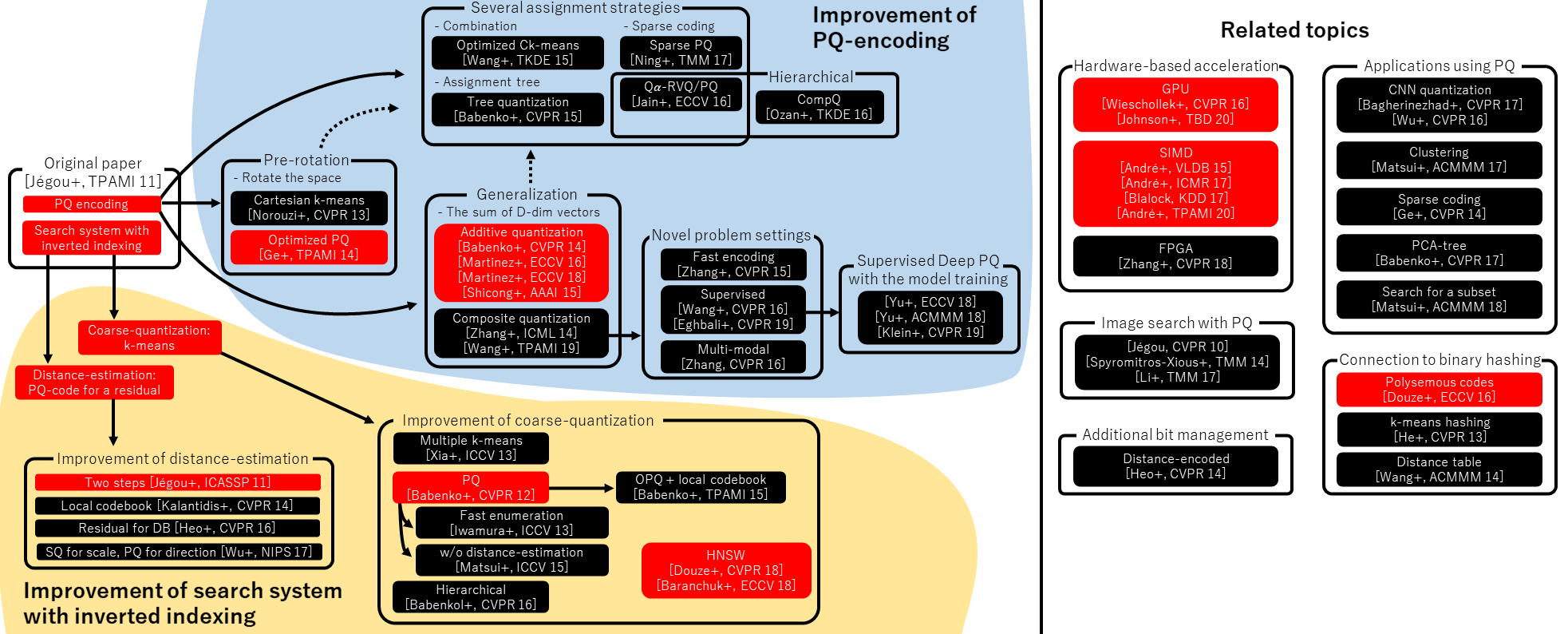
你刷抖音时,系统能秒推同款 BGM;用 ChatGPT 查资料时,它能精准调取知识库内容;电商平台给你推荐 “猜你喜欢” 的商品 —— 这些看似神奇的体验,背后都藏着同一个 “幕后英雄”:向量数据库。
它能把图片、文本、音频变成高维向量,再用精妙算法快速找到相似结果。
但向量算法有哪些?HNSW 和 IVF_PQ 怎么选?Milvus、PgVector、Redis 各自适合啥场景?
这篇文章从数学公式拆解到数据库选型,用轻松诙谐的语言讲透向量数据库的核心逻辑,不管你是 AI 开发者、数据工程师还是技术爱好者,都能从原理到落地,一次性搞定高维数据的 “存储与检索” 难题。
一、向量搜索算法:从数学公式到"找相似"的底层逻辑
如果你问向量数据库最核心的能力是什么?答案一定是快速找到"相似向量"。就像在人群中找和你长得像的人,关键是怎么定义"像"(数学公式),以及怎么高效找(算法思路)。这部分我们把核心算法的公式、设计思路掰开揉碎,用"人话+公式"讲清楚。
(一)精确搜索:kNN算法——数学上的"老实人",笨但准
1. 核心公式:向量距离的三种"尺子"
kNN(k-最近邻)的逻辑简单到可爱:计算目标向量和所有向量的距离,排个序取前k个。但"距离"怎么算?这三把"尺子"你必须认识:
- 欧几里得距离(Euclidean Distance)
最直观的"直线距离",比如2D空间里两点和的距离就是。扩展到n维向量和,公式是:
优点是直观,缺点是计算时要开平方,略费CPU。适合图像、视频等注重"绝对差异"的场景。
- 余弦相似度(Cosine Similarity)
不管向量"长度",只看"方向"相似性。比如两篇文章,哪怕字数不同,只要主题相似,余弦相似度就高。公式是:
结果范围[-1,1],越接近1越相似。实际用的时候常转成"余弦距离",方便和其他距离比较。适合文本、语义搜索等场景。
- 曼哈顿距离(Manhattan Distance)
像在格子里走路,只能横平竖直,算的是"绝对差值之和"。公式:
没有开平方运算,计算速度比欧几里得快,适合高维稀疏向量(比如用户点击行为向量,大部分维度是0)。
2. 设计思路:"挨个敲门"的暴力美学
kNN的逻辑就像你在小区找"和你身高最接近的3个人":挨家挨户敲门量身高,记下来排序,取前3名。优点是100%精确,缺点是数据量大了就歇菜——100万条数据就要算100万次距离,CPU直接原地"冒烟"。
3. 适用场景:小数据+"错不起"的场景
当数据量小于10万条时,kNN性能完全能打。比如医疗影像比对(漏检可能出人命)、金融黑名单匹配(错配损失百万)、实验室小样本研究(数据量本来就不大),这些场景宁慢也要准,kNN就是最佳选择。
(二)近似搜索:ANN家族——用"一点点不准"换"百倍速度"
当数据量突破百万级,kNN就成了"龟速选手"。这时候ANN(近似最近邻)算法登场,它们的核心思路是:不找绝对最近的,只找"差不多近"的,但速度能快100-1000倍。就像找咖啡店不用尝遍全城,看点评Top10就行,效率高多了。
1. HNSW:图结构的"六边形战士",快又准
(1)核心公式:层选择与邻居构建
HNSW(分层可导航小世界)的精髓是"多层图",关键公式决定了图的"长相":
- 层选择概率:每个向量被分配到第$l$层的概率,其中$m$是衰减因子(通常$m=10$)。简单说,越高层的向量越少,像地铁的"快线",站少但跑的远。
- 邻居筛选公式:构建时给每个向量选邻居,用动态半径$r$控制:,其中是当前向量,是候选邻居。保证只留距离近的"优质邻居",图结构更高效。
(2)设计思路:"地铁换乘"式搜索
HNSW的架构像城市地铁系统:
- 高层稀疏图:少数向量组成"快线",比如100条向量里选1条在最高层,负责快速定位大致区域;
- 中层过渡图:密度中等,像"地铁干线",负责从快线换乘到慢线;
- 低层稠密图:所有向量都在这层,像"小区支线",每个向量和周围16个相似向量连边,负责精确查找。
查询时从最高层开始,像坐快线到目标区域,再转干线、支线,最后步行到"家门口"。这种"分层跳转"比暴力遍历快100倍以上,召回率还能保持95%-99%。
(3)核心参数:调参=调"地铁线路密度"
- (每层邻居数):默认16,像地铁每条线的站点数。越大,图越密,精度越高但内存越大(内存紧张就降到8);
- (建图候选池):默认200,建图时探索的邻居数量。越大图质量越好,建图越慢(追求精度可提到400);
- (查询候选池):默认100,查询时探索的范围。越大结果越准,查询越慢(线上常用50-100)。
性能公式:查询时间($N$是数据量),所以是平衡精度和速度的关键。
2. IVF_PQ:"分区+压缩"的性价比之王,省内存小能手
(1)核心公式:聚类分桶与向量压缩
IVF_PQ是"倒排文件(IVF)+乘积量化(PQ)"的组合拳,两步加速:
- IVF聚类分桶:用k-means算法把向量分到个"簇"(桶),每个簇中心。向量$x$的所属簇,通过倒排表记录"簇→向量列表"。查询时只查距离最近的个簇,排除90%无关向量。
- PQ压缩量化:把向量拆成个子向量,每个子向量用"码本"(含个码字)压缩:。压缩后向量从维变成个整数索引,存储空间减少90%+。
量化误差公式:,通过优化码本可把误差控制在5%以内,精度损失很小。
(2)设计思路:"快递分拣+打包"的高效逻辑
IVF_PQ的思路像快递处理流程:
- IVF分桶:全国快递先按省份分仓(个簇),你查"北京的快递"就不用看上海的仓;
- PQ打包:每个省份的快递再用标准箱子打包(子向量压缩),体积变小,运输和查找都快。
比如768维向量,拆成8个96维子向量,每个用256个码字(8位)量化,最终只需8×8=64位存储,比原始向量省99%空间!查询时先找目标省份(簇),再在省内查打包好的快递(压缩向量),速度飞起。
(3)核心参数:调参=调"分仓和打包方式"
- (簇数量):推荐(为数据量),比如100万数据设1000。太少分不细,太多仓太散;
- (探测簇数):默认10,查几个仓。越大召回越高但速度越慢(线上常用16-64);
- (子向量数):推荐(64是每个子向量维度),768维设12,512维设8。$m$太大压缩损失多,太小省空间效果差。
3. LSH:哈希映射的"概率玩家",快但偶尔"送错快递"
(1)核心公式:局部敏感哈希函数
LSH的关键是设计"相似向量容易撞哈希"的函数。以余弦相似度为例,哈希函数:
其中$v$是随机单位向量,是符号函数(正为1,负为0)。对向量$x$生成$k$个这样的哈希值,组成二进制码。相似向量的与相同的概率高,就像相似物品贴相同标签。
(2)设计思路:"哈希桶+多表查询"
LSH像给物品贴标签分桶:
- 建个哈希表(每套独立标签规则),每个表把向量分到个桶;
- 查询时算查询向量的标签,只在相同桶里找候选;
- 合并个表的结果,漏检率随增加指数下降(时漏检率极低)。
优点是查询时间接近,极快;缺点是召回率波动大(80%-90%),像快递偶尔送错,但胜在便宜省空间。
(3)核心参数:调参=调"标签数量和精度"
- (哈希表数):推荐5-10,召回率(是相似向量碰撞概率);
- (每个表哈希函数数):推荐10-20,越大标签越细,桶越多但每个桶向量少。
4. Annoy:随机投影树的"多尺子"策略,Spotify的最爱
(1)核心公式:随机投影分割
Annoy(Approximate Nearest Neighbors Oh Yeah)通过随机投影构建二叉树,分割超平面由随机向量和阈值定义:对向量,若则左子树,否则右子树。多棵树结果合并:查询向量的邻居是所有树中距离最近的前个向量的交集。
(2)设计思路:"多把尺子分堆"
Annoy像用多把随机尺子给向量分类:
- 每棵树独立构建,递归分割向量空间,直到叶子节点向量数≤;
- 查询时每棵树推荐候选,最后综合投票,避免单棵树的随机性误差。
就像找相似音乐,用100把不同的"风格尺子"打分,最后取平均分最高的,比单把尺子靠谱。Spotify用它做音乐推荐,单机就能处理亿级歌曲向量。
(3)核心参数:调参=调"尺子数量"
- (树数量):默认10,越多召回越高但建图越慢(推荐50-100);
- (查询节点数):默认,控制查询范围,越大精度越高。
二、主流向量数据库深度解析:从架构到算法,选对不踩坑
向量数据库的核心是把算法落地成工程化系统,不同数据库的架构、算法支持和适用场景差异极大。以下按VectorStore接口实现列表,逐一拆解每个数据库的"内核",看完你就是选型专家。
(一)云原生托管型:零运维,开箱即用
1. Azure Vector Search
- 设计思路:Azure生态的"向量搜索打工人",主打"零运维+无缝集成"。把向量索引和全文检索、过滤功能捆在一起,支持"关键词+向量"混合搜,对Azure用户超友好。
- 核心算法公式: 仅支持HNSW近似搜索,距离度量用欧几里得/余弦/内积,参数自动优化(用户调不了太多,省心但少了点自由度)。
- 系统架构: 基于Azure云的分布式架构,分三层:索引服务(建向量索引)、查询服务(处理搜索请求)、存储服务(存向量和元数据)。自动扩缩容,你只管调用API,服务器扩容、故障转移都不用管。
- 优缺点: ✅ 优点:Azure全家桶无缝接(比如直接连OpenAI生成向量)、零运维、支持复杂过滤; ❌ 缺点:按查询量收费(长期用不便宜)、参数锁死(想调M值?不行)。
- 适用场景:微软系企业的知识库(如客户支持系统)、预算充足想省事儿的团队、需要快速上线的SaaS应用。
2. Pinecone Vector Store
- 设计思路:向量数据库界的"懒人福音",全托管SaaS,核心是"你别管技术,我来搞定一切"。自动选算法、调参数、扩服务器,连索引重建都自动做,堪称"向量搜索外卖"。
- 核心算法公式: 只支持HNSW(藏得很深,用户看不到公式),距离度量欧几里得/余弦/内积,参数完全黑盒优化(你甚至不知道M值是多少)。
- 系统架构: 云服务架构分控制平面(管集群和索引)、数据平面(存向量)、查询平面(处理搜索)。多副本存储,全球多区域部署,保证你在哪查都快。
- 优缺点: ✅ 优点:API极简(几行代码搞定)、零运维、动态增删向量不卡顿; ❌ 缺点:长期成本高(存10亿向量一年能买辆车)、想自定义算法?没门。
- 适用场景:创业公司MVP验证(没时间搭 infrastructure)、营销活动临时推荐系统(用完即删)、无专职运维的小团队。
(二)开源分布式型:灵活可控,大规模首选
1. Milvus Vector Store
- 设计思路:向量数据库界的"全能选手",云原生分布式架构,专为PB级数据设计。核心是"存算分离+水平扩展",算法支持最全面,你想要的它都有。
- 核心算法公式: 支持全套算法:
- 精确:FLAT(暴力kNN,公式就是欧几里得/余弦距离);
- 近似:HNSW(层选择概率)、IVF_PQ()、IVF_FLAT(无压缩版IVF)。
- 系统架构: 微服务架构,分工明确:
- Proxy:请求入口,像前台接待员,负责负载均衡;
- Data Node:数据保管员,存向量和元数据,支持持久化到S3/MinIO;
- Index Node:索引专家,建HNSW/IVF_PQ索引,还能开GPU加速;
- Query Node:搜索引擎,执行查询返回结果;
- Coordination:大管家,管元数据和集群调度。 数据分片存储,能从百万级轻松扩到十亿级。
- 优缺点: ✅ 优点:算法最全(想要啥索引都有)、分布式强(十亿级无压力)、支持GPU加速; ❌ 缺点:部署复杂(要起五六个组件)、小数据量用它像"杀鸡用牛刀"。
- 适用场景:互联网大厂推荐系统(十亿级用户行为向量)、安防人脸库(百万摄像头数据)、大规模企业知识库(千万级文档)。
2. Qdrant Vector Store
- 设计思路:开源界的"轻量黑马",主打"简单好用+可视化"。把复杂的分布式逻辑藏起来,单机部署一个二进制文件搞定,还送Web UI管理界面,对开发者超友好。
- 核心算法公式: 支持HNSW(默认)和LSH(哈希表数),距离度量欧几里得/余弦/曼哈顿,参数明明白白能调。
- 系统架构: 单体服务架构,包含内存索引层(HNSW/LSH)、持久化层(存磁盘)、API层(REST/gRPC)。集群模式用一致性哈希分片,小规模分布式也能扛。
- 优缺点: ✅ 优点:部署简单(一行命令启动)、Web UI直观(能看索引状态)、轻量省资源; ❌ 缺点:超大规模(十亿级)性能不如Milvus、集群功能待完善。
- 适用场景:中小知识库(十万到百万文档)、开发者本地调试、需要可视化管理的场景(运维能直观监控)。
(三)传统数据库扩展型:无缝集成现有生态
1. PgVector Store(PostgreSQL)
- 设计思路:PostgreSQL的"向量插件",核心是"SQL党狂喜"。把向量当成普通数据类型,用SQL语句查相似向量,不用学新语法,现有PostgreSQL集群直接升级。
- 核心算法公式: 支持:
- 精确:kNN(用
<->运算符,底层是欧几里得距离公式); - 近似:HNSW()、IVF_FLAT(),通过
CREATE INDEX语句配置。
- 系统架构:
完全寄生在PostgreSQL架构里,向量存在
vector类型字段,索引作为PostgreSQL二级索引(B-tree包着向量索引)。查询时SQL语句里嵌ORDER BY vec <-> query_vec,优化器自动走索引。
- 优缺点: ✅ 优点:零学习成本(会SQL就会用)、兼容PostgreSQL生态(ORM/事务/备份全支持)、轻量无额外部署; ❌ 缺点:维度上限2000(超了要拆表)、分布式能力弱(靠PostgreSQL分片,不如原生分布式)。
- 适用场景:已有PostgreSQL的企业(直接扩展功能)、中小知识库(几十万文档)、需要事务的场景(如金融产品推荐,向量更新要事务保证)。
2. MongoDB Atlas Vector Store
- 设计思路:文档数据库界的"向量扩展包",核心是"文档+向量"一体化。把向量存在BSON文档里,和文本、数值字段混存,查相似向量时还能加文档过滤条件。
- 核心算法公式:
支持HNSW近似搜索,距离公式欧几里得/余弦/内积,通过
vectorSearch索引配置,参数藏在JSON里。
- 系统架构:
基于MongoDB Atlas分布式架构,向量作为
vector字段存在文档中,索引分片存储在多个节点。查询用$vectorSearch聚合阶段,能和$match、$group等操作无缝结合。
- 优缺点: ✅ 优点:向量和业务数据同库(不用跨库查)、支持复杂文档结构、MongoDB用户零门槛; ❌ 缺点:向量性能不如专业数据库(毕竟主业是文档存储)、索引对写入性能有影响。
- 适用场景:已有MongoDB的企业(扩展向量功能)、用户画像+行为向量混合查询(如"找和该用户相似且活跃的用户")、产品描述相似推荐(文档里既有文字又有向量)。
3. Oracle Vector Store
- 设计思路:Oracle的"向量新军"(23c新增功能),核心是"企业级安全+向量搜索"。主打金融、医疗等对合规性要求高的场景,把向量塞进Oracle数据库,享受企业级加密、审计功能。
- 核心算法公式:
支持HNSW和kNN,距离公式欧几里得/余弦/内积,通过
VECTOR类型和VECTOR_INDEX索引配置,参数调优得用Oracle的"黑科技"工具。
- 系统架构:
向量作为新数据类型集成到Oracle存储引擎,索引利用Oracle的分区技术,支持跨节点分布。查询用SQL函数
VECTOR_DISTANCE,和其他Oracle功能(如PL/SQL)无缝结合。
- 优缺点: ✅ 优点:企业级安全(加密/审计)、强事务支持、Oracle生态无缝接; ❌ 缺点:贵(Oraclelicense懂的都懂)、向量功能较新(成熟度待验证)。
- 适用场景:金融风控(欺诈检测向量匹配)、医疗患者数据检索(合规要求高)、已有Oracle的大型企业(不想换数据库)。
(四)搜索引擎扩展型:向量+全文检索一体化
1. Elasticsearch Vector Store
- 设计思路:搜索引擎界的"向量兼职生",7.0+支持向量搜索,核心是"全文检索+向量"混合打。查文档时既能按关键词搜,又能按语义相似搜,适合日志、文本等混合场景。
- 核心算法公式:
支持HNSW(7.14+)和LSH,距离公式欧几里得/余弦/内积,通过
dense_vector字段和_knn_searchAPI实现。
- 系统架构:
基于ES分布式架构,向量存在文档的
dense_vector字段,索引分片存储在多个节点。查询时_knn_search和bool查询组合,既能搜相似向量,又能过滤文本条件。
- 优缺点: ✅ 优点:向量+全文无缝结合(查"人工智能"关键词+语义相似文档)、分布式成熟、支持复杂聚合; ❌ 缺点:向量性能不如专业数据库、高维向量内存占用大。
- 适用场景:已有ES集群的企业(扩展向量功能)、日志+向量混合分析(如异常检测)、文本语义搜索(结合全文检索)。
2. Typesense Vector Store
- 设计思路:轻量级搜索引擎的"向量小能手",核心是"简单+高性能"。API设计极简,部署一个二进制文件搞定,适合中小规模的"关键词+向量"混合搜索。
- 核心算法公式:
支持HNSW,距离公式欧几里得/余弦,参数通过
-hnsw-m和-hnsw-ef-construction配置,简单明了。
- 系统架构: 单体服务+集群模式(主从复制),向量和文本字段存在同一索引,内存中构建HNSW索引,定期持久化到磁盘。查询API支持向量搜索+关键词过滤,响应快。
- 优缺点: ✅ 优点:部署简单、查询延迟低、中小数据量性能好; ❌ 缺点:分布式能力弱(集群功能简单)、超大规模扛不住。
- 适用场景:中小网站商品搜索("手机"关键词+相似商品向量)、开发者本地调试、轻量级知识库。
(五)图数据库+向量型:知识关联与相似搜索融合
1. Neo4j Vector Store
- 设计思路:图数据库界的"向量跨界王",核心是"图关系+向量相似"双维度检索。不仅能找相似向量,还能沿关系链扩展(如"找相似歌手→看他们合作的歌曲")。
- 核心算法公式:
支持HNSW和kNN,距离公式欧几里得/余弦,通过Cypher语句
vector.similarity调用,和图遍历语法结合。
- 系统架构:
基于Neo4j图存储引擎,向量作为节点属性,HNSW索引关联到节点。查询时Cypher语句既做向量相似搜索,又做图遍历(
MATCH (n)-[r]->(m)),实现复杂语义推理。
- 优缺点: ✅ 优点:向量+图关系深度融合(独特优势)、强事务支持、复杂语义推理; ❌ 缺点:向量性能不如专业数据库、大图遍历成本高。
- 适用场景:知识图谱相似检索(如"找和周杰伦相似的歌手及合作歌曲")、社交网络推荐(相似用户+好友关系)、企业知识关联检索。
2. Weaviate Vector Store
- 设计思路:原生"向量+图"数据库,核心是"语义搜索+知识关联"。把每个向量定义为"实体",支持实体间关系,查询时既能搜相似实体,又能沿关系扩展,像"智能百科全书"。
- 核心算法公式:
只支持HNSW($M=16$默认),距离公式欧几里得/余弦/内积,通过GraphQL接口
nearVector查询。
- 系统架构: 包含向量索引层(HNSW)、对象存储层(实体元数据)、图存储层(实体关系)、Query Engine(GraphQL/REST)。支持单机和集群,集群用一致性哈希分片。
- 优缺点: ✅ 优点:向量+图关系自然融合、GraphQL接口友好(前端直接调)、自带数据导入工具; ❌ 缺点:算法单一(只有HNSW)、超大规模性能待验证。
- 适用场景:企业知识图谱(如产品手册+关联配件)、语义搜索(结合实体关系)、LLM上下文关联检索(RAG应用)。
(六)缓存数据库+向量型:高并发实时首选
Redis Vector Store
- 设计思路:缓存界的"向量飞人",基于RedisSearch模块,核心是"内存速度+向量搜索"。利用Redis的内存存储和单线程模型,实现亚毫秒级响应,扛十万级QPS不在话下。
- 核心算法公式:
支持HNSW,距离公式欧几里得/余弦/内积,通过
FT.CREATE命令配置HNSW_M和HNSW_EF_CONSTRUCTION参数。
- 系统架构:
向量以Redis的
HASH或JSON类型存储,HNSW索引作为Redis模块在内存中维护。查询用FT.SEARCH命令,支持向量搜索+Tag过滤(如TAG {brand:apple}),和Redis缓存无缝结合。
- 优缺点: ✅ 优点:延迟极低(P99 < 10ms)、超高并发(十万QPS轻松扛)、缓存+向量一举两得; ❌ 缺点:内存成本高(全量数据放内存)、持久化恢复慢(大向量AOF恢复几小时)。
- 适用场景:实时推荐系统(电商"猜你喜欢")、高并发相似搜索(短视频同款推荐)、热点向量缓存(把高频查询向量放Redis)。
(七)轻量级/教学型:简单易用,入门首选
1. Chroma Vector Store
- 设计思路:LLM应用的"向量小跟班",专为RAG场景设计,核心是"简单API+快速集成"。一行代码启动,无需配置,和LangChain、LLamaIndex等框架无缝对接,堪称"本地知识库神器"。
- 核心算法公式: 支持HNSW(默认参数)和kNN,距离公式欧几里得/余弦,参数藏在后台,用户不用管。
- 系统架构:
单体架构,支持内存存储(调试用)和磁盘持久化(SQLite/PostgreSQL)。索引在内存中构建,API层极简(
add/query几行代码)。
- 优缺点: ✅ 优点:零配置启动、LLM框架集成好、本地开发友好; ❌ 缺点:性能一般(中小数据)、分布式能力弱。
- 适用场景:LLM本地知识库(如ChatGPT-like应用)、开发者快速验证、教学演示。
2. SimpleVectorStore
- 设计思路:向量存储界的"教学模型",核心是"极简实现+原理演示"。无复杂架构,用文件或内存列表存向量,查询时暴力遍历,适合理解向量搜索底层逻辑。
- 核心算法公式:
只支持暴力kNN,距离公式欧几里得/余弦,代码里直接写
for循环计算距离,一目了然。
- 系统架构:单体内存列表,向量和元数据存在
List<Vector>里,查询时遍历计算距离排序。
- 优缺点: ✅ 优点:代码极简(可当学习案例)、零依赖、原理清晰; ❌ 缺点:仅支持小规模数据(万级以下)、无性能优化。
- 适用场景:向量搜索入门教学、算法原理演示、本地极小数据集检索。
三、向量数据库选型决策指南:四步搞定"选择困难症"
选向量数据库就像选车——不是越贵越好,得看你"拉多少货"(数据量)、"跑多快"(性能需求)、"预算多少"(成本)。按这四步走,保准不踩坑:
(一)按数据规模"对号入座"
数据量 | 推荐数据库 | 核心理由 |
10万以内 | PgVector/Chroma | 轻量够用,SQL友好或集成LLM方便 |
10万-1000万 | Qdrant/Redis Vector Store | 轻量开源或高并发,中小规模性价比高 |
1000万-10亿 | Milvus/Elasticsearch | 分布式架构+算法全,大规模扛得住 |
10亿以上 | Milvus/Pinecone | 极致性能或全托管,省心又能打 |
(二)按性能需求"精准匹配"
- 低延迟(亚毫秒级):Redis Vector Store(内存索引,谁也快不过它);
- 高并发(10万QPS+):Redis Vector Store、Milvus集群(分布式抗并发);
- 高召回率(>95%):Milvus(HNSW调优)、PgVector(HNSW索引);
- 混合检索(向量+文本/过滤):Elasticsearch(全文+向量)、Weaviate(向量+图)。
(三)按运维能力"量力而行"
- 零运维:Pinecone、Azure Vector Search(全托管,不用管服务器);
- 轻运维:PgVector(PostgreSQL插件)、Redis Vector Store(Redis模块);
- 专业运维:Milvus(分布式组件多)、Apache Cassandra(P2P架构复杂)。
(四)按生态适配"无缝衔接"
- LLM/RAG应用:Chroma、Qdrant(LangChain集成第一梯队);
- PostgreSQL用户:PgVector(不用换数据库,直接扩展);
- Redis用户:Redis Vector Store(缓存+向量一步到位);
- 图数据需求:Neo4j、Weaviate(向量+关系双维度检索);
- 云厂商绑定:Azure Vector Search(微软云)、MongoDB Atlas(Mongo云)。
四、避坑指南:向量数据库的那些"坑"和解决方案
用向量数据库踩过的坑,能凑成一本"血泪史"。这里总结几个高频坑和解决办法,帮你少走弯路。
(一)算法参数调不好,召回率低到离谱
坑:用HNSW时召回率只有80%,明显漏了很多相似向量;用IVF_PQ时结果乱七八糟,和预期差太远。
原因:参数没调好,比如HNSW的太小、太低;IVF_PQ的太小、太低。
解决方案:
- HNSW调参口诀:起步,,;召回不够就加,内存不够就降M。
- IVF_PQ调参口诀:,;召回不够加,速度不够减。
- 工具:用Milvus的
search接口加metric_type=IP(内积)试试,有时比余弦效果好;用PgVector的ORDER BY vec <-> query_vec LIMIT 10先看暴力结果,再对比近似结果调参。
(二)内存爆炸,服务器扛不住
坑:HNSW索引建好后,内存占用比数据本身还大;IVF_PQ虽然省内存,但十亿级数据还是撑爆服务器。
原因:HNSW的图结构占内存;向量维度太高(比如1536维),积少成多。
解决方案:
- 降维:用PCA或AutoEncoder把高维向量降到512维以内(精度损失很小,内存省一半)。
- 换算法:内存紧张就从HNSW换成IVF_PQ,省70%内存。
- 分片存储:用Milvus的分片功能,把数据分到多个节点,摊薄内存压力。
- 冷热分离:RedisSearch只存热点向量,冷向量放Milvus,查询时先查热再查冷。
(三)动态增删向量后,性能暴跌
坑:向量数据库刚上线时很快,但持续加数据后查询越来越慢,甚至超时。
原因:HNSW动态加向量会导致图结构碎片化;IVF_PQ的聚类是静态的,新数据可能聚类不准。
解决方案:
- 定时重建索引:Milvus支持
compact命令优化索引,定期执行(比如每天一次)。
- 批量插入:尽量批量加数据(一次几千条),比单条插入更利于索引维护。
- 预留扩容空间:IVF_PQ建索引时nlist设大一点,预留3-5倍数据增长空间。
(四)维度超过上限,数据存不进去
坑:用PgVector存1536维向量时报错,说维度超过限制;RedisSearch存2048维向量后查询巨慢。
原因:PgVector默认维度上限2000(可改但不推荐);高维向量对任何算法都是负担。
解决方案:
- 强制降维:用Sentence-BERT的
all-MiniLM-L6-v2模型生成384维向量,比768维效果差不多但更省空间。
- 拆表存储:PgVector维度超限时,把向量拆成多个字段存在同一张表,查询时合并计算(麻烦但有效)。
- 换数据库:用Milvus(维度无上限)或FAISS(专为高维优化)存储超高维向量。
六、总结:从"工具"到"AI基础设施"
向量数据库正在从"高维数据存储工具"进化为"AI时代的水电煤"。未来它会更智能:算法自动调优(不用你算$M$和$n_{\text{list}}$)、多模态融合(文本/图像/音频向量一起搜)、和LLM深度绑定(向量存储直接喂给大模型)。它的核心价值不仅是"找相似",更是让机器理解数据语义的桥梁——无论是图片、文本、音频还是用户行为,都能通过向量转化为机器可理解的语言,再通过向量数据库实现快速检索和关联。
未来的向量数据库会更智能:算法会自动优化(不用人工调参),架构会更弹性(按需扩缩容),功能会更融合(向量+全文+图+时序数据一站式处理)。
对开发者来说,不用死磕所有数据库,但得吃透核心算法原理(距离公式、索引思想)和选型逻辑。记住:没有"最好"的数据库,只有"最适合"的选择
如果你刚开始接触向量数据库,建议从PgVector或Chroma入手(简单易上手),用HNSW算法跑通一个小案例(比如文档相似搜索),高并发用Redis飞起来,再逐步尝试Milvus等分布式数据库 想偷懒用Pinecone躺平。踩过几次坑,调通几次参数,你就会发现:原来高维数据的"收纳术",也没那么难!
下次再有人问你"向量数据库怎么选",把这篇甩给他——从公式到架构,从优点到坑点,一篇全搞定!