引言:为啥LLM厉害不厉害,不只是看“参数”?
你可能听过“GPT-4有多少参数”“Claude能处理多少token”这类说法,以前大家都觉得“参数越大,LLM越厉害”。但实际用起来会发现:同样是GPT-4,有时候回答又准又全,有时候却答非所问——关键不是模型本身,而是你给它的“上下文信息”够不够好。
举个简单例子:
如果你问LLM“今天北京天气怎么样?”,它要是只靠自己“脑子里的知识”(训练时的数据),最多只能告诉你“北京夏天热、冬天冷”,没法给实时温度。但如果让它先“查一下今天的天气数据”(这就是给它补充上下文),再回答,结果就准多了。
这就是“上下文工程”要解决的问题:不是让LLM变得更“聪明”,而是通过给它喂对、喂全信息,让它在具体任务里发挥出最好的效果。
本文专门给初学者写,没有复杂公式、不堆专业术语,用大白话讲清“上下文工程是什么、怎么用、能解决啥问题”,帮你快速入门。
一、先搞懂:上下文工程vs提示工程,到底不一样在哪?
很多初学者会把“上下文工程”和“提示工程”搞混,其实两者差得挺多。简单说:提示工程是“写好一句话让LLM干活”,上下文工程是“搭一套系统给LLM送有用的信息”。
用“做饭”类比一下,你就懂了:
对比维度 | 提示工程(Prompt Engineering) | 上下文工程(Context Engineering) |
像啥 | 给厨师说“做一盘番茄炒蛋”(一句话指令) | 给厨师准备好新鲜番茄、鸡蛋、盐,还告诉TA“客人不吃辣”(食材+需求,一套信息) |
信息来源 | 只有你写的那一句提示 | 能从多个地方找信息:比如查“番茄炒蛋的正宗做法”(外部知识)、记着“客人上次说爱吃溏心蛋”(历史记忆) |
能不能“记事儿” | 做完这道菜就忘,下次问还得重新说 | 能记着客人的口味,下次不用再提醒“不吃辣” |
适合啥任务 | 简单活:比如“写一句生日祝福”“翻译一句话” | 复杂活:比如“写一篇2024年AI行业报告”“帮糖尿病患者做饮食计划” |
简单总结:提示工程是“一次性指令”,上下文工程是“动态信息系统” ——这也是为什么现在做复杂AI应用,都要学上下文工程。
二、基础概念:上下文工程的“零件”和“逻辑”
上下文工程看着复杂,其实核心就两件事:凑齐有用的“信息零件”,再把零件装成LLM能用上的“上下文”。咱们拆成“零件层”和“优化层”讲,一点都不难。
2.1 零件层:上下文是由哪些“信息”组成的?
你可以把“上下文”想象成一个“信息包”,里面至少有3类关键零件,缺了任何一个,LLM都可能干活出错:
(1)指令零件:告诉LLM“要做啥”
就是你给LLM的核心任务,比如“写一篇关于猫咪养护的短文”“计算1+2×3等于多少”。
❌ 不好的指令:“写点关于猫的东西”(太模糊,LLM不知道写养护还是品种);
✅ 好的指令:“写一篇给新手看的猫咪养护短文,包含喂食、梳毛两个重点,每部分不超过200字”(清晰、具体)。
(2)外部知识零件:给LLM“查资料”
LLM的“记忆力”只到训练时的时间(比如GPT-4训练到2023年),而且专业知识可能不全。这时候就要给它补“外部知识”,比如:
- 问“2024年中国GDP多少”:要补“国家统计局2024年GDP数据”;
- 问“糖尿病怎么吃”:要补“《2024年糖尿病饮食指南》里的低GI食物列表”。 这种“先查资料再回答”的模式,就是后面会讲的“RAG”,是上下文工程里最常用的技术。
(3)记忆零件:给LLM“记事儿”
比如你和LLM聊了好几次“我家猫叫咪咪,不爱吃干粮”,下次再问“怎么让咪咪多吃饭”,LLM得能记着“咪咪是你家猫,不爱吃干粮”——这就是“记忆零件”。
没有记忆的话,每次聊天都像“第一次见面”,体验会很差。
零件怎么“组装”?有个简单逻辑
上下文不是把零件堆在一起就行,得按“有用程度”排序。比如做“咪咪饮食建议”的上下文,组装顺序应该是:
- 指令:“帮我想办法让咪咪多吃饭”;
- 记忆:“咪咪是我家猫,不爱吃干粮”;
- 外部知识:“猫咪不爱吃干粮时,可尝试湿粮+干粮混合喂养”。 这样LLM先明确任务,再结合记忆和知识,答案才会准。
2.2 优化层:怎么让上下文“更有用”?
组装好上下文后,还要判断“好不好用”——比如LLM用这个上下文回答后,你要看看“有没有解决问题”“有没有错信息”。如果不好用,就调整零件:
- 答案错了:可能是外部知识找错了(比如用了旧的饮食指南),换个新资料;
- 没解决问题:可能是指令太模糊(比如没说“咪咪3岁了”),补上细节。
简单说,优化层就是“用了看效果,不好就调整”,不用想太复杂。
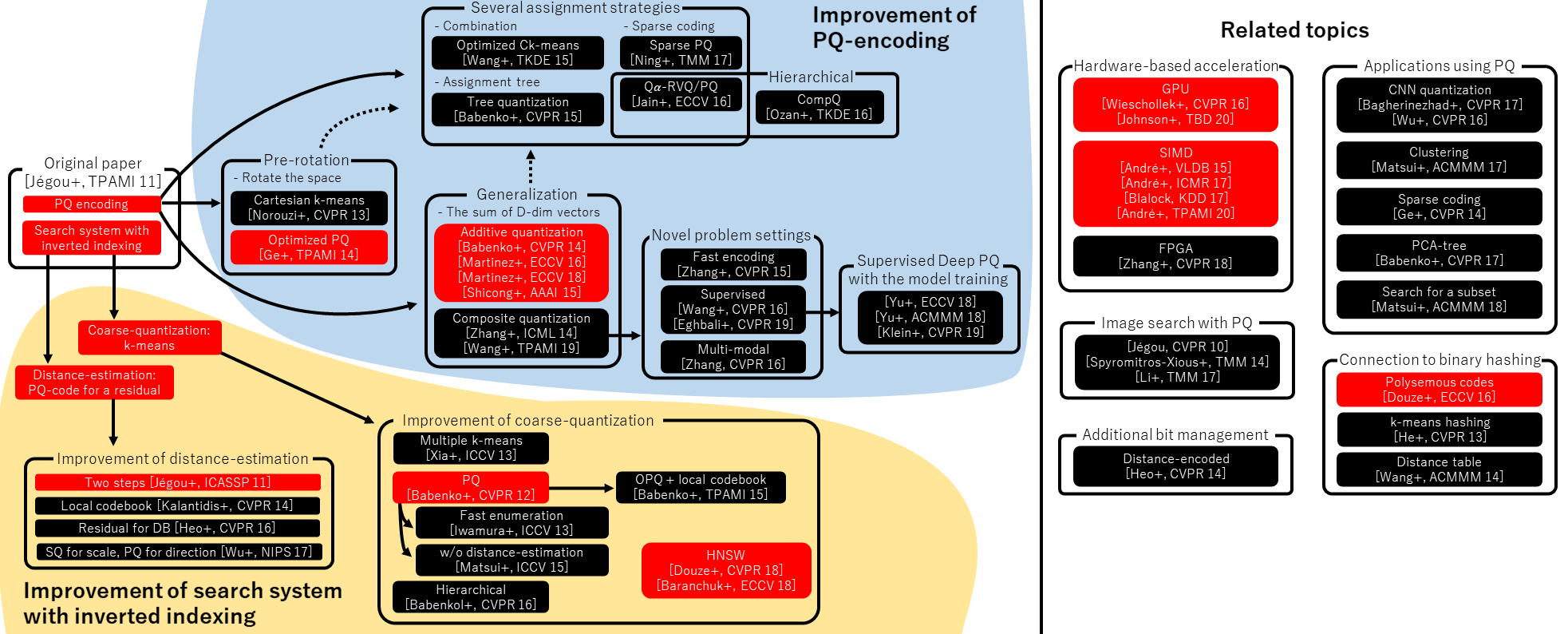
三、核心技术:初学者必懂的3大基础组件
上下文工程的落地,靠3个核心组件:检索生成(找信息、造信息)、处理(处理长信息)、管理(存信息)。每个组件都有适合初学者的简单技术,咱们一个个说。
3.1 组件1:检索生成——给LLM找对、造对信息
(1)先学“提示进阶”:让LLM自己“想清楚”
有时候不用补外部知识,只要把“指令拆细”,LLM就能答得更好。这就是“提示进阶”,最常用的有3个方法:
① 思维链(CoT):把复杂问题拆成小步骤
比如问“小明有5个苹果,给了小红2个,又买了3个,现在有几个?”,直接问的话,LLM可能算错。但如果加一句“咱们一步一步算”,它就会拆:
- 小明原来有5个,给小红2个,剩5-2=3个;
- 又买了3个,现在有3+3=6个。 这种“拆步骤”的提示,就是思维链。对数学题、逻辑题特别有用,能让LLM少犯低级错误。
② 思维树(ToT):给LLM“多选项”
比如问“周末去北京玩,怎么安排2天行程?”,思维链只会给一个方案,思维树会给多个选项:
- 选项1:天安门+故宫+景山(历史线);
- 选项2:颐和园+圆明园(园林线);
- 选项3:环球影城(娱乐线)。 然后让你选一个,再细化。适合需要“多方案选择”的任务。
③ 思维图(GoT):让LLM“不遗漏”
比如写“AI行业报告”,思维图会让LLM先列“报告框架”:
- 开头:行业现状;
- 中间:技术进展、企业动态;
- 结尾:未来趋势。 每个框架下再填内容,避免写着写着漏了重点。
(2)再学“RAG”:让LLM“查资料”
RAG是“检索增强生成”的简称,简单说就是“先检索外部资料,再用资料生成答案”。初学者不用懂复杂原理,记住3个步骤就行:
RAG入门3步走:
- 存资料:把你需要的资料(比如公司文档、行业报告)切成小片段,存在“向量数据库”里(可以理解成“专门存资料的文件夹”,常用的有FAISS、Pinecone,新手可以先试试免费的FAISS);
- 查资料:当你问LLM问题时,先从“文件夹”里找和问题最相关的资料(比如问“公司2024年营收”,就找“2024年财报片段”);
- 生成答案:把“问题+找到的资料”一起给LLM,让它基于资料回答。
举个实际例子:
你问“我们公司2024年Q1的销售额是多少?”
- 没有RAG:LLM会说“我不知道,我没学过你们公司的数据”;
- 有RAG:LLM先从“公司文档文件夹”里找到“2024年Q1财报”,里面写着“Q1销售额500万”,然后回答“根据2024年Q1财报,公司销售额为500万元”。
RAG是企业里用得最多的上下文技术,新手可以先从“用LangChain搭简单RAG”开始练(LangChain是个工具,有现成的RAG模板,后面会讲)。
(3)动态组装:让LLM自己“凑零件”
有时候信息太多,手动组装上下文太麻烦,这时候可以让LLM自己来:
- 比如用“Automatic Prompt Engineer(APE)”工具,它会自动生成多个“提示+上下文”组合,然后选最好的那个给LLM;
- 再比如“多智能体协作”:让一个“信息收集智能体”找资料,一个“整理智能体”组装上下文,最后给LLM用。 新手不用自己写代码,用现成的工具(比如AutoGPT)就能体验。
3.2 组件2:上下文处理——让LLM“能读长信息”
LLM原来只能处理短信息(比如GPT-3只能处理2048个token,大概1500字),但实际任务中经常要处理长文本(比如10万字的小说、100页的报告)。这时候就要用“长上下文处理技术”,新手先懂3个简单的:
(1)Mamba:让LLM“读长文不卡”
原来LLM读长文会“卡”,因为计算量随文字长度平方增长(比如1000字要算100万次,1万字就要算1亿次)。Mamba是个新架构,计算量只随文字长度增长(1万字算10万次),所以读长文又快又不卡。
新手不用懂原理,知道“用Mamba架构的LLM(比如Qwen-Mamba)能处理百万字长文”就行。
(2)LongRoPE:给LLM“扩内存”
可以把LLM的“上下文窗口”想象成“电脑内存”,原来只能存2000字,LongRoPE能把内存扩到20万字(比如Llama 2用了LongRoPE后,能处理2048K token)。
比如你想让LLM“总结一本10万字的书”,用LongRoPE就能直接把整本书给LLM,不用拆成小片段。
(3)稀疏注意力:让LLM“抓重点”
读长文时,不是每个字都重要(比如“的、了、吗”这些词)。稀疏注意力会让LLM只关注“关键信息”(比如书名、核心观点),忽略不重要的词,这样处理速度更快,还不遗漏重点。
比如读“2024年AI报告”,LLM会重点看“市场规模、龙头企业、技术突破”这些词,不用在“前言、目录”上浪费时间。
3.3 组件3:上下文管理——让LLM“记好信息”
LLM的“记忆”分两种:短期记忆(比如当前聊天的内容)和长期记忆(比如去年和你的聊天记录)。上下文管理就是“管好这两种记忆”,新手先懂2个核心:
(1)短时记忆:用KV缓存“临时存”
你和LLM聊天时,它会把你刚说的话存在“KV缓存”里(类似电脑的“临时内存”),这样回复时不用再重新读一遍聊天记录。
比如你说“我家猫叫咪咪”,LLM把这句话存在KV缓存里,后面问“咪咪爱吃啥”,它就能直接用,不用再问“咪咪是谁”。
(2)长时记忆:用外部存储“长久存”
KV缓存会“用完就清”(比如关掉聊天窗口就没了),长时记忆需要存在“外部数据库”里(比如MySQL、MongoDB)。
比如用“MemGPT”工具,它会把你的聊天记录、偏好存在数据库里,哪怕过一个月再聊,LLM还能记着“你家猫叫咪咪,不爱吃干粮”。
(3)记忆压缩:让存储“不占空间”
长时记忆存多了会占空间,这时候要“压缩”:比如把1000字的聊天记录,总结成100字的重点(“用户有只叫咪咪的猫,不爱吃干粮,想让它多吃饭”),既省空间,又不影响LLM用。
四、落地实践:初学者能上手的4大上下文系统
学完基础组件,接下来看“怎么把这些组件拼成能用的系统”。新手不用搞复杂的,先从4个常用系统入手,跟着做就能落地。
4.1 系统1:简单RAG系统——给LLM“查资料”(新手首选)
这是最适合新手的系统,用LangChain工具搭,3步就能成:
步骤1:准备工具
- 向量数据库:用FAISS(免费,不用装服务器,本地就能用);
- Embedding模型:用Sentence-BERT(把文字变成“向量”,方便FAISS查找);
- LLM:用GPT-3.5(免费额度够新手用)或Qwen-7B(开源,本地部署)。
步骤2:搭RAG流程
- 导入资料:把你要查的资料(比如“糖尿病饮食指南.txt”)切成小片段,用Sentence-BERT变成向量,存在FAISS里;
- 写查询代码:当你输入问题(比如“糖尿病能吃什么水果”),代码会先把问题变成向量,在FAISS里找相关的资料片段;
- 生成答案:把“问题+找到的资料片段”发给LLM,让它生成答案。
步骤3:测试效果
比如问“糖尿病能吃什么水果”,RAG会找到“指南里说低GI水果(苹果、梨、柚子)可以吃,高GI水果(西瓜、荔枝)要少吃”,LLM会基于这个资料回答,比直接问LLM准多了。
新手工具推荐:
- 不用写代码:用“LangChain Chat”网页版,上传资料就能生成RAG;
- 想写代码:看LangChain官方文档的“RAG入门教程”(有现成代码,复制粘贴就能用)。
4.2 系统2:长会话记忆系统——让LLM“记事儿”
适合做“个性化聊天机器人”,比如“猫咪养护助手”,步骤如下:
步骤1:准备工具
- 长时记忆数据库:用MongoDB(免费,新手用云数据库MongoDB Atlas,不用装本地);
- 记忆管理工具:用“LangChain Memory”组件(专门管LLM的记忆)。
步骤2:搭记忆流程
- 存储记忆:每次聊天后,用LangChain Memory把关键信息(比如“用户有只叫咪咪的猫,不爱吃干粮”)存在MongoDB里;
- 加载记忆:下次聊天时,先从MongoDB里加载之前的记忆,拼成上下文;
- 生成回复:把“新问题+加载的记忆”发给LLM,让它基于记忆回复。
步骤3:测试效果
第一次聊:“我家猫叫咪咪,不爱吃干粮”;
第二次聊:“怎么让咪咪多吃饭”;
LLM会回复:“可以给咪咪试试湿粮+干粮混合喂养,因为它不爱吃干粮”——这就是用到了长时记忆。
4.3 系统3:工具集成系统——让LLM“用工具”
比如让LLM“算数学题”“查天气”,需要它调用外部工具(计算器、天气API),用“ReAct”框架就能实现:
步骤1:准备工具
- 工具:用“Python解释器”(算数学题)、“天气API”(查实时天气,比如高德天气API,免费额度够新手用);
- 框架:用LangChain的“Agent”组件(让LLM判断“要不要调用工具、调用哪个工具”)。
步骤2:搭工具流程
- 定义工具:告诉LangChain“有Python解释器和天气API,怎么调用(比如API的参数、返回格式)”;
- 写提示:加一句“如果需要算数学题,就调用Python解释器;如果需要查天气,就调用天气API”;
- 测试:比如问“今天北京天气怎么样?”,LLM会自动调用天气API,获取实时数据后回答。
新手例子:
问“1234×5678等于多少?”
- LLM判断“这是数学题,需要调用Python解释器”;
- 调用Python解释器,计算1234×5678=6906652;
- 回复“1234×5678的结果是6906652”。
4.4 系统4:多智能体系统——让LLM“组队干活”
适合做复杂任务,比如“写一篇2024年AI行业报告”,让3个“智能体”组队:
智能体1:信息收集智能体
负责找资料:从网上查“2024年AI行业市场规模”“龙头企业动态”“技术突破”。
智能体2:整理智能体
负责组装上下文:把收集到的资料,按“市场规模→企业动态→技术突破”的顺序整理成结构化内容。
智能体3:写作智能体
负责生成报告:基于整理好的上下文,写一篇符合要求的报告(比如“3000字,给新手看,少用专业术语”)。
新手工具推荐:
用“AutoGPT”或“MetaGPT”,不用写代码,输入任务(比如“写一篇2024年AI行业报告,3000字,新手友好”),工具会自动分配智能体干活。
五、常见问题:初学者会踩的坑和解决办法
刚开始学上下文工程,容易遇到3个问题,提前知道怎么解决,能少走弯路。
5.1 问题1:LLM用了上下文还是答得错?
可能原因:
- 外部知识找错了(比如用了2020年的糖尿病指南,不是2024年的);
- 上下文组装乱了(比如把“咪咪不爱吃干粮”放在最后,LLM没看到)。
解决办法:
- 检查资料来源:确保用的是最新、最权威的资料(比如国家统计局、行业权威机构的文件);
- 调整组装顺序:把“指令”和“关键记忆”放在最前面,外部知识放后面。
5.2 问题2:处理长文本时LLM“卡得不行”?
可能原因:
- 用了普通Transformer架构的LLM(比如GPT-3.5),处理长文本计算量大;
- 没做文本压缩,把10万字的原文直接给LLM了。
解决办法:
- 换用Mamba或LongRoPE架构的LLM(比如Qwen-Mamba、Llama 2-LongRoPE);
- 先压缩文本:把长文本总结成重点(比如10万字的书,总结成5000字的大纲),再给LLM。
5.3 问题3:长时记忆“存了但用不上”?
可能原因:
- 记忆存在了本地,没和LLM关联(比如MongoDB里存了聊天记录,但代码没加载);
- 记忆总结得不好(比如把“咪咪3岁,不爱吃干粮”总结成“咪咪的情况”,LLM看不懂)。
解决办法:
- 检查代码:确保每次聊天前,都从数据库加载记忆;
- 优化总结:记忆要包含“关键信息”(谁、什么事、偏好),比如“用户的猫叫咪咪,3岁,不爱吃干粮”。
六、学习路径:新手怎么一步步学好上下文工程?
不用一开始就学复杂技术,按“3步走”,3个月就能入门:
第一步:打基础(1个月)
- 学LLM基本概念:知道“token是什么”“LLM怎么生成答案”(看《LLM入门指南》这类通俗文章);
- 练提示工程:用ChatGPT练“写清晰指令”(比如“写一篇猫咪养护短文,包含喂食、梳毛”);
- 学工具基础:会用LangChain(看官方入门教程)、FAISS(会导入资料、查资料)。
第二步:练组件(1个月)
- 练RAG:搭一个简单RAG系统,能查本地资料(比如“查糖尿病饮食指南”);
- 练记忆管理:用MemGPT或LangChain Memory,实现长会话记忆(比如“让LLM记着你家宠物的名字”);
- 练长上下文处理:用Qwen-Mamba处理一篇长文章(比如总结1万字的报告)。
第三步:做项目(1个月)
- 项目1:做一个“个人知识库RAG”,能查你的笔记、文档;
- 项目2:做一个“个性化聊天机器人”,能记着你的偏好,给你推荐内容;
- 项目3:做一个“工具助手”,能调用计算器、查天气,帮你解决简单问题。
七、总结:上下文工程对新手的价值
很多新手觉得“上下文工程难,都是工程师学的”,其实不是:
- 它不用你写复杂代码,有现成工具(LangChain、FAISS)可以用;
- 核心逻辑很简单:“给LLM找对信息、记好信息,让它干活更准”;
- 学会了能解决很多实际问题:比如让LLM查你的笔记、记着你的偏好、帮你写专业报告。
随着LLM越来越普及,“会用上下文工程”会成为一项重要技能——不是让你变成AI工程师,而是让你“用好AI,解决自己的问题”。
从今天开始,先搭一个简单的RAG系统,体验“让LLM查资料”的乐趣,慢慢就能上手啦!