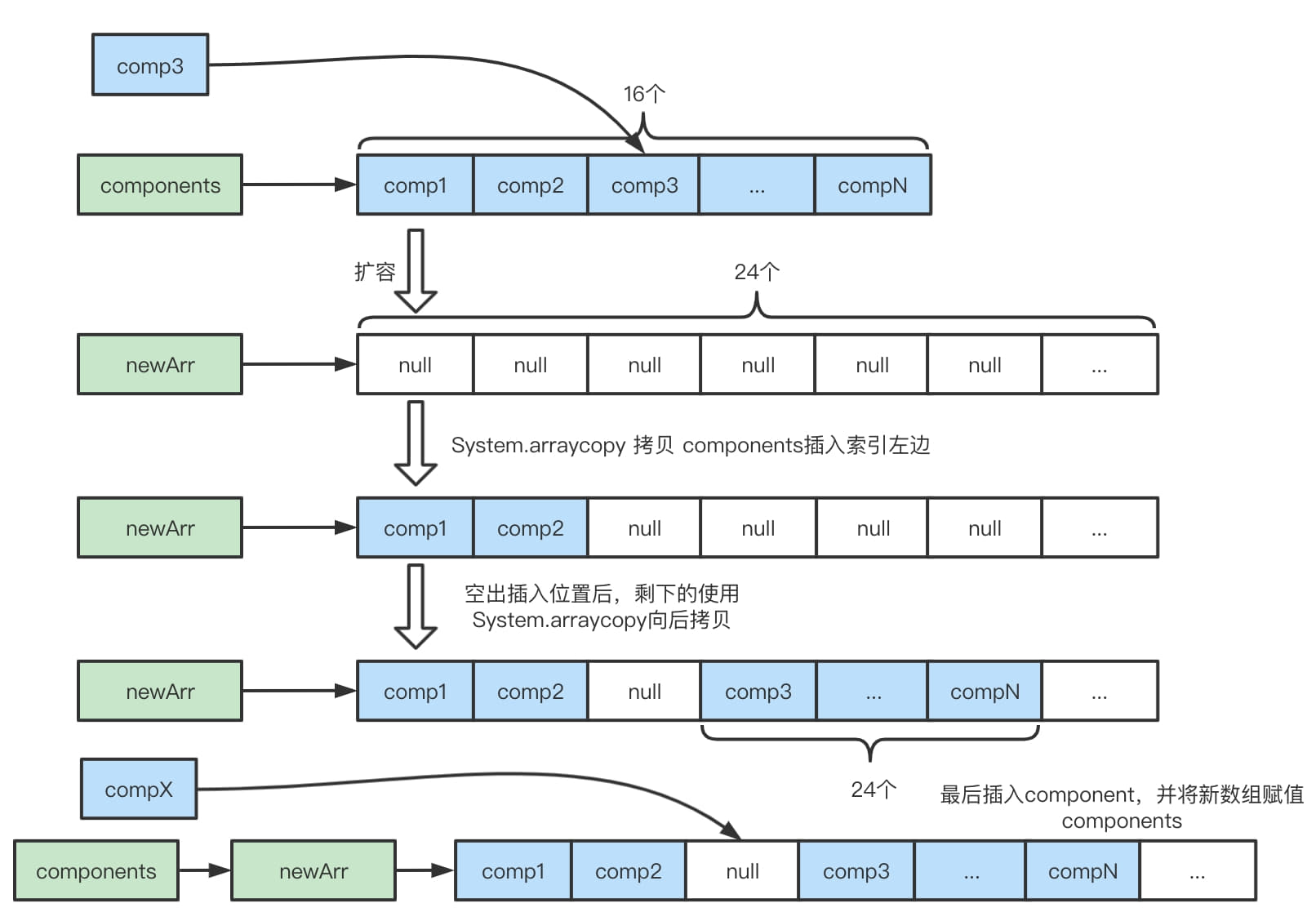
addComponent0的方法,在这个方法中会先将传入的ByteBuf解掉包装,然后根据其读索引,可读长度和偏移量等信息封装成一个Component,然后添加到components数组中,在这个过程中还会涉及到对原有components数组的扩容移动等操作。newComponent()先获取源缓冲区buf的读索引和可读长度,然后将buf的包装去掉,获取去掉unwrapped的读索引unwrappedIndex,最后创建Component。addComp()这里就要将组建插入到数组相应的位置,默认当然是最后一个位置,也就是componentCount。shiftComps() 插入新的component,可能是中间位置,那就需要腾出这个位置,也可能是最后,也可能要扩容。扩容的大体逻辑如下:
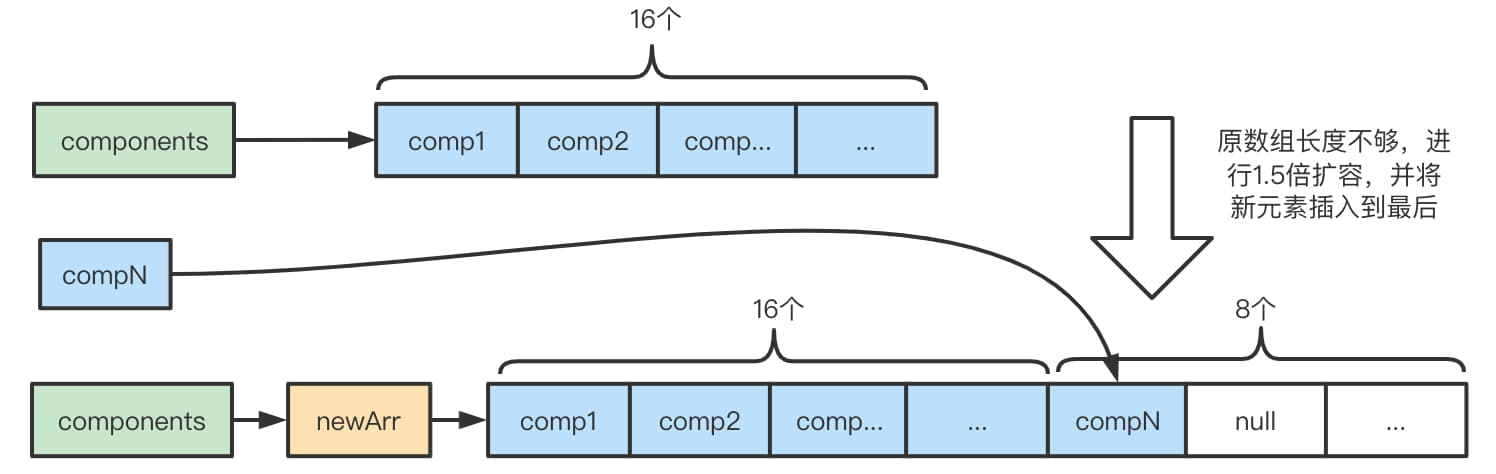
- 如果需要扩容,扩容大小是原来大小的1.5倍,如果插入是最后,那就直接扩容拷贝到新数组里,如果不是插入到中间的话,需要把前后的元素分别拷贝到新数组的位置上,留出要插入的索引的位置,最后插入。
- 如果不进行扩容,默认插入位置就是最后,否则的话需要把位置所在元素以及后面的往后挪,把位置腾出来,插入数据。
要注意这里的数组拷贝全是浅拷贝
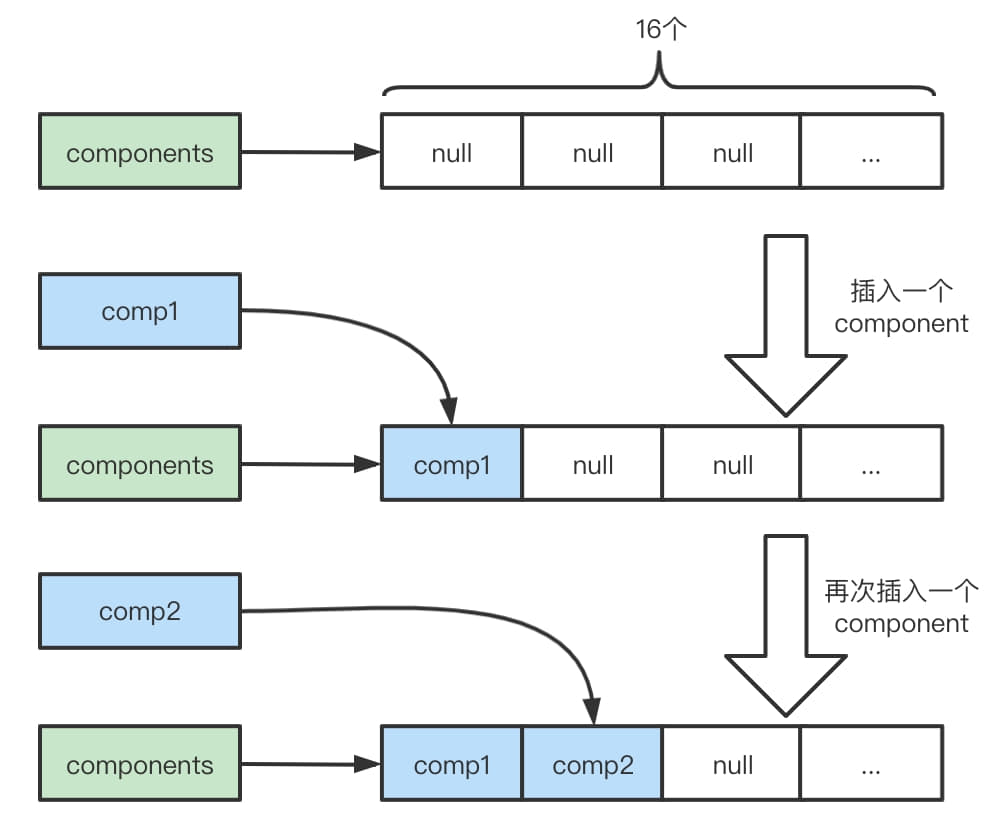
Arrays.copyOf和System.arraycopy,只是拷贝引用。以下几个图是插入的逻辑分析:
- 插入到最后,无需扩容:
- 扩容,插入到最后。
- 插入到中间需要移动元素,再插入并且不进行扩容。
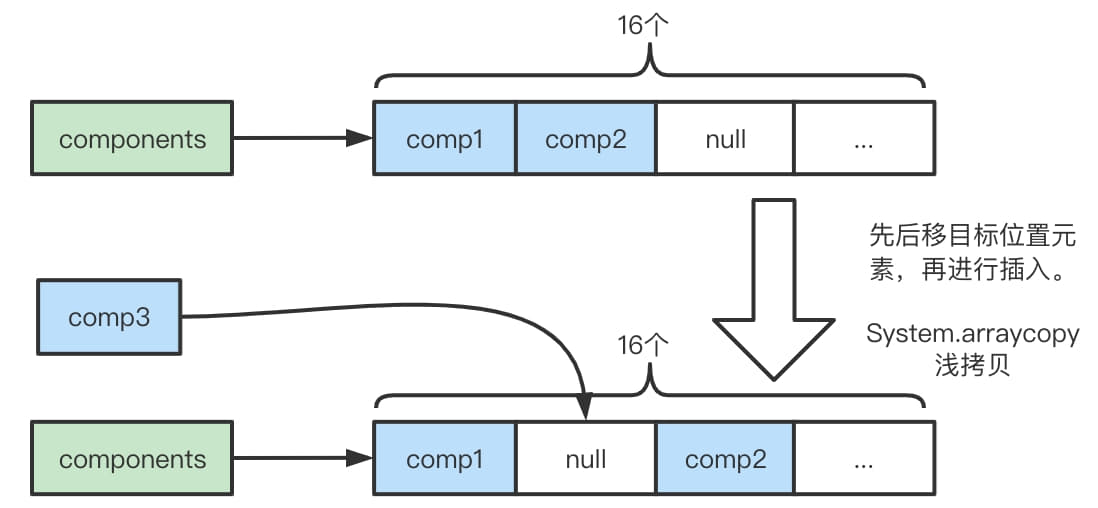
- 插入到中间,并进行扩容。
updateComponentOffsets()如果是有可读数据,且插入在中间位置就需要更新位置以及后面的component的索引,因为被插队了,偏移就变了。
consolidateIfNeeded()这个方法就是合并操作,当components数组中的个数超过限制的最大个数时(默认16个),就会开始进行合并操作。实际的合并操作由consolidate0来完成。操作逻辑也比价简单。首先计算component的可读字节数,然后创建一个新buffer,然后循环遍历要合并的component并将他们转移到新的buffer中。最后把他们在原数组中移除,将新的buffer封装成一个新的component并重新加入到components数组中,同时更新索引偏移量。removeComponent() 剖析解读
上面我们分析了将component加入数组的逻辑addComponent()的逻辑,当然有add操作就会有remove操作,而移除操作相较于add,removeComponent()操作则简单不少,其实前面的合并操作也设计了一些移除操作。在移除过程中我们不必考虑数组的扩容问题,只需要删除需要移除的元素,并整理数组更新索引即可。以下是移除操作代码剖析。
discardReadComponents() 源码剖析
compositeByteBuf的最后还有一个重要的方法
discardReadComponents(),即移除已读字节,其方法解读如下:PooledByteBuf 源码剖析
PooledByteBuf是ByteBuf非常重要的抽象类,这个类继承于
AbstractReferenceCountedByteBuf,其对象主要由内存分配器PoolByteBufAllocator创建。比较常见的实现类有两种:一种是基于对外直接内存池构建的PoolDirectByteBuf,是Netty在进行IO读写的时的内存分配的默认方式,堆外直接内存可以减少内存数据拷贝次数;另一种是基于堆内内存池构建的PoolHeapByteBuf。这里我们简单分析PooledByteBuf,池化的ByteBuf涉及到一些Netty的内存的分配管理策略这个我们会在后面的小节中详细分析。基础结构与属性
创建
PooledByteBuf对象的开销非常大,而且在高并发的情况下,当网络IO进行读写时会创建大量的实例。因此,为了降低系统的开销,Netty对Buffer对象进行了池化,缓存了Buffer对象,使对此类型的Buffer可进行重复利用,PooledByteBuf是从内存池中分配出来的Buffer,因此他需要包含内存池的相关信息,如内存块Chunk、PooledByteBuf在内存块中的位置及本身所占空间的大小等。下图描述了PooledByteBuf的核心功能和属性。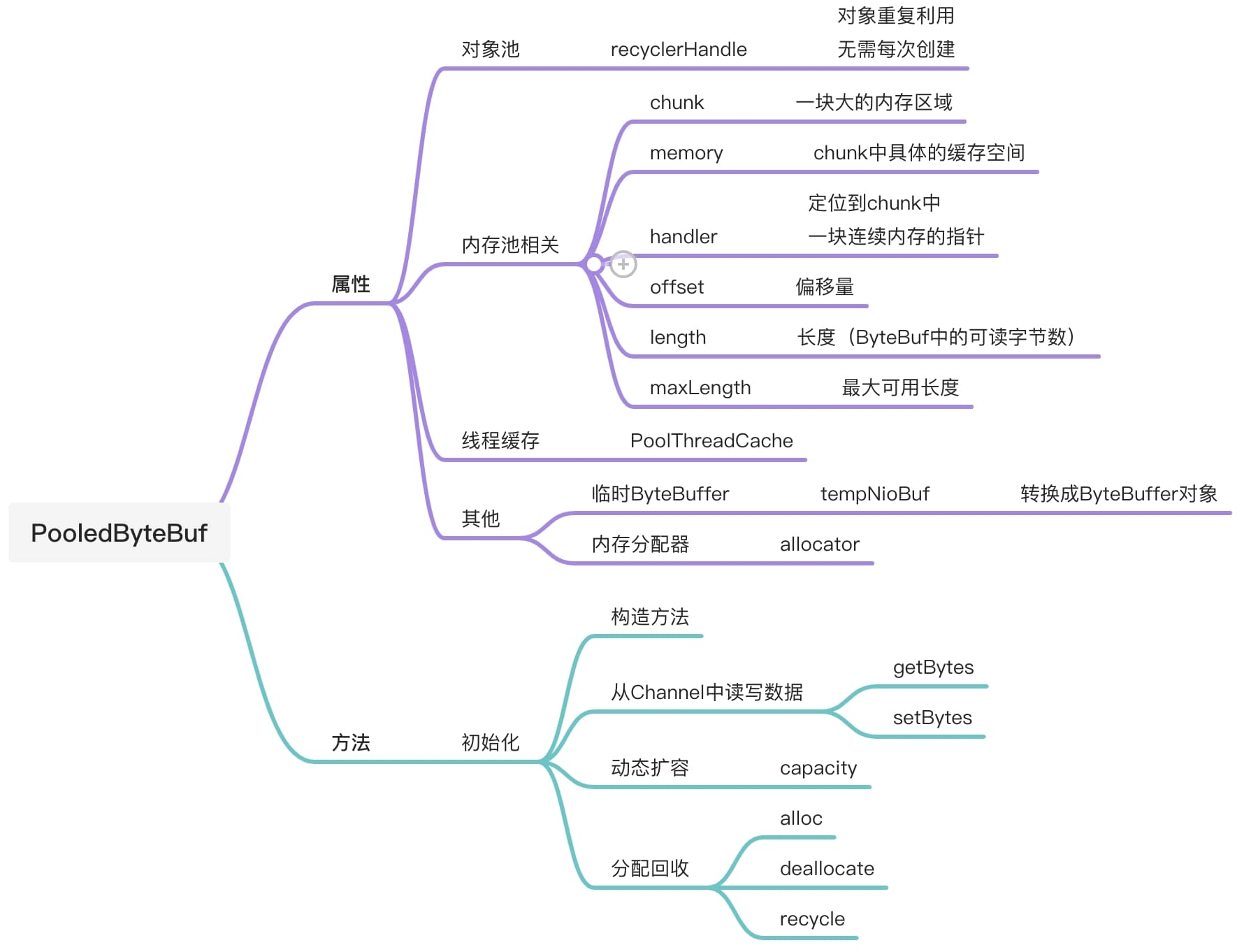
如果对于这块的内存池的部分感到陌生不知所措,不必感到沮丧。后面我们会对Netty的池化内存管理进行分析,完成那部分的梳理,对于这里的各个属性字段也就熟悉了。
初始化与从Channel中读写数据
以下是PooledByteBuf的初始化方法解读,这个初始化的过程很简单,前面我们也提到了PooledByteBuf是从内存池中分配出来的Buffer。因此需要记录当前ByteBuf是属于那块chunk,哪部分缓存空间。因此这下面会带有
chunk、memory、handler等属性。从Channel中写数据的解读剖析如下:
往Channel中读入数据的解读如下:
自动扩容与代码对象回收
有容量上限就会涉及到有容量就会有扩容操作。
PooledByteBuf 对象回收代码解读如下:
总结
这一小节我们梳理了ByteBuf,开篇我们快速回顾了ByteBuffer,介绍了了ByteBuf的实例方法和一些常用方法。随后我们梳理了Netty中ByteBuf的子类,我们介绍了
AbstractByteBuf、AbstractReferenceCountedByteBuf、ReferenceCountUpdater基于引用计数的ByteBuf的实现,通过引用计数来管理,ByteBuf的申请与释放。随后我们介绍了PooledByteBuf。它继承于AbstractReferenceCountedByteBuf,基于引用计数,对内存资源进行池化管理,避免重复的申请和释放带来的资源消耗。中间我们还用了比较大的篇幅去介绍了CompositeByteBuf,它通过把多个ByteBuf组合起来,然后通过把ByteBuf封装成一个个component组成的components数组来管理操作多个ByteBuf。随后我们梳理剖析了它的 add、remove和discard等方法。下一小节开始我们结合这一小节和前面几个小结梳理的Netty核心组件,来看看Netty的读写流程是怎么样。








