
前言
在前面一篇中提到了方法的调用,方法在类加载阶段会由符号引用替换实际引用或者方法表的索引。Java 的类加载机制又是怎么样的呢?这里聊一个小插曲,我记得我刚毕业那会去面中兴,基础的问题都回答的挺好的但是最后面试官问了我这个问题,Java 虚拟机是怎么加载一个类的?我当时脑子懵了,对象怎么加载到内存?对象是 new 出来的的啊,还要加载?我也对这块不太了解,然后面试官也就没深了问。但是现在看来,如果是进阶 Java 的话这是一个基础不能在基础的问题了。类加载了这还不算完,Java 的类是怎么保存的,我相信很多朋友会回答存放在堆里,那其他特殊的类型呢 例如 String 类型又是怎么存储的呢?我们在内存溢出的时候,对象怎么就把我们的堆给堆满了,每个对象占了多大的空间呢?请朋友们慢慢往下看。
类加载机制
想要知道一处的细节不如先鸟瞰全局,先了解类的声明周期是什么样的先有个大体的概念。在了解的类的声明周期之后才能更好的理解 JVM 是如何加载一个类的
类的生命周期

上面这张图是非常经典的一张图,类的生命周期有7个步骤,分别是
加载(Loading)、 验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸载(Unloading)。其中前五个部分(加载、验证、准备、解析、初始化)统称为类加载。加载
加载阶段也称作”装载”阶段。这个阶段主要的操作是,更具明确知道的 class 完全限定名,来获取类的二进制的 .class 文件
简单来说就是从文件系统/jar包中/或者网路中,任何地方存在的
class文件,如果没找到会抛出 NoClassDefFound 错误。加载阶段不会检查 classfile 的格式和语法问题,只是单纯的加载文件。类加载的整个阶段由 JVM 和类加载器(某一个)共同协作完成。验证
验证阶段也是链接过程的第一个阶段,这个阶段的操作逻辑也很简单,就是确保 class 文件的字节流数据是符合虚拟机要求的不会危害到虚拟机的安全。简单来说就是一些格式和语法的校验,在这个过程中可能会抛出
VerifyError,ClassFormatError 或 UnsupportedClassVersionError,注意这里排除的 Error 错误,Error 只有虚拟机无法正常执行了才会抛出的异常。验证也是链接的一部分,所以在这个部分 JVM 必须加载所有的超类和接口。如果发现类的层次结构有问题 JVM 会抛出
ClassCircularityError。而如果实现接口不是一个 interface,或者声明的超类不是一个 interface 也会抛出 IncompatibleClassChangeError。准备
在这个阶段会创建静态字段并为其初始化标准默认值(比如
null 或者 0),并分配方法表,及在方法区中分配这些方法的使用的内存空间。⚠️ 请注意,在这个阶段没有执行任何的 Java 代码。解析
然后JVM 会进入可选的解析符号引用阶段。也就是解析类文件里面的常量池,主要有下面四种:类或接口的解析、字段解析、类方法解析、接口方法解析。在解析阶段要做的是就是把符号引用解析为直接引用(相当于直接指向了实际的对象),如果有了直接引用,那么引用的目标对象一定在堆中。
初始化
如果直接赋值的静态字段被 final 所修饰,并且它的类型是基本类型或字符串时,那么该字段便会被 Java 编译器标记成常量值(ConstantValue),其初始化直接由 Java 虚拟机完成。除此之外的直接赋值操作,以及所有静态代码块中的代码则会被 Java 编译器置于同一方法中,并把它命名为
<clinit>。类只有在首次 “主动使用” 才能执行类的初始化。是 方法不是构造器,只有主动使用才会调用构造器方法。
类加载的最后一步是初始化,便是为标记为常量值的字段赋值,以及执行 < clinit > 方法的过程。Java 虚拟机会通过加锁来确保类的 < clinit > 方法仅被执行一次。
这个流程应该是每个Java 程序员都应该熟记于胸的,一开始我记忆这个部分也是硬着头皮记,也很容易忘。偶然有一天我在饭,突然发现这个类加载机制像做饭的过程。加载过程就像是买菜,类加载进入JVM 就像把菜买回家。然后菜买回来之后呢,要检查检查,确认买的菜都是对的,不然买错了或者什么漏买了就很尴尬了,这个过程呢就像类加载流程里面的验证,要检查字节码文件符合虚拟机要求不会危害到虚拟机安全。做饭也要需要准备,要洗菜择菜,就像我们的准备阶段为类准备分配内存空间。这部分结束了,我们就可以热锅开始做菜了。这个部分按照菜谱加入各种调味料,把各个食材混合在一起,就像解析,把各个符号引用替换为直接引用,让各个部分关联起来。然后我们菜就做好了,我们就可以装盘出锅了。这个部分就是类的初始化,经过这个部分之后,一个类就可以正常的使用了,我们也可以吃饭了,最后类使用完之后卸载,我们吃完了也就要洗碗了。哈哈是不是很像。加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载。买菜 -> 检查菜 -> 洗菜 -> 炒菜 -> 装盘 -> 吃饭 -> 洗碗。
类的加载时机
类并不是在虚拟机一启动就会全部加载进来,而是会
按需加载,那在什么时候才会加载目标类呢?- 当虚拟机启动时,初始化用户指定的主类。
- 当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类。
- 当遇到调用静态方法的指令时,初始化该静态方法所在的类。
- 当遇到访问静态字段的指令时,初始化该静态字段所在的类。
- 子类的初始化会触发父类的初始化。
- 如果一个接口定义了 deault 方法,那么直接实现偶着间接实现该接口的类初始化,会触发该接口的初始化。
- 使用反射 API 对某个类进行反射调用时,初始化这个类。
- 当初次调用 MethodHandler 实例,初始该 MethodHandler 指向的方法所在类。
这段代码是在著名的单例延迟初始化,只有当调用 Singleton.getInstance 时,程序才会访问 LazyHolder.INSTANCE,才会触发对 LazyHolder 的初始化(对应第 4 种情况),继而新建一个 Singleton 的实例。
类加载器机制
类的加载过程可以描述为”通过一个类的全限定名 a.b.c.xxx.XXClass 来获取此类的 Class 对象。这个过程由类加载器来完成。这样的好处在于,子类加载器可以复用父加载器加载的类。系统自带的加载器分为三种:
启动类加载器(BootstrapClassLoader)
扩展类加载器(ExtClassLoader)
应用类加载器(AppClassLoader)
一般启动类加载器是由 JVM 内部实现的,在 Java 的 API 里面是无法拿到了,是用 C++ 实现的,后面两种在 Oracle Hotspot JVM 中,都在 sun.misc.Lanucher 定义的,扩展类加载器和应用类加载器一般都继承自
URLClassLoader 类,这个类也默实现了从不同的源来加载 class 字节码换成的 Class 的方法。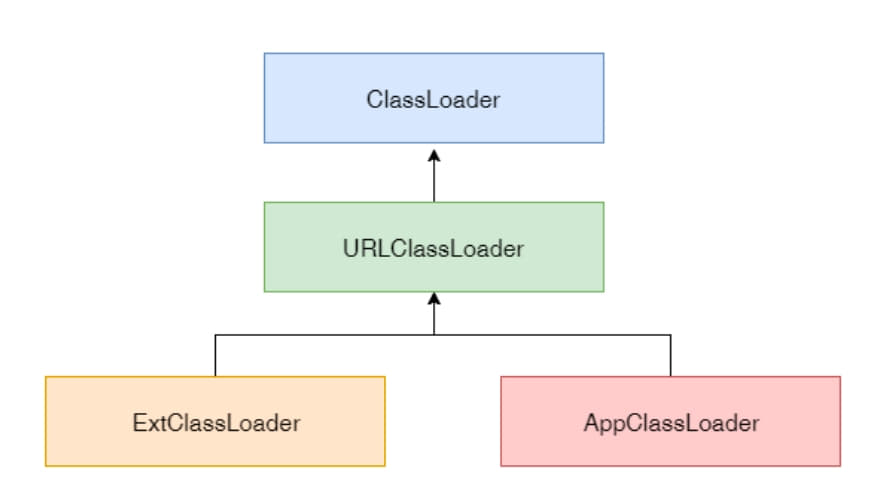
- 启动类加载器(bootstrap class loader):它用来加载 Java 的核心类,用原生的 C++ 实现并不继承自 java.lang.Classloader。负责加载 JDK 中
jre/lib/rt.jar中的所有 class。可以把它看作是 JVM 自带的,同时我们也无法获取它的引用。
- 扩展类加载器(extensions class loader):它用来加载
lib/ext或者由系统路径java.ext.dirs指定的目录中的 Jar 包中的类。
- 应用类加载器(application class loader):它负责在 JVM 启动时加载来自
Java 命令 -classpath或者cp或者指定系统路径java.class.path系统属性指定的 jar 包和类路径。 可以通过ClassLoader.getSystemClassLoader()来获取类应用加载器。
用户可以自定义类加载器,如果自定义类加载器,自定义的类加载器的应该以应用加载器作为父类。下面就是一个自定类加载器。
类加载器有三个特点:
双亲委派:大名鼎鼎的双亲委派其实很简单,也没有什么所谓的双亲,就是优先给父类加载器加载,如果父类加载不了再自己来加载。例如 String 类型,appClassLoader 看到了不加载,给 extClassLoader,extClassLoader 也不加载,给bootstrapClassLoader 加载,bootstrapClassLoader 一看 java.lang.String 是在 rt 包里的就给加载了。这也不是说加载器懒,这样可以保证,某一个类每次都能被特定的某个加载器加载。
负责依赖:如果一个加载器在加载某个类的时候,发现这个类依赖的另外几个类或者接口,也会去是这尝试加载这些依赖。
缓存加载:为了提高效率避免重复加载,一旦某个类被一个加载器加载,那么它就会缓存这个加载结果,不会重复加载。这也是双亲委派的目的。
对象内存布局
前面的部分我们聊到了,Java 对象是如何加载一个类的,但是我们要真正的使用一个对象,需要根据我们加载的类去创建一个对象。那创建的过程是怎么样的呢?
对象创建
我想起来一个段子,把大象放进冰箱需要几步?需要三步!打开冰箱门,把大象放进冰箱,把门关上。其实我们的 Java 创建对象过程也可以大致分为三步,申请内存 —> 初始化数据(代码块和构造)-> 关联引用。
构建对象(申请空间),这个过程首先线程会申请一个栈空间,并且生成栈帧然后执行 new 操作。线程会根据加载的类信息申请一块内存构建对象,并且为成员变量赋默认值。
对象初始化,这个部分就是执行 {} 代码块和构造方法了。
关联引用,我们创建的对象的引用是在栈上面,然而我们创建的对象是在堆中,最后一步就是把栈上的对象引用指向堆中的地址。
打开冰箱 = 申请空间,放入大象 = 对象初始化, 关联引用 = 关上冰箱门
对象在内存的布局
我们现在创建好了一个对象,难道一个对象在堆中存的就真的是一堆变量数据就没有其他的东西吗?
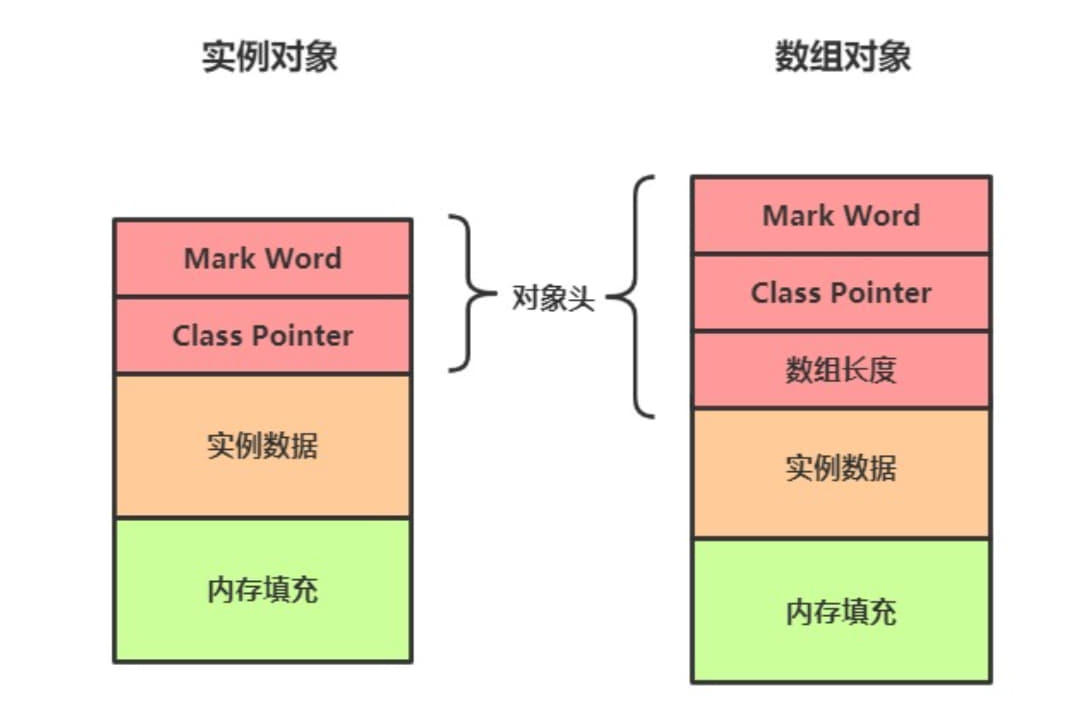
对象在内存的中并不只有实例的数据,而是包含三个部分,
对象头、实例数据、内存填充。- 对象头:按照实例对象的不同,对象头也有不同,主要的就是包含
Mark word,class pointer,数组对象还包括数组长度。MarkWord 里面包含有对象的哈希码,锁信息,GC 等信息。ClassPointer 这个很明显,这是一个指针指向方法区的 Class 对象 ,在数组实例中还要记录数组的长度,在 64 位的系统中markWord占8个字节,如果开启指针压缩,这个大小可以压缩到4个字节,也就是如果不开启指针压缩的话,再加上 class pointer 4 个字节,实例对象头 12 个字节,数组对象头占 16 个字节,开启指针压缩后,实例对象 对象头8个字节,数组对象对象头 12 个字节。
对象头 不开启指针压缩 实例 12 字节,数组 16 字节,开启指针压缩 实例 8 字节,数组 12 字节。
- 实例数据:这个很好理解就是类实例中的数据。
- 内存对齐:我们的 CPU 寄存器的位数都是 8 的倍数,所以为了方便 CPU 寄存器高效寻址,64 位 JVM 要求 Java 对象地址要按照 8 字节对齐。这个部分做数据填充保证 8 字节对齐。
⚠️这里有个小知识点,Java 实例被 GC 之后,对象的 Hash 码会变码?那栈中的引用地址会变化吗?我们都知道 Java 对象的 Hash 码和对象地址有关系。如果一个对象被 GC 过后还存活的话,如果在 young 区,那地址大概率会发生变化,那Hash 码是不是也不一样呢?我们通过实验可以很容易验证这个问题,Hash 码不会发生变化,但是地址会发生变化,这是怎么做到的?来,抬头往上看,对象头中是不是有个哈希码信息。在第一次调用对象 hashCode 方法,就会把 hashCode 存在这里,后面的 hashCode 直接来这里取就好了。
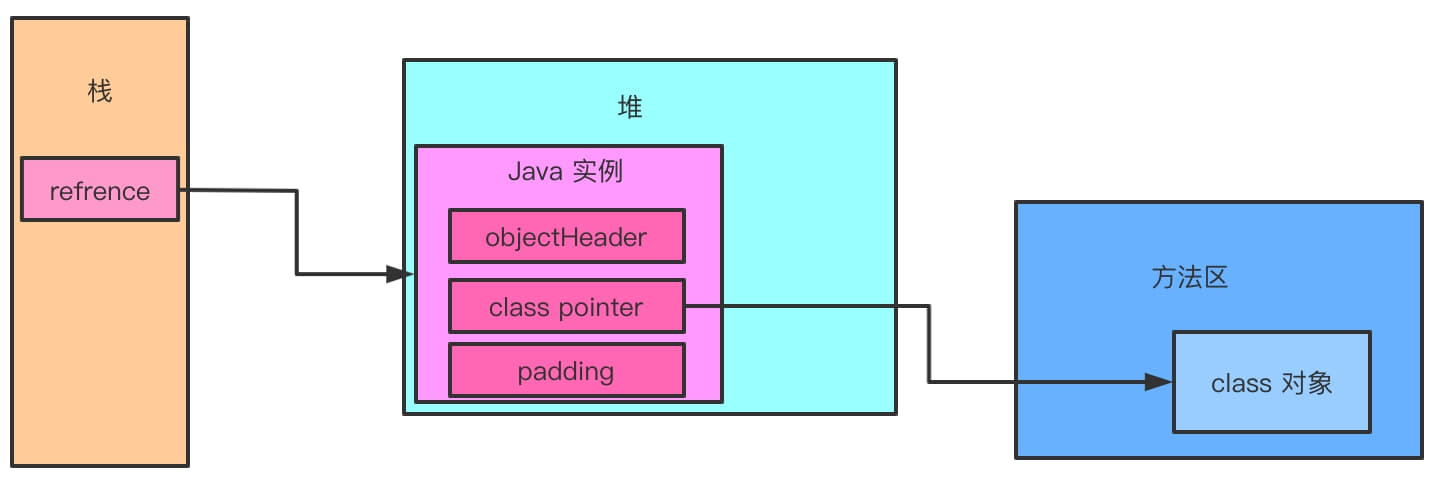
整体的大致的对象存储布局就是酱婶儿的。
JOL 实践
什么是 JOL ?JOL (Java object layout)Java 对象内存布局,是 openjdk 给我们提供了一个工具包,可以用来获取对象的信息和虚拟机的信息 。我们来引入下 jol-core 的依赖。
主要会用到的方法:
ClassLayout.parseInstance(object).toPrintable():查看对象内部信息。
GraphLayout.parseInstance(object).toPrintable():查看对象外部信息,包括引用的对象。
GraphLayout.parseInstance(object).totalSize():查看对象总大小。
我们创建一个普通对象,空对象开开胃。
这个对象一个成员变量都没有,那么一个 A 实例占用几个字节呢?我们没有开启指针压缩,markWord 8 个字节, class pointer 4 个字节,8 + 4 = 12 然后 8 个字节对齐 也就是 16 个字节。我们使用 JOL 打印出来看看。
那么一个数组对象呢?我们前面提到数组对象实例对象头中会多一个
length field用来存数组的长度。按照我们的计算逻辑,我们没开启指针压缩,markWord 占用 8 个字节,classPonter 占 4 个字节,因为数数组对象多一个 lengthField 4 个字节。也就是 4 + 4 + 8 = 16,刚好对齐 16 个字节。真的是这样吗?没落下什么吗?实际的实例的大小是56,仔细看,打印结果的第13行,多了 40 个字节,这是啥呢?没错是我们长度为10的数组内容,一个 int 类型四个字节就是 40 个字节。所以最终的大小就是 16 + 40 = 56 刚好也不用对齐~。
再来看一个例子,一个稍微正常点的对象 B。
B 对象包含,一个 String,一个int 和一个 boolean,我们根据之前的经验可以推出 没有开启指针压缩,对象头12个字节,String 是一个引用4个字节,int 4 个字节,boolean 一个字节,所以 12 + 4 + 4 + 1 = 21 个字节,然后内存对齐,实例大小 24 个字节。
没毛病,最终实例大小 24 个字节。
总结
这一小节呢,我们从类的生命周期入手深入了解了类的加载过程和实例在内存中的对象布局,类的生命周期分为 加载,验证,准备,解析,初始化,使用、卸载。过程可以类比做菜的过程。其中类并不是在 JVM 启动时全部加载而是按需加载的。接下来我们介绍了类加载器,有启动类加载器,拓展类加载器和应用类加载器。他们采用双亲委派的方式,所谓的双亲委派就是先由父类加载,父类如果加载在不了再由子类加载,这样可以保证每个类每次都由某个特定的类加载器加载。我们还可以自定义类加载实现加载逻辑的自定义化,这个自定义类加载器的父类是应用类加载器。聊完类的加载,我们探讨了实例的内存布局,一个实例分为对象头,实例数据和填充数据这三个部分,其中对象头又包括 markWord、klassPointer和数组对象特有的 lengthField,对象头的大小受是否开启指针压缩有关。最后我们使用 openJDK 提供的JOL工具验证了我们的理论对象布局理论。这是JVM基础正式篇的最后一小节,接下来我们会一起探讨 JVM 的内存,GC 和 高效编译的部分。接下来的 JVM 会更加精彩,我们一起来看看,有了这些东西 JVM 会玩出些啥不一样的。哈哈,晚安~











