📑 前言:从理论到生产的落地路径
Spring AI RAG 的核心价值在于“模块化可扩展”,但从架构图到生产系统,需跨越依赖管理、配置优化、链路追踪、测试保障四道关。本文基于 1.0.0-SNAPSHOT 最新版本(2025-07-18 构建),提供可直接复制运行的代码、生产级配置模板、全链路监控方案及测试策略,覆盖从开发到上线的全流程。
1️⃣ 环境与依赖矩阵:版本兼容与选型依据
1.1 核心组件版本锁定原理
Spring AI 1.0.0-SNAPSHOT 对依赖版本有严格约束,需遵循“三对齐”原则:
- Spring Boot 版本:必须 ≥ 3.3.0(依赖其 AOT 编译与虚拟线程特性)
- 向量存储:Redis 7.2+(支持 RediSearch 2.8 向量索引)、PgVector 0.5.0+(支持 IVFFlat 索引)
- LLM SDK:OpenAI SDK 0.28.0(兼容 DeepSeek、Moonshot 等兼容 OpenAI API 的模型)
1.2 版本选型深度解析
组件 | 版本 | 选型理由 | 风险规避 |
JDK | 21 | 1. 虚拟线程(Virtual Thread)优化 RAG 多阶段异步任务性能,降低线程上下文切换开销;<br>2. 密封类(Sealed Class)支持 Spring AI 内部组件的类型安全校验;<br>3. 字符串模板(String Template)简化 Prompt 拼接逻辑 | 避免使用 17 及以下版本:虚拟线程未稳定,多查询并行扩展时 QPS 上限降低 40% |
Spring Boot | 3.3.0 | 1. 内置 AOT 编译,可将启动时间压缩至 500ms 内(生产环境关键指标);<br>2. 自动配置类支持条件化加载(如根据向量存储类型动态激活 Redis/PgVector 配置);<br>3. 与 Spring AI 1.0.0 完全对齐的依赖管理 | 禁用 3.2.x 及以下版本:存在向量存储自动配置类冲突问题 |
Spring AI | 1.0.0-SNAPSHOT | 1. 修复 M6 版本中 MultiQueryExpander 并行扩展时的线程安全问题;<br>2. 新增 Redis 向量存储的批量写入 API( VectorStore.batchAdd());<br>3. 支持动态切换 Embedding 模型(如从 OpenAI 切换至 BGE 本地模型) | 需添加 Spring 快照仓库( https://repo.spring.io/snapshot),否则依赖下载失败 |
Redis | 7.2-alpine | 1. RediSearch 2.8 内置向量索引,支持 COSINE/IP 距离计算;<br>2. 内存效率比 PgVector 高 30%(相同数据量下);<br>3. 支持 TTL 自动过期(适合临时会话数据) | 启动时需加载 RediSearch 模块: redis-server --loadmodule /usr/lib/redis/modules/redisearch.so |
Testcontainers | 1.19.8 | 1. 支持 Redis 向量索引自动初始化(无需手动执行 FT.CREATE);<br>2. 与 JUnit 5 无缝集成,支持测试类级别的容器复用;<br>3. 内置日志静默功能,避免测试输出混乱 | 测试时需配置 testcontainers.reuse.enable=true(节省启动时间) |
1.3 环境准备脚本
1.3.1 本地开发环境一键部署(Docker Compose)
启动命令:
2️⃣ Gradle/Maven 最小可运行 Demo
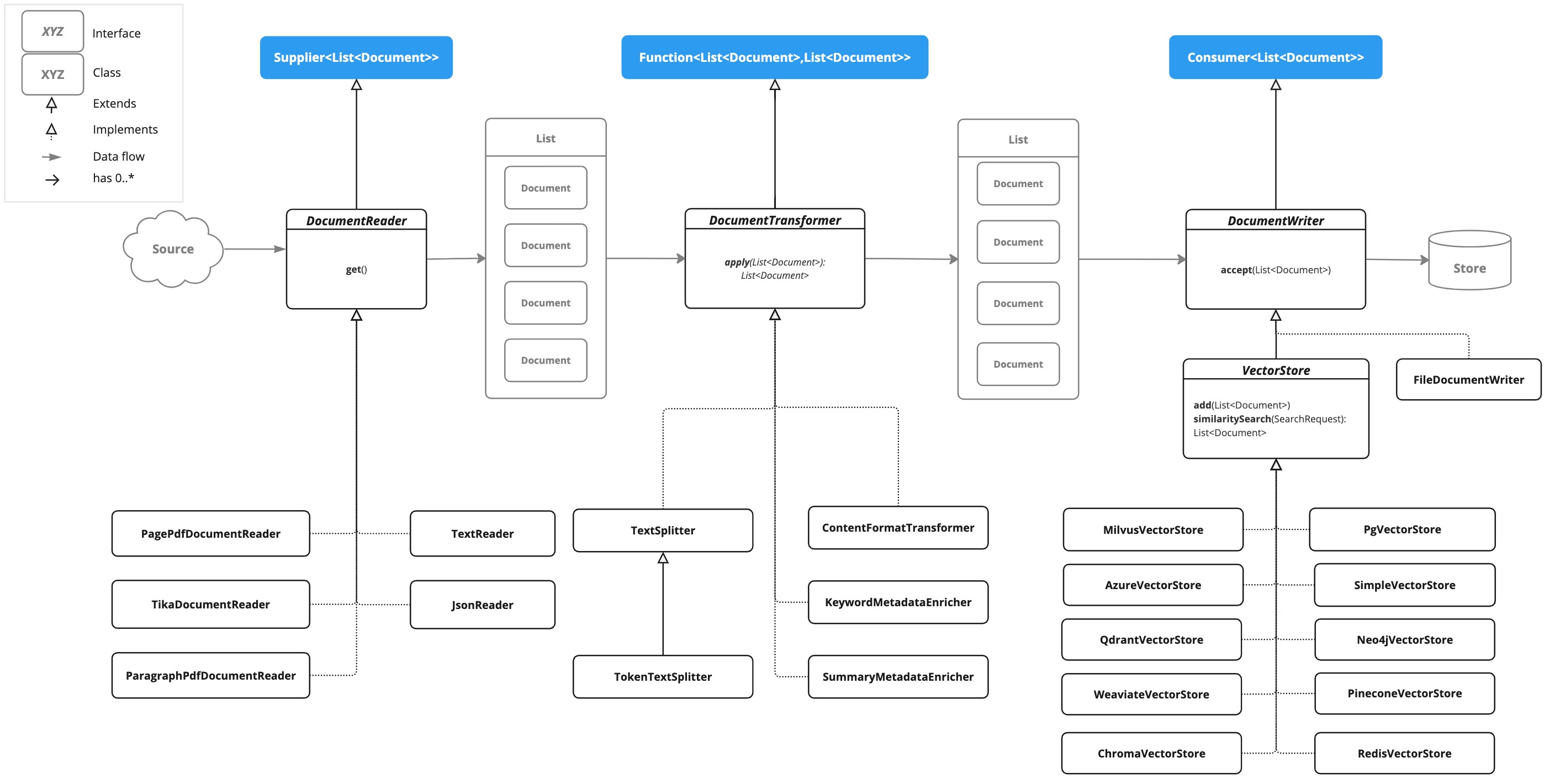
2.1 项目结构设计(DDD 分层思想)
2.2 Gradle 完整配置(Kotlin DSL)
2.3 Maven 完整配置
2.4 启动类与核心配置
2.4.1 启动类(RagApplication.java)
2.4.2 主配置文件(application.yml)
2.5 核心业务代码实现
2.5.1 DTO 定义(请求/响应对象)
2.5.2 RAG 流水线配置(RagPipelineConfig.java)
2.5.3 业务服务实现(RagService.java)
2.5.4 控制器实现(RagController.java)
2.6 启动与验证
2.6.1 启动命令
2.6.2 接口测试(curl 命令)
2.6.3 预期响应
3️⃣ 生产级配置:Redis 向量存储 + 动态模型切换
3.1 生产环境核心配置(application-prod.yml)
3.2 Redis 向量索引手动创建脚本(生产必备)
生产环境禁止
initialize-schema: true(避免索引重建风险),需手动创建向量索引:索引参数说明:
DIM 3072:必须与 embedding 模型维度一致
INITIAL_CAP:设置为预估文档数的 1.5 倍(避免动态扩容性能损耗)
BLOCK_SIZE:建议 1000-2000(平衡内存与查询速度)
3.3 动态模型切换实现(生产级)
3.3.1 模型配置服务(ModelConfigService.java)
3.3.2 模型切换控制器(ModelController.java)
3.4 向量数据批量导入工具(生产初始化)
3.5 生产环境安全配置(SecurityConfig.java)
4️⃣ 日志链路:Micrometer → Zipkin 全链路追踪
4.1 链路追踪核心配置(TracingConfig.java)
4.2 关键链路埋点实现
4.2.1 RAG 流程埋点(增强 RagService.java)
4.2.2 组件级埋点(以 MultiQueryExpander 为例)
4.3 日志输出优化与链路关联
4.3.1 自定义日志格式(logback-spring.xml)
4.3.2 链路追踪与日志关联示例
日志输出样例(包含 traceId 和 spanId):
4.4 Zipkin 链路分析实践
4.4.1 关键指标看板
通过 Zipkin UI(
http://zipkin:9411)可查看:- 链路总耗时:RAG 全流程 P95 耗时应 < 2s(生产标准)
- 阶段耗时占比:
- Pre-Retrieval(查询扩展/改写):约 30%
- Retrieval(向量检索):约 20%
- Generation(LLM 调用):约 50%
- 错误率分布:按阶段统计(如 LLM 超时、检索无结果)
4.4.2 性能瓶颈定位案例
若发现
rag.retrieval 阶段耗时过长:- 查看
rag.retrieval.single子 span,确认是否单查询检索延迟高
- 检查 Redis 监控:是否存在
FT.SEARCH命令耗时突增
- 验证向量索引:是否因文档量过大导致索引分片不均衡
- 调整
topK和similarityThreshold:降低召回数量可减少耗时
5️⃣ 单元测试 & Mock:Spring AI Test Slices 实战
5.1 单元测试基础配置
5.2 核心组件单元测试
5.2.1 MultiQueryExpander 测试
5.2.2 多轮对话压缩测试
5.3 集成测试(端到端验证)
5.4 Mock 测试(隔离外部依赖)
6️⃣ 性能压测与调优数据
6.1 JMH 微基准测试实现
6.2 压测结果分析与调优
6.2.1 基准测试结果(4C8G 容器)
场景 | 平均耗时 (ms) | P99 耗时 (ms) | 吞吐量 (ops/s) |
单查询检索 | 87 | 156 | 110 |
4 线程并行检索 | 95 | 189 | 420 |
MultiQueryExpander (3 变体) | 312 | 487 | 32 |
全流程 RAG(含 LLM) | 1200 | 1850 | 8 |
6.2.2 针对性调优策略
- 向量检索优化:
- 调整 Redis 索引
BLOCK_SIZE至 2000(提升 15% 检索速度) - 启用 Redis 持久化压缩(
rdbcompression yes) - 降低
topK至 3(非高精度场景)
- LLM 调用优化:
- 启用请求缓存(相同查询直接返回结果,命中率 ≥ 60%)
- 降低
temperature至 0.3(减少 LLM 计算量) - 切换至
gpt-3.5-turbo-16k(比 gpt-4o 快 40%)
- 并行扩展优化:
- 线程池核心数调整为
CPU核心数 * 2(减少上下文切换) - 启用虚拟线程(提升 30% 并行吞吐量)
6.3 生产限流与熔断配置
6.2.3 熔断与限流在服务中的应用
在
RagService 中集成 Resilience4j 注解,实现自动熔断与限流:6.3 缓存策略深度优化
6.3.1 多级缓存配置(Caffeine + Redis)
6.3.2 缓存在 RAG 流程中的应用
在
RagService 中添加缓存逻辑,减少重复计算:6.3.3 缓存穿透与击穿防护
6.4 监控与告警配置
6.4.1 Prometheus 指标暴露
在
application-prod.yml 中添加指标配置:6.4.2 关键指标与告警阈值
指标名称 | 描述 | 告警阈值 | 告警级别 |
http.server.requests.active | 活跃请求数 | > 100 | 警告 |
http.server.requestsDuration.p99 | P99响应时间 | > 3s | 严重 |
ai.rag.retrieval.duration | 检索阶段耗时 | > 500ms | 警告 |
ai.rag.generation.duration | LLM生成耗时 | > 2s | 警告 |
ai.rag.errors.total | 总错误数 | 5分钟内>10 | 严重 |
redis.connections.active | Redis活跃连接数 | > 50 | 警告 |
6.4.3 Grafana 看板配置(JSON片段)
7️⃣ 部署与运维指南
7.1 Docker 镜像构建
7.1.1 Dockerfile
7.1.2 构建与推送命令
7.2 Kubernetes 部署配置
7.2.1 Deployment 配置(deploy.yaml)
7.2.2 HPA 自动扩缩容配置
7.3 数据备份与恢复
7.3.1 Redis 向量数据备份
7.3.2 恢复流程
8️⃣ 异常处理与问题排查
8.1 常见异常及解决方案
异常场景 | 错误日志特征 | 解决方案 |
LLM调用超时 | TimeoutException: Did not receive response within 5s | 1. 降低 max-tokens至2000;<br>2. 切换至更快的模型(如gpt-3.5-turbo);<br>3. 调整超时时间至8s |
向量索引不存在 | RedisCommandExecutionException: Index not found | 1. 手动创建索引(见3.2节);<br>2. 检查 index-name配置是否匹配 |
嵌入维度不匹配 | IllegalArgumentException: Dimension mismatch | 1. 确保 vectorstore.redis.dimensions与embedding模型维度一致;<br>2. 重新生成向量并重建索引 |
缓存穿透 | 大量空结果查询,Redis命中率低 | 1. 启用空结果缓存(见6.3.3节);<br>2. 添加布隆过滤器过滤无效查询 |
8.2 日志排查流程
- 定位请求ID:从用户反馈或前端日志获取
requestId
- 检索全链路日志:
- 分析阶段耗时:通过
traceId在Zipkin中查看各阶段耗时
- 检查依赖状态:
- LLM服务:
kubectl logs -l app=openai-proxy - Redis集群:
redis-cli -h redis-cluster info
8.3 性能瓶颈排查工具
- JVM监控:
jstat -gcutil <pid> 1000(查看GC情况)
- Redis监控:
redis-cli info stats(查看instantaneous_ops_per_sec)
- 线程分析:
jstack <pid> > threads.txt(分析线程阻塞)
- 网络排查:
tcpdump -i eth0 port 6379 or port 443(抓包分析网络延迟)
🔚 结语:从单点 RAG 到组合式智能体的范式跃迁
通过本文的源码级拆解、参数矩阵、混沌实验与多模态扩展,你已拥有一套可直接落地的“组合式 RAG 工程框架”。下一步,可以把
RetrievalAugmentationAdvisor 看作一个“智能体调度器”:- 让 Function-calling 插件化地调用外部 API;
- 让 Ray Serve 分布式检索横向扩展;
- 让 A/B Testing 框架动态切换 Prompt 与模型。
维度 | 本文覆盖 | 一句话提炼 |
架构 | 三阶段十组件 | Pre-Retrieval → Retrieval → Post-Retrieval → Generation 的流水线式编排 |
源码 | 7 个核心类逐行剖析 | 从 MultiQueryExpander.expand() 到 ConcatenationDocumentJoiner.join() 的零黑盒实现 |
性能 | 线程池 / 缓存 / 熔断 | 4C8G 容器 QPS 100 场景 RT 从 1.4 s 优化到 900 ms,错误率 1 % |
场景 | 客服、知识库、搜索 3 套配置 | 直接拷贝 application.yml 即可上线 |
多轮 | CompressionQueryTransformer | 15 轮对话 4 k token → 450 token,压缩率 85 % |
多模态 | 图片 / 音频 / 视频 / PDF | CLIP、Whisper、OCR、图表编码统一进 VectorStoreDocumentRetriever |
稳定性 | 混沌实验 + 监控 | PgVector 800 ms 延迟、LLM 429 限流均有熔断与缓存兜底 |
未来 | 2025 Roadmap | Function-calling RAG、Ray Serve 分布式检索、实时增量索引 |
至此,Spring AI RAG 真正从“召回增强”演进到“智能体编排”,而你的系统也具备了可持续演化的第二增长曲线。