Spring AI 中的 DocumentTransformer 与 RAG 深度解析
本文将深入解析 Spring AI 中的 DocumentTransformer 和检索增强生成(RAG)模块,详细讲解每个核心类的功能、参数、使用方法以及高级技巧。通过结合实际代码示例和应用场景,帮助开发者全面掌握这些组件的使用。
一、Spring AI 中的 DocumentTransformer
DocumentTransformer 是 Spring AI ETL(Extract, Transform, Load)管道的关键组件,负责对文档执行转换操作,确保数据以最优格式进入后续的存储和检索阶段。

1.1 核心功能与实现类
DocumentTransformer 提供了多种实现类,每种实现类针对不同的转换需求提供了专门的功能。
1.1.1 TextSplitter:文档切割
功能描述
TextSplitter 用于将长文档切割成更小的文本块,以适应 AI 模型的上下文窗口限制。
核心实现类:TokenTextSplitter
- 基于 Token 分割:采用 CL100K_BASE 编码,支持按 Token 数量分割文本。
- 参数解析:
defaultChunkSize:每个文本块的目标 Token 数量(默认 800)。minChunkSizeChars:每个文本块的最小字符数(默认 350)。minChunkLengthToEmbed:可嵌入分块的最小长度(默认 5)。maxNumChunks:单个文本生成的最大分块数(默认 10000)。keepSeparator:是否保留分隔符(默认 true)。
使用示例:
高级技巧:
- 动态分块:根据文档类型动态调整分块大小。例如,技术文档可采用更小的分块以保留细节。
- 分块优化:在分块时尽量保持语义完整性,避免在句子中间切割。
效果:
- 提高检索效率:小块文档更容易与查询匹配。
- 节省内存:避免加载整个文档到内存。
1.1.2 ContentFormatTransformer:元数据格式化
功能描述
ContentFormatTransformer 将文档中的元数据转换为键值对格式,确保数据一致性。
核心实现:
- 模板配置:支持自定义元数据格式模板。
- 参数解析:
formatTemplate:指定元数据格式的模板字符串。metadataKey:指定存储格式化后元数据的键。
使用示例:
高级技巧:
- 统一格式:在多源数据整合时,统一元数据格式以便后续检索和分析。
- 嵌套结构支持:通过复杂模板支持嵌套元数据结构。
效果:
- 提升数据一致性:确保所有文档的元数据格式统一。
- 便于检索:格式化的元数据更容易被检索系统使用。
1.1.3 SummaryMetadataEnricher:摘要生成
功能描述
SummaryMetadataEnricher 利用 AI 模型为文档生成摘要,并将其存储为元数据。
核心实现:
- 摘要模板:支持自定义摘要生成模板。
- 参数解析:
chatModel:用于生成摘要的 AI 模型。summaryTypes:指定生成摘要的类型(如当前文档摘要、前文档摘要、后文档摘要)。summaryTemplate:自定义摘要生成模板。
使用示例:
高级技巧:
- 上下文感知摘要:结合前后文档内容生成上下文感知的摘要。
- 多风格支持:通过模板生成不同风格的摘要(如专业风格、通俗风格)。
效果:
- 快速定位核心内容:摘要信息帮助用户快速理解文档主题。
- 提升检索效率:摘要作为元数据可加速文档检索。
1.1.4 KeywordMetadataEnricher:关键词提取
功能描述
KeywordMetadataEnricher 从文档内容中提取关键词,并将其添加到元数据中。
核心实现:
- 关键词数量:支持指定提取的关键词数量。
- 参数解析:
chatModel:用于提取关键词的 AI 模型。keywordCount:指定提取的关键词数量。
使用示例:
高级技巧:
- 自定义关键词:通过提示词模板自定义关键词提取逻辑。
- 多语言支持:结合翻译模型提取多语言关键词。
效果:
- 提升文档可检索性:关键词作为元数据可提高文档检索精度。
- 支持文档分类:关键词可用于文档的自动分类和标签生成。
1.2 高级功能与组合使用
1.2.1 组合多个转换器
通过 ChainingDocumentTransformer,可以将多个 DocumentTransformer 实现类组合在一起,形成强大的转换流水线。
使用示例:
效果:
- 流水线处理:文档依次经过格式化、分块和摘要生成,最终输出标准化的文档集合。
- 灵活性:支持按需组合不同的转换器,适应多样化需求。
1.2.2 并行处理
利用 ParallelDocumentTransformer,可以加速大规模文档转换任务。
使用示例:
效果:
- 性能提升:多线程处理显著减少文档转换时间。
- 资源优化:合理利用 CPU 资源,提高系统吞吐量。
二、Spring AI 中的 RAG(检索增强生成)
RAG 是 Spring AI 的核心模块之一,通过检索相关文档并结合生成模型,提供精准的回答。以下将详细解析 RAG 的核心组件及其使用方法。
以下类图展示了 ETL 核心接口与实现类的关系架构。
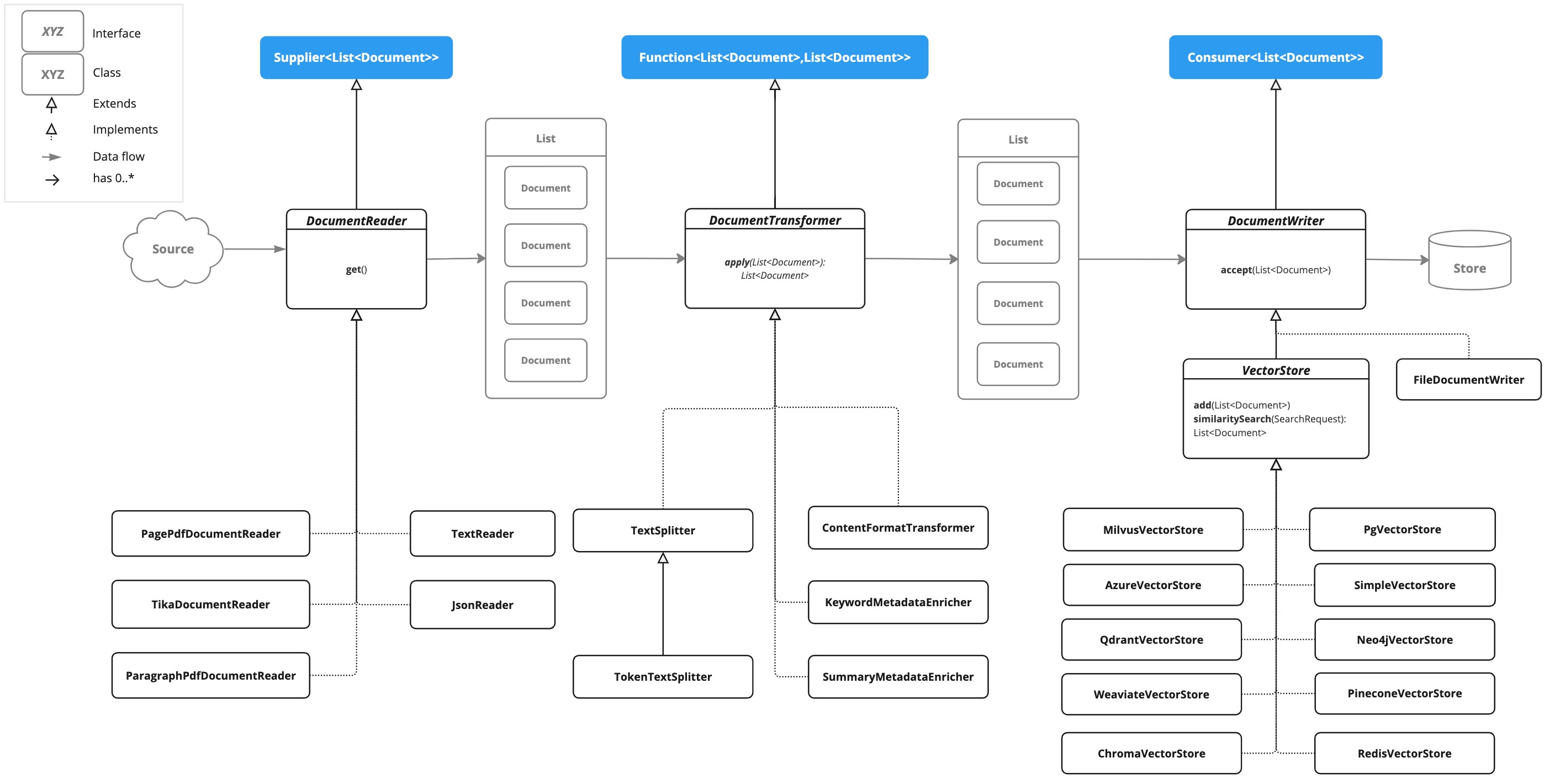
2.1 RAG 的核心组件
2.1.1 QuestionAnswerAdvisor
功能描述
QuestionAnswerAdvisor 是一个开箱即用的 Advisor,用于执行检索增强生成(RAG)。它通过查询向量数据库获取与用户问题相关的文档,并将这些文档作为上下文提供给 AI 模型。
核心参数:
vectorStore:向量数据库实例,用于存储和检索文档。
searchRequest:检索配置,包括相似度阈值、返回结果数量等。
使用示例:
高级技巧:
- 动态过滤器:通过
FILTER_EXPRESSION参数动态更新检索过滤条件。
- 自定义模板:使用
promptTemplate方法自定义上下文与用户查询的合并逻辑。
效果:
- 精准回答:基于检索到的文档生成精准的回答。
- 上下文增强:附加的文档上下文帮助模型生成更准确的内容。
2.1.2 RetrievalAugmentationAdvisor
功能描述
RetrievalAugmentationAdvisor 是一个更灵活的 Advisor,支持构建自定义 RAG 流程。它集成了文档检索和查询增强功能。
核心参数:
documentRetriever:文档检索器,用于从向量数据库检索文档。
queryAugmenter:查询增强器,用于处理用户查询并生成增强后的查询。
使用示例:
高级技巧:
- 多查询扩展:结合 MultiQueryExpander 生成多个查询变体,提高检索召回率。
- 查询重写:使用 RewriteQueryTransformer 优化查询结构,提升检索精度。
效果:
- 自动化流程:无缝集成文档检索和查询处理,简化开发工作。
- 智能回答:基于增强后的查询生成更智能的回答。
2.1.3 ContextualQueryAugmenter
功能描述
ContextualQueryAugmenter 用于增强用户查询,通过附加检索到的文档内容生成更丰富的查询上下文。
核心参数:
allowEmptyContext:是否允许空上下文查询。
maxTokens:查询上下文的最大 Token 数量。
temperature:控制查询扩展的创造性。
使用示例:
高级技巧:
- 上下文感知:结合历史对话生成上下文感知的查询。
- 多轮对话支持:在多轮对话中动态更新查询上下文。
效果:
- 增强上下文:生成的查询包含更丰富的上下文信息,帮助模型生成更准确的回答。
- 对话连贯性:保持多轮对话的连贯性,提升用户体验。
2.1.4 VectorStoreDocumentRetriever
功能描述
VectorStoreDocumentRetriever 用于从向量数据库检索与查询语义相似的文档。
核心参数:
vectorStore:向量数据库实例。
similarityThreshold:文档匹配的最低相似度阈值。
topK:返回的文档数量。
filterExpression:基于元数据的过滤条件。
使用示例:
高级技巧:
- 复杂过滤:使用 FilterExpressionBuilder 构建复杂的过滤条件。
- 动态调整:根据查询动态调整相似度阈值和返回结果数量。
效果:
- 精准检索:基于相似度和元数据过滤返回最相关的文档。
- 高效性:快速从大规模文档集合中定位目标文档。
2.2 RAG 的高级技巧与优化策略
2.2.1 多查询扩展与重写
通过结合 MultiQueryExpander 和 RewriteQueryTransformer,可以显著提升检索的召回率和精度。
使用示例:
效果:
- 提高召回率:多查询扩展生成多个相关查询,增加检索结果的覆盖面。
- 提升精度:查询重写优化查询结构,使检索结果更精准。
2.2.2 上下文感知查询
在多轮对话中,利用 CompressionQueryTransformer 处理带有上下文的查询,消除歧义并提高回答的准确性。
使用示例:
效果:
- 消除歧义:将模糊的查询转换为明确的查询(如 "What is the capital of Germany?")。
- 对话连贯性:保持多轮对话的连贯性,提升用户体验。
2.2.3 文档合并与去重
使用 ConcatenationDocumentJoiner 合并来自多个查询或数据源的文档,并去除重复内容。
使用示例:
效果:
- 统一文档集合:将多个来源的文档合并为一个统一的文档集合。
- 去重:自动去除重复文档,避免冗余信息。
2.2.4 错误处理与边界情况
通过配置 ContextualQueryAugmenter 和合理的异常处理机制,可以优雅地处理文档未找到或相似度过低的情况。
使用示例:
效果:
- 友好提示:当未找到相关文档时,返回友好的提示信息。
- 引导用户:引导用户提供更多上下文信息,以生成更准确的回答。
2.3 RAG 的性能优化策略
2.3.1 向量存储优化
选择合适的向量存储方案,并根据数据规模优化存储配置。
使用示例:
优化建议:
- 内存存储:适用于小规模数据集的快速开发和测试。
- 分布式存储:使用 Redis 或 MongoDB 等分布式存储方案,支持大规模数据集。
2.3.2 检索器配置优化
通过合理配置相似度阈值和返回结果数量,优化检索性能。
使用示例:
优化建议:
- 动态调整阈值:根据查询类型动态调整相似度阈值。
- 限制结果数量:控制返回结果数量,避免过多不相关文档。
2.3.3 缓存机制
对频繁访问的文档启用缓存,减少重复计算和检索开销。
使用示例:
优化建议:
- 合理设置缓存大小:根据内存资源和文档访问频率设置缓存大小。
- 缓存失效策略:定期清理过期缓存,确保数据新鲜度。
三、实战案例:构建智能文档检索系统
以下是一个完整的实战案例,展示如何使用 DocumentTransformer 和 RAG 模块构建智能文档检索系统。
3.1 配置类
3.2 处理流程
3.3 检索增强
3.4 高级功能集成
多查询扩展与重写结合:
上下文感知查询:
3.5 完整高级检索
四、总结
Spring AI 的 DocumentTransformer 和 RAG 模块提供了强大的工具集,帮助开发者构建高效的文档处理和检索系统。通过合理选择和配置这些组件,可以显著提升文档处理效率和检索精度。
- DocumentTransformer:通过多样化的转换功能(如分块、格式化、摘要生成、关键词提取)确保数据以最优格式进入后续流程。
- RAG 模块:通过检索增强生成技术,结合文档检索和生成模型,提供精准的回答。
高级技巧总结:
- 组合使用:通过 ChainingDocumentTransformer 组合多个转换器,形成强大的转换流水线。
- 并行处理:利用 ParallelDocumentTransformer 加速大规模文档转换任务。
- 多查询扩展:结合 MultiQueryExpander 和 RewriteQueryTransformer 提升检索召回率和精度。
- 上下文感知:利用 CompressionQueryTransformer 处理带有上下文的查询,消除歧义并提高回答的准确性。
- 文档合并:使用 ConcatenationDocumentJoiner 合并来自多个查询或数据源的文档,并去除重复内容。
通过深入理解和灵活运用这些组件,开发者可以构建高效、智能的文档处理和检索系统,满足复杂业务场景的需求。