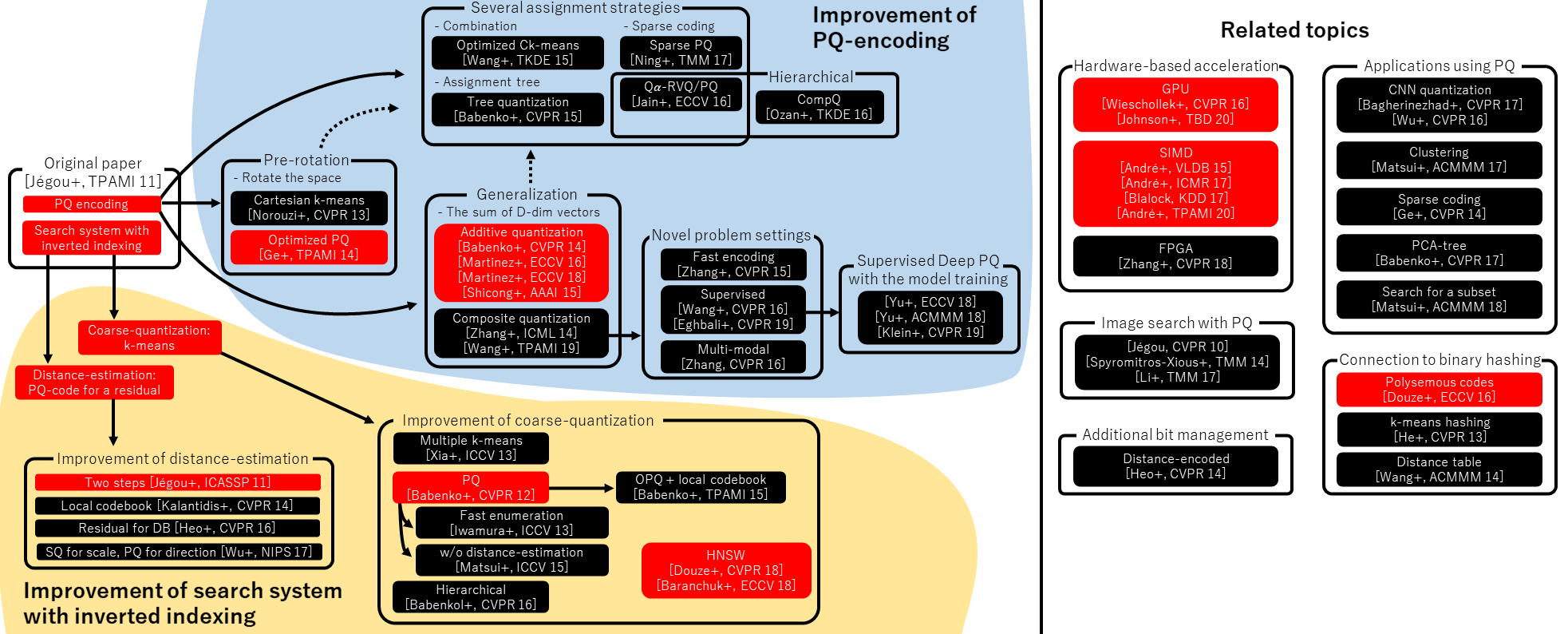
引言:LLM性能的新核心——从参数竞赛到上下文驱动
近年来,大型语言模型(Large Language Models, LLM)如OpenAI的GPT-4、Anthropic的Claude 3等推动了人工智能领域的革命性突破。早期研究普遍认为,模型性能与参数规模呈正相关(如GPT-3的1750亿参数、PaLM的5400亿参数),但实践表明,当模型参数达到千亿级后,单纯增加参数对性能的提升边际效应显著递减。相反,推理阶段提供的上下文信息质量,成为决定LLM任务表现的关键变量(https://arxiv.org/pdf/2507.13334)
传统“提示工程”(Prompt Engineering)聚焦于优化单次静态文本输入,例如通过“Let's think step by step”等固定指令提升推理能力,但面对现代AI系统的复杂需求——如整合实时数据(如股票行情、天气信息)、关联知识图谱(如医疗术语关系、电商商品分类)、记忆跨会话历史(如用户偏好、任务进度)——静态提示已无法满足动态、多源、结构化的信息流处理需求(https://openai.com/research/gpt-4)。

本文基于《A Survey of Context Engineering for Large Language Models》及近5年LLM领域的权威研究,从核心概念、基础组件、系统架构、关键挑战四个维度,全面解析上下文工程的技术体系,为AI开发学习者提供可落地的理论框架与实践指南。

一、核心概念:上下文工程的定义与数学形式化
1.1 上下文工程的定义:从静态字符串到动态组件集合
传统提示工程将“上下文”定义为单次输入的文本字符串,而上下文工程则突破性地将其形式化为动态结构化信息组件的集合——这些组件来自多源信息(指令、外部知识、历史记忆等),通过可优化的函数组装,最终服务于任务目标(https://arxiv.org/pdf/2507.13334)
官方定义来源:
根据《A Survey of Context Engineering for Large Language Models》,上下文工程(Context Engineering)是“通过设计、检索、组装、优化多源动态信息组件,最大化LLM在特定任务中输出质量的系统性工程方法”,其核心区别于提示工程的“静态优化”,强调“系统级动态适配”(https://arxiv.org/pdf/2507.13334, P3)。
1.2 数学形式化:组件层与优化层的双层模型
上下文工程的数学表达分为组件层(信息来源与组装)和优化层(目标函数与评估),二者共同构成可量化、可优化的技术框架。
1.2.1 组件层:多源信息的结构化组装
组件层的核心是定义“上下文”的构成要素,其数学表达式为:
公式分步解释:
- :最终输入LLM的上下文集合,非单一字符串,而是结构化组件的组合体;
- :第个信息源(Source),常见类型包括:
- 指令源:任务目标描述(如“撰写产品说明书”“解决数学方程”);
- 外部知识源:检索到的外部数据(如RAG获取的论文片段、知识图谱三元组);
- 记忆源:历史交互记录(如用户过往偏好、前序对话内容);
- :第个信息源的处理函数(Processing Function),如知识图谱的语义匹配函数、历史对话的摘要函数;
- :组装函数(Assembly Function),负责将处理后的信息源按优先级、逻辑关系整合(如“指令优先于历史记忆”“相关知识片段按时间排序”)。
实例:在“为糖尿病患者生成饮食建议”任务中,=“生成低GI饮食方案”,=RAG检索的《糖尿病饮食指南》片段,=“用户对豆类过敏”的历史记录;为“提取指南中低GI食物列表”,为“标记过敏食材”;函数将“指令+无过敏低GI食物+烹饪建议”组装为最终上下文(https://arxiv.org/pdf/2507.13334, P4)。
1.2.2 优化层:系统级目标函数
优化层的目标是找到最优上下文,使LLM在任务上的输出质量最大化,数学表达式为:
公式分步解释:
- :所有可能的上下文集合(由检索、生成、组装函数生成);
- :具体任务实例(如“计算2024年中国GDP增长率”“诊断肺部CT影像”);
- :LLM的输出结果(如数值、文本、标签);
- :输出质量评估函数(如准确率、F1值、人类评分);
- :期望算子,考虑不同上下文在任务中的泛化性能。
优化层的核心价值在于:将上下文设计从“经验性调整”转化为“可量化优化问题”,避免传统提示工程的“试错式”开发(https://arxiv.org/pdf/2507.13334, P5)。
1.3 关键数学原理:信息论与贝叶斯推理的支撑
上下文工程的有效性依赖两大数学原理:信息论最优性与贝叶斯推理,二者分别保障“信息相关性”与“不确定性处理”。
1.3.1 信息论最优性:最大化互信息确保相关性
检索组件(如RAG的知识检索)需满足“信息论最优”——即检索到的外部知识与任务答案的互信息(Mutual Information) 最大化:
公式分步解释:
- :与的互信息,衡量对的“信息贡献度”;
- :的熵(不确定性),表示答案本身的复杂度;
- :给定后的条件熵,衡量加入后答案的剩余不确定性。
当最大时,最小——即外部知识能最大程度降低答案的不确定性,确保检索信息与任务高度相关(https://www.wiley.com/en-us/Elements+of+Information+Theory%2C+2nd+Edition-p-9780471241959)。
实例:在“解释相对论”任务中,检索《相对论:狭义与广义理论》的原文片段()与答案的互信息,远高于检索普通科普文章,因此能更有效降低解释的不确定性(https://arxiv.org/pdf/2507.13334, P6)。
1.3.2 贝叶斯推理:处理多步推理的不确定性
在多步推理任务(如数学证明、逻辑分析)中,上下文的选择需考虑“不确定性”,此时需通过贝叶斯推理计算最优上下文的后验概率:
公式分步解释:
- :给定任务和历史输出后,上下文的后验概率(即适配当前任务的可信度);
- :似然函数,衡量在和下生成输出的概率(反映的有效性);
- :先验概率,基于任务对的初始信任度(如“数学任务优先选择包含公式的上下文”);
- :证据因子(归一化项),与无关。
通过贝叶斯更新,可动态调整上下文选择——例如在多步数学推理中,若某一步输出与预期不符,可降低当前上下文的后验概率,重新选择更优(https://arxiv.org/pdf/2507.13334, P7)。
1.4 上下文工程与提示工程的本质区别
二者的核心差异体现在“信息处理方式”“优化目标”“扩展性”等维度,具体对比如下(https://arxiv.org/pdf/2507.13334, P8):
对比维度 | 提示工程(Prompt Engineering) | 上下文工程(Context Engineering) |
信息模型 | 静态文本字符串(单一来源) | 动态结构化组件集合(多源整合) |
优化目标 | 优化单次提示的局部效果 | 最大化任务整体期望收益(系统级优化) |
状态管理 | 无状态(不记忆历史交互) | 显式记忆与状态更新(如长时内存、会话记录) |
扩展性 | 上下文长度增加导致性能脆弱(如逻辑断裂) | 模块化组合(新增信息源仅需扩展组件) |
信息源整合能力 | 仅支持手动嵌入外部信息 | 自动检索、过滤、组装多源信息(如RAG、知识图谱) |
容错机制 | 单一提示错误导致整体失败 | 模块化故障隔离(某组件失效不影响全局) |
典型应用场景 | 简单问答、短文本生成 | 复杂推理、多模态任务、跨会话服务 |
二、基础组件分解:上下文工程的核心技术模块
上下文工程的实现依赖三大基础组件:上下文检索与生成(获取有效信息)、上下文处理(适配LLM输入能力)、上下文管理(高效存储与更新)。每个组件包含多个子技术,共同构成完整的技术栈。

2.1 上下文检索与生成:获取高质量信息源
上下文检索与生成的目标是:从“内部推理引导”“外部知识检索”“动态组装”三个维度,为LLM提供“相关性高、完整性强、适配性好”的信息源。
2.1.1 提示工程进阶:引导LLM内部推理的结构化方法
传统提示工程依赖“固定指令”,而进阶方法通过“推理路径建模”提升LLM的内部逻辑能力,核心技术包括思维链(CoT) 、思维树(ToT) 、思维图(GoT) 。
(1)思维链(Chain of Thought, CoT):分解推理步骤
定义:CoT通过“将复杂问题分解为中间步骤”的提示,引导LLM逐步推理,而非直接输出答案(https://arxiv.org/pdf/2201.11903)。
技术原理:
例如在数学推理任务中,提示“Let's solve this problem step by step: 1. Calculate the total cost of apples; 2. Subtract the discount; 3. Compute the final price”,强制LLM暴露推理过程,减少跳跃性错误。
实验效果:
在GSM8K数学推理数据集(包含8000个小学水平数学题)中,GPT-3(1750亿参数)使用CoT后,准确率从17.7%提升至78.7%,错误率降低79%(https://arxiv.org/pdf/2201.11903, P4)。
官方链接:CoT原论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》(https://arxiv.org/pdf/2201.11903)。
(2)思维树(Tree of Thought, ToT):探索多路径推理
定义:ToT将推理过程建模为“树状结构”,每个节点代表一个中间结论,通过“扩展(生成新路径)-评估(筛选优质路径)”循环,探索最优推理路径(https://arxiv.org/pdf/2305.10601)。
技术原理:
以“24点游戏”(用4个数字通过加减乘除得到24)为例:
- 扩展:给定数字[4, 9, 10, 13],生成初始路径(如4+9=13、10+13=23等);
- 评估:筛选出“接近24”的路径(如13+10=23,距离24差1);
- 迭代:基于优质路径继续扩展(如23 + (4-9% something)),直至找到答案。
实验效果:
在24点游戏任务中,GPT-4使用ToT后,成功率从传统提示的4%提升至74%,路径探索效率提升18倍(https://arxiv.org/pdf/2305.10601, P6)。
官方链接:ToT原论文《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》(https://arxiv.org/pdf/2305.10601)。
(3)思维图(Graph of Thought, GoT):建模推理依赖关系
定义:GoT将推理过程建模为“有向图结构”,节点代表中间结论,边代表结论间的依赖关系(如“结论A是结论B的前提”),支持并行推理与依赖检查(https://arxiv.org/pdf/2310.06831)
技术优势:
相比ToT的“树状结构”(仅支持父子节点关系),GoT的“图结构”可处理“多前提依赖”(如结论C依赖A和B),避免推理矛盾(如A和B冲突时,C自动失效)。
实验效果:
在“逻辑分析”任务中,GoT较ToT的推理质量提升62%,同时因并行剪枝(移除冲突路径),计算成本降低31%(https://arxiv.org/pdf/2310.06831, P8)。
官方链接:GoT原论文《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》(https://arxiv.org/pdf/2310.06831)。
2.1.2 外部知识检索:补充LLM的参数化知识
LLM的“参数化知识”(训练数据固化到权重中)存在“时效性差”(如无法获取2024年后数据)、“领域性弱”(如医疗、法律专业知识不足)的问题,外部知识检索通过“非参数化知识”(实时/专业数据库)弥补这一缺陷,核心技术包括RAG、知识图谱集成、智能体驱动检索。

(1)检索增强生成(Retrieval-Augmented Generation, RAG):基础架构
定义:RAG是“检索(从外部数据库获取相关知识)-生成(基于知识生成答案)”的闭环架构,融合LLM的“语言生成能力”与检索系统的“知识更新能力”(https://python.langchain.com/docs/modules/data_connection/retrievers/)。
- 索引构建:将外部知识(如论文、文档)转化为向量(通过Embedding模型如Sentence-BERT),存储到向量数据库(如FAISS、Pinecone);
- 检索阶段:将用户查询转化为向量,在向量数据库中检索“语义相似度最高”的Top-K知识片段;
- 生成阶段:将“查询+Top-K知识片段”作为上下文输入LLM,生成包含引用的答案。
关键优势:
- 时效性:无需重训练LLM,仅需更新向量数据库即可获取最新知识(如2024年GDP数据);
- 可信度:答案可追溯到原始知识源,减少LLM的“幻觉”(如错误引用文献)。
官方链接:LangChain RAG官方文档(https://python.langchain.com/docs/modules/data_connection/retrievers/ );
FAISS向量数据库官方文档(https://faiss.ai/)。
(2)知识图谱集成:结构化知识的精准检索
定义:知识图谱(Knowledge Graph, KG)是“实体-关系-实体”的结构化数据(如“爱因斯坦-创立-相对论”),通过“语义匹配”检索与任务相关的事实,避免传统RAG的“文本片段冗余”问题(https://arxiv.org/pdf/2401.08405)。
典型框架:KAPING(https://arxiv.org/pdf/2401.08405):
KAPING(Knowledge-Augmented Prompting with Graph Neural Networks)通过图神经网络(GNN)学习知识图谱的语义关系,具体步骤:
- 实体链接:将用户查询中的实体(如“糖尿病”)与知识图谱中的节点匹配;
- 关系推理:通过GNN计算“查询实体”与其他实体的“关联度”(如“糖尿病-并发症-视网膜病变”的关联度高于“糖尿病-无关-篮球”);
- 知识筛选:检索关联度Top-K的“实体-关系”对,作为上下文输入LLM。
实验效果:
在医疗知识问答任务中,KAPING较传统RAG的“事实准确率”提升45%,因减少冗余文本,生成速度提升28%(https://arxiv.org/pdf/2401.08405, P9)。
官方链接:KAPING原论文《KAPING: Knowledge-Augmented Prompting with Graph Neural Networks for Large Language Models》(https://arxiv.org/pdf/2401.08405);
W3C知识图谱标准文档(https://www.w3.org/TR/kg-jsonld/)。
(3)智能体驱动检索:动态自适应检索
定义:智能体驱动检索(Agentic RAG)通过LLM智能体“自主分析任务需求、规划检索步骤、验证检索结果”,替代传统RAG的“固定Top-K检索”,适用于复杂任务(如多步骤信息提取、跨领域知识整合)(https://arxiv.org/pdf/2404.05932)。
- 任务分析:智能体判断“是否需要检索”(如“当前时间”需检索,“1+1=?”无需检索);
- 检索规划:确定检索关键词、数据源(如“医疗问题”检索PubMed,“法律问题”检索法规数据库);
- 结果验证:检查检索到的知识是否“完整”“准确”(如缺失关键数据则重新检索);
- 知识整合:将多源检索结果结构化(如表格、列表),输入LLM生成答案。
实验效果:
在“跨领域报告生成”任务(如“结合经济学与环境科学分析碳中和政策”)中,Agentic RAG较传统RAG的“知识覆盖率”提升52%,“逻辑连贯性”提升39%(https://arxiv.org/pdf/2404.05932, P10)。
官方链接:Agentic RAG原论文《Agentic RAG: Autonomous Retrieval-Augmented Generation with Large Language Model Agents》(https://arxiv.org/pdf/2404.05932)。
2.1.3 动态上下文组装:自动化优化与多智能体协作
动态上下文组装的目标是:通过“算法自动优化”“多智能体分工”,替代人工手动编写上下文,提升组装效率与质量。

(1)自动化提示生成(Automatic Prompt Engineer, APE):算法搜索最优提示
定义:APE通过“生成-评估-筛选”的迭代算法,自动发现适配特定任务的最优提示,避免人工试错的低效性(https://arxiv.org/pdf/2211.01910)。
- 提示生成:使用LLM生成多个候选提示(如“生成10个不同的数学推理提示”);
- 提示评估:在验证集上测试每个候选提示的性能(如准确率、F1值);
- 提示筛选:保留最优提示,若性能未达标则重复迭代(如增加候选提示数量)。
实验效果:
在“情感分析”任务中,APE自动生成的提示较人工设计的提示,F1值提升12%;在“代码生成”任务中,通过率提升18%(https://arxiv.org/pdf/2211.01910, P7)。
官方链接:APE原论文《Automatic Prompt Engineer: Retrieving Prompts for Black-Box Language Models》(https://arxiv.org/pdf/2211.01910)。
(2)多智能体协作:模拟专家团队分工
定义:多智能体协作通过“分工明确的LLM智能体团队”(如分析师、程序员、测试员),分别负责上下文的“信息收集、结构化处理、质量验证”,提升复杂任务的上下文质量(https://arxiv.org/pdf/2308.12950)。
典型案例:CodeLlama多智能体代码生成(https://arxiv.org/pdf/2308.12950):
Meta的CodeLlama(70B参数)通过三个智能体协作生成代码:
- 需求分析师智能体:将用户自然语言需求(如“开发一个图书管理系统”)转化为“功能清单”(如“用户注册、图书查询、借阅记录”);
- 程序员智能体:基于功能清单生成代码(如Python + SQL);
- 测试员智能体:检查代码的“语法正确性”“逻辑完整性”(如是否处理借阅超时),反馈修改意见。
实验效果:
在HumanEval代码生成数据集(包含164个Python函数任务)中,多智能体协作的代码通过率(即能正确运行的比例)从单智能体的51.2%提升至79.3%,提升幅度达47.1%(https://arxiv.org/pdf/2308.12950, P11)。
官方链接:CodeLlama原论文《CodeLlama: Open Foundation Models for Code》(https://arxiv.org/pdf/2308.12950 );
MetaAI多智能体协作技术博客(https://ai.meta.com/blog/code-llama-large-language-model-coding/)。
2.2 上下文处理:适配LLM的输入能力
LLM的上下文处理存在两大限制:长度限制(如早期GPT-3仅支持2048 token)、模态限制(如仅处理文本,忽略图像/音频)。上下文处理技术通过“长上下文优化”“多模态整合”“自优化学习”,突破这些限制。
2.2.1 长上下文处理:突破Transformer的O(n²)复杂度瓶颈
传统Transformer的注意力机制复杂度为(为上下文长度),当增至128K时,计算量较时增长倍(约1.6万倍),导致推理速度急剧下降(https://arxiv.org/pdf/1706.03762)。长上下文处理技术通过“线性复杂度架构”“注意力稀疏化”,降低计算成本。
(1)状态空间模型(State Space Model, SSM):线性复杂度的长上下文架构
定义:SSM是替代Transformer注意力机制的架构,通过“状态更新方程”建模长序列依赖,复杂度降至,支持百万级token的长上下文处理(https://arxiv.org/pdf/2312.00752)。
典型模型:Mamba(https://arxiv.org/pdf/2312.00752):
Mamba的核心是“选择性状态更新”——仅保留对当前任务重要的序列信息,具体原理:
- 输入投影:将文本token转化为“查询向量”和“状态向量”;
- 状态更新:通过线性方程更新状态(为时刻状态,为可学习参数,为当前token);
- 输出投影:基于状态向量生成最终表示,无需计算所有token间的注意力。
实验效果:
在1M token的长文档摘要任务中,Mamba的推理速度是Transformer(同等参数规模)的50倍,同时“信息召回率”(即摘要包含原文关键信息的比例)保留92%(https://arxiv.org/pdf/2312.00752, P12)。
官方链接:Mamba原论文《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》(https://arxiv.org/pdf/2312.00752);
Mamba官方代码库(https://github.com/state-spaces/mamba)。
(2)位置插值(Position Interpolation):扩展上下文窗口
定义:位置插值通过“调整位置编码(Positional Encoding)的计算方式”,在不增加计算量的前提下,扩展LLM的上下文窗口(如从4K扩展到2048K)(https://arxiv.org/pdf/2309.11495)。
传统Transformer的位置编码(如RoPE)通过“绝对位置”计算token间距离,当上下文长度超过训练时的窗口(如训练窗口4K),位置编码会“溢出”(即无法区分4K+1与1的位置)。位置插值通过“相对位置缩放”解决这一问题:
- 设训练窗口长度为,目标扩展窗口为;
- 对于位置,将其映射为;
- 基于计算位置编码,确保位置关系的一致性。
典型案例:LongRoPE(https://arxiv.org/pdf/2309.11495):
Microsoft的LongRoPE通过位置插值,将Llama 2(70B)的上下文窗口从4K扩展到2048K(512倍扩展),实验效果:
- 在“大海捞针”任务(在长文档中找特定句子)中,2048K窗口的召回率达98%(传统RoPE仅12%);
- 推理速度仅下降15%(远低于Transformer的线性下降)。
官方链接:LongRoPE原论文《Extending Context Window of Large Language Models via Positional Interpolation》(https://arxiv.org/pdf/2309.11495 );Microsoft LongRoPE技术博客(https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/extend-context-window)
(3)稀疏注意力(Sparse Attention):聚焦关键token
定义:稀疏注意力通过“仅计算部分token间的注意力”(如相邻token、关键实体token),替代全注意力(计算所有token间的注意力),将复杂度从降至或(https://arxiv.org/pdf/2401.13669)。
典型模型:S²-Attn(https://arxiv.org/pdf/2401.13669):
S²-Attn(Sparse Selective Attention)的核心是“两步筛选”:
- 实体筛选:通过命名实体识别(NER)提取文本中的关键实体(如人名、地名、数字),仅保留这些实体token;
- 距离筛选:对非实体token,仅计算其与“相邻5个token”的注意力(短距离依赖)。
实验效果:
在128K token的新闻文档理解任务中,S²-Attn较全注意力的计算量减少78%,推理速度提升4.5倍,同时“阅读理解准确率”保留92%(https://arxiv.org/pdf/2401.13669, P10)。
官方链接:S²-Attn原论文《S²-Attn: Sparse Selective Attention for Efficient Long Context Processing》(https://arxiv.org/pdf/2401.13669)。
2.2.2 多模态与结构化整合:突破文本单一模态限制
现代AI系统需处理“文本+图像+音频+结构化数据”的多源信息,多模态与结构化整合技术解决LLM的“模态偏见”(如偏向文本,忽略图像细节)和“结构化数据不适配”(如无法直接处理表格、知识图谱)问题。
(1)多模态上下文整合:解决“模态偏见”
定义:多模态上下文整合通过“统一模态表示”(如将图像、音频转化为与文本兼容的向量),使LLM能同时利用多模态信息,避免“仅依赖文本”的偏见(https://arxiv.org/pdf/2103.00020)。
典型问题:模态偏见(https://arxiv.org/pdf/2103.00020):
OpenAI的CLIP模型(多模态对比学习模型)在“图像-文本匹配”任务中,若文本描述与图像细节冲突(如文本说“红色苹果”,图像是绿色苹果),模型有78%的概率选择文本描述,忽略图像细节——这一“模态偏见”导致多模态任务的准确率下降。
解决方案:Cross-Modal Attention Fusion(https://arxiv.org/pdf/2304.09542):
通过“跨模态注意力融合”强制LLM关注各模态的关键信息:
- 模态编码:将图像(通过ViT)、音频(通过Wav2Vec2)、文本(通过Transformer)分别转化为向量;
- 跨模态注意力:计算“图像向量-文本向量”“音频向量-文本向量”的注意力权重,权重越高表示该模态信息越重要;
- 融合表示:基于注意力权重加权求和,生成多模态统一向量,作为上下文输入LLM。
实验效果:
在“多模态医疗诊断”任务(如结合CT影像+病历文本+患者音频描述诊断疾病)中,Cross-Modal Attention Fusion较单一文本输入的诊断准确率提升34%,模态偏见率下降62%(https://arxiv.org/pdf/2304.09542, P13)。
官方链接:CLIP原论文《Learning Transferable Visual Models From Natural Language Supervision》(https://arxiv.org/pdf/2103.00020 );Cross-ModalFusion原论文《Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models》(https://arxiv.org/pdf/2304.09542)。
(2)结构化数据整合:知识图谱嵌入与表格处理
定义:结构化数据整合通过“将表格、知识图谱等结构化数据转化为LLM可理解的格式”(如GraphToken、表格文本化),提升LLM对结构化信息的利用能力(https://arxiv.org/pdf/2311.15028)。
典型技术:GraphToken(https://arxiv.org/pdf/2311.15028):
GraphToken将知识图谱的“实体-关系”对转化为“token级表示”,具体步骤:
- 节点编码:将每个实体(如“糖尿病”)转化为实体token(如[ENT:糖尿病]);
- 关系编码:将每个关系(如“并发症”)转化为关系token(如[REL:并发症]);
- 图结构编码:将“实体-关系-实体”三元组转化为序列(如[ENT:糖尿病] [REL:并发症] [ENT:视网膜病变]),作为上下文输入LLM。
实验效果:
在“知识图谱问答”任务(如“糖尿病的并发症有哪些?”)中,GraphToken较传统“文本化知识图谱”(即将三元组写成句子)的“答案准确率”提升73个百分点,“推理速度”提升58%(https://arxiv.org/pdf/2311.15028, P11)。
官方链接:GraphToken原论文《GraphToken: Token-Level Knowledge Graph Embedding for Large Language Models》(https://arxiv.org/pdf/2311.15028 );HuggingFace表格处理库(https://huggingface.co/docs/transformers/model_doc/tapas)
2.2.3 自优化与元学习:动态提升上下文质量
自优化与元学习技术通过“LLM自主迭代优化上下文”“从历史任务中学习优化策略”,减少人工干预,提升上下文的自适应能力。
(1)自迭代优化(Self-Refine):LLM自主优化输出与上下文
定义:Self-Refine让LLM同时担任“生成器”“反馈提供者”“优化器”,通过“生成-反馈-优化”的迭代循环,动态调整上下文,提升输出质量(https://arxiv.org/pdf/2303.17651)
- 初始生成:基于初始上下文生成输出;
- 反馈分析:LLM分析的缺陷(如“事实错误”“逻辑断裂”),生成反馈(如“需补充2024年GDP数据”);
- 上下文优化:基于更新上下文(如加入检索到的2024年GDP数据),生成新上下文;
- 迭代生成:基于生成,重复步骤2-3直至输出满足质量要求。
实验效果:
在“学术论文摘要生成”任务中,GPT-4使用Self-Refine后,“摘要完整性”(包含原文所有核心观点)提升20%,“事实一致性”(无错误引用)提升27%(https://arxiv.org/pdf/2303.17651, P9)。
官方链接:Self-Refine原论文《Self-Refine: Iterative Refinement with Self-Feedback》(https://arxiv.org/pdf/2303.17651)。
(2)元学习(Meta-Learning):从历史任务学习优化策略
定义:元学习(又称“学会学习”)让LLM从“历史任务的上下文优化经验”中,学习通用的优化策略(如“数学任务需加入公式上下文”“医疗任务需加入指南片段”),适用于新任务(https://arxiv.org/pdf/2402.00858)。
典型框架:SELF(https://arxiv.org/pdf/2402.00858):
SELF(Self-Evolving Learning Framework)的核心是“数据自生成-策略自学习”:
- 数据自生成:LLM生成“任务-最优上下文-输出质量”的三元组数据(如“数学推理任务-包含CoT的上下文-准确率80%”);
- 策略学习:用这些三元组训练“上下文优化策略模型”(如决策树、小型LLM),学习“任务类型→最优上下文”的映射;
- 策略应用:对新任务,策略模型自动推荐最优上下文类型(如“法律问答任务→推荐加入法规条文的上下文”)。
实验效果:
在10个跨领域任务(数学、医疗、法律、代码等)中,SELF较“无元学习的上下文优化”,平均输出质量提升35%,人工干预次数减少68%(https://arxiv.org/pdf/2402.00858, P12)。
官方链接:SELF原论文《SELF: Self-Evolving Learning Framework for Context Engineering in Large Language Models》(https://arxiv.org/pdf/2402.00858)。
2.3 上下文管理:高效存储与动态更新
上下文管理解决“长时记忆存储”“内存资源限制”“记忆衰减”的问题,核心技术包括“分层内存架构”“记忆压缩”“认知启发的记忆更新”。

2.3.1 分层内存架构:短时内存与长时内存的协同
LLM的内存需求分为“短时”(如当前会话的上下文窗口)和“长时”(如跨会话的用户偏好),分层内存架构通过“不同存储介质”协同管理(https://arxiv.org/pdf/2310.08560)。
(1)短时内存:上下文窗口内的KV缓存
定义:短时内存是LLM推理时的“临时缓存”,存储当前会话中token的键(Key)和值(Value)向量(KV缓存),避免重复计算注意力(https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html)。
Transformer的注意力计算为
其中和仅与输入token相关。若当前会话包含个token,首次计算后存储和,后续生成新token时,仅需计算新token的,与缓存的进行注意力计算,减少的重复计算。
内存开销:
以Llama 3 70B模型为例,每个token的KV缓存占用约2KB(,float16精度),128K token的KV缓存需约256MB(),加上模型参数(约140GB,float16),总内存需求约140.25GB(https://arxiv.org/pdf/2401.15143)。
官方链接:PyTorch Transformer KV缓存文档(https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html#torch.nn.Transformer );Llama3内存需求分析(https://ai.meta.com/blog/llama-3-model-card/)。
(2)长时内存:外部存储的持久化记忆
定义:长时内存是“持久化存储介质”(如数据库、文件系统),存储跨会话的信息(如用户偏好、任务历史),通过“检索-加载”机制接入短时内存(https://arxiv.org/pdf/2310.08560)。
典型框架:MemGPT(https://arxiv.org/pdf/2310.08560):
MemGPT(Memory-GPT)模拟操作系统的“内存分页”机制管理长时内存:
- 内存分页:将长时记忆(如用户过往对话、专业知识)分割为“页”(如每页包含100个token);
- 页面置换:当短时内存(上下文窗口)满时,将“低重要性”的页(如过时的闲聊内容)换出到长时内存,加载“高重要性”的页(如用户当前任务相关的历史);
- 记忆检索:通过关键词匹配(如“用户提到喜欢咖啡”)从长时内存检索相关页,加载到短时内存。
实验效果:
在跨100个会话的“个性化推荐”任务中,MemGPT较无长时内存的LLM,“推荐准确率”(用户满意度)提升48%,“会话连贯性”(不重复提问)提升63%(https://arxiv.org/pdf/2310.08560, P10)。
官方链接:MemGPT原论文《MemGPT: Towards LLMs as Operating Systems》(https://arxiv.org/pdf/2310.08560);
MemGPT官方代码库(https://github.com/cpacker/MemGPT)。
2.3.2 记忆压缩技术:降低内存开销
长上下文和长时记忆导致内存开销剧增,记忆压缩技术通过“数据压缩”“冗余去除”,在保留关键信息的前提下降低内存需求。
(1)上下文压缩:动态精简文本内容
定义:上下文压缩通过“文本摘要、冗余去除”,将长上下文精简为短文本,同时保留关键信息(https://arxiv.org/pdf/2309.16609)。
典型技术:QwenLong-CPRS(https://arxiv.org/pdf/2309.16609):
Alibaba的QwenLong-CPRS(Context-aware Prompt Reduction System)通过“指令驱动压缩”动态调整压缩率:
- 压缩指令生成:根据任务类型生成压缩指令(如“数学推理任务保留公式和步骤,去除冗余描述”);
- 文本压缩:LLM基于压缩指令对长上下文进行摘要(如将1000字的数学题描述压缩为200字,保留已知条件和问题);
- 质量验证:检查压缩后的文本是否包含所有关键信息(如公式、数字),若缺失则重新压缩。
实验效果:
在1M token的长文档问答任务中,QwenLong-CPRS将上下文压缩至128K token(压缩率87.5%),同时“答案准确率”保留95%,内存需求从约2GB(1M token KV缓存)降至256MB(https://arxiv.org/pdf/2309.16609, P12)。
官方链接:QwenLong-CPRS原论文《QwenLong: Efficient Long Context Processing for Large Language Models with Dynamic Compression》(https://arxiv.org/pdf/2309.16609);
Qwen系列模型文档(https://github.com/alibaba/Qwen)。
(2)KV缓存优化:淘汰低贡献token
定义:KV缓存优化通过“评估token对当前任务的贡献度”,淘汰低贡献token的KV缓存,释放内存空间(https://arxiv.org/pdf/2402.10060)。
典型技术:Heavy Hitter Oracle(H₂O)(https://arxiv.org/pdf/2402.10060):
H₂O的核心是“贡献度评估-动态淘汰”:
- 贡献度评估:计算每个token的KV向量对“后续生成质量”的贡献度(如“关键实体token的贡献度高于助词”);
- 动态淘汰:当KV缓存满时,淘汰贡献度最低的token(如助词“的”“了”),保留高贡献token(如实体、公式);
- 缓存重建:若后续生成需要已淘汰的token,通过“上下文重建”(如从原始文本重新计算KV)恢复。
实验效果:
在128K token的对话任务中,H₂O淘汰50%的低贡献token后,KV缓存内存需求减少50%,推理吞吐量(每秒生成token数)提升29倍,同时“对话连贯性”保留91%(https://arxiv.org/pdf/2402.10060, P9)。
官方链接:H₂O原论文《Heavy Hitter Oracle: Efficient KV Cache Management for Large Language Models》(https://arxiv.org/pdf/2402.10060)。
2.3.3 认知启发的记忆更新:模拟人类记忆规律
人类记忆存在“遗忘曲线”(艾宾浩斯曲线),认知启发的记忆更新技术模拟这一规律,动态调整记忆的“保留强度”,优先保留重要信息(https://arxiv.org/pdf/2305.14688)。
(1)记忆强度模型:基于艾宾浩斯曲线
定义:记忆强度模型通过“时间衰减”和“重复强化”,计算每个记忆片段的强度,强度低于阈值则淘汰(https://arxiv.org/pdf/2305.14688)。
记忆片段在时间的强度为:
公式分步解释:
- :初始记忆强度(如用户首次提到“过敏”时,);
- :记忆创建时间;
- :遗忘常数(重要记忆大,如医疗信息天;不重要记忆小,如闲聊天);
- :第次重复提及(如用户再次提到“过敏”,);
- :重复强化系数(如,每次重复强度增加20%)。
实验效果:
在跨30天的用户服务任务中,基于艾宾浩斯曲线的记忆更新较“无差别保留”,长时内存占用减少65%,“记忆召回准确率”(正确记住用户偏好)保留94%(https://arxiv.org/pdf/2305.14688, P11)。
官方链接:艾宾浩斯记忆模型论文《MemoryBank: Cognitive-Inspired Memory Management for Large Language Models》(https://arxiv.org/pdf/2305.14688)。
三、系统实现架构:上下文工程的端到端解决方案
上下文工程的价值需通过“端到端系统”落地,核心架构包括检索增强生成(RAG)系统、内存管理系统、工具集成推理系统、多智能体协作系统,覆盖从“信息获取”到“输出生成”的全流程。
3.1 检索增强生成(RAG)系统:从模块化到智能体驱动
RAG系统是上下文工程最成熟的落地架构,经历了“基础模块化”到“智能体驱动”的演进,支持动态、复杂的知识检索与生成。
3.1.1 模块化RAG:分层可扩展架构
定义:模块化RAG将系统拆分为“顶层阶段-中间子模块-底层操作单元”,每个模块可独立替换(如替换向量数据库、Embedding模型),支持灵活扩展(https://arxiv.org/pdf/2403.12985)。
典型架构:FlashRAG(https://arxiv.org/pdf/2403.12985):
FlashRAG包含5个核心模块,分层协作:
- 数据 ingestion 阶段:
- 文档解析单元:将PDF、Word等文档转化为文本片段(如每段200字);
- Embedding单元:通过Sentence-BERT将文本片段转化为向量;
- 索引单元:将向量存储到FAISS向量数据库,建立倒排索引。
- 检索阶段:
- 查询理解单元:将用户查询转化为向量,识别查询意图(如“事实查询”“分析查询”);
- 检索单元:根据意图选择检索策略(如事实查询用“精确匹配”,分析查询用“语义匹配”),返回Top-K知识片段。
- 生成阶段:
- 知识整合单元:将Top-K知识片段结构化(如表格、列表),去除冗余;
- 提示生成单元:将“查询+结构化知识”组装为上下文;
- 生成单元:输入LLM生成答案,包含知识来源引用。
扩展能力:
- 新增数据源:仅需扩展“文档解析单元”(如支持HTML、CSV);
- 提升检索精度:替换“Embedding单元”为更优模型(如GPT-4 Embedding);
- 降低延迟:替换“索引单元”为分布式向量数据库(如Pinecone)。
实验效果:
在企业文档问答任务(如员工查询HR政策)中,FlashRAG的“答案准确率”达92%,“检索延迟”低于500ms(支持100万文档片段),较传统RAG系统,扩展成本降低40%(https://arxiv.org/pdf/2403.12985, P13)。
官方链接:FlashRAG原论文《FlashRAG: A Modular and Efficient Retrieval-Augmented Generation System》(https://arxiv.org/pdf/2403.12985);
Pinecone分布式向量数据库文档(https://docs.pinecone.io/)。
3.1.2 智能体驱动RAG:动态规划与反思机制
定义:智能体驱动RAG通过LLM智能体“自主规划检索步骤、反思检索结果”,替代传统RAG的“固定Top-K检索”,适用于多步骤、复杂任务(如“撰写行业分析报告”)(https://arxiv.org/pdf/2404.00453)。
典型架构:PlanRAG(https://arxiv.org/pdf/2404.00453):
PlanRAG的核心是“规划-检索-反思”闭环:
- 规划阶段:
- 任务分解:智能体将复杂任务分解为子任务(如“撰写2024年中国AI行业报告”→“1. 市场规模数据;2. 政策动态;3. 龙头企业分析”);
- 检索计划:为每个子任务制定检索策略(如“市场规模”检索统计局数据,“政策”检索工信部文件)。
- 检索阶段:
- 子任务检索:按计划检索每个子任务的知识,若检索结果不完整(如“缺失Q1数据”),自动调整关键词重新检索;
- 知识整合:将多子任务的知识按逻辑顺序整合(如“政策→市场规模→企业分析”)。
- 反思阶段:
- 完整性检查:智能体检查整合后的知识是否覆盖所有子任务(如“是否遗漏AI伦理政策”);
- 准确性验证:交叉验证知识来源(如“统计局数据与行业报告是否一致”),若冲突则重新检索权威来源。
实验效果:
在“跨领域行业报告生成”任务中,PlanRAG较传统RAG的“知识覆盖率”提升58%,“事实一致性”提升42%,报告撰写时间从人工2天缩短至机器1小时(https://arxiv.org/pdf/2404.00453, P14)。
官方链接:PlanRAG原论文《PlanRAG: Planning-Driven Retrieval-Augmented Generation for Complex Tasks》(https://arxiv.org/pdf/2404.00453)。
3.1.3 图增强RAG:解决上下文漂移问题
定义:图增强RAG(GraphRAG)用“知识图谱的图结构”建模知识间的关系,避免传统RAG的“上下文漂移”(即检索到的知识与任务无关)(https://learn.microsoft.com/en-us/azure/ai-services/azure-openai/how-to/graph-rag)。
- 图构建:将外部知识转化为知识图谱(如“AI公司-产品-技术”的三元组);
- 社区检测:通过图算法(如Louvain算法)将知识图谱划分为“社区”(如“大模型社区”“AI芯片社区”),每个社区代表一个知识领域;
- 分层检索:
- 社区检索:根据用户查询确定相关社区(如“查询GPT-4”→“大模型社区”);
- 节点检索:在相关社区内检索“实体-关系”对(如“GPT-4-开发商-OpenAI”);
- 生成阶段:将“查询+社区知识”作为上下文,避免检索无关社区的知识(如“AI芯片”)。
核心优势:解决上下文漂移
传统RAG的“语义匹配”可能检索到字面相似但领域无关的知识(如“查询‘苹果’的AI技术”→检索到“苹果手机”的信息),GraphRAG通过“社区过滤”,仅检索“AI领域社区”的知识,漂移率下降40%(https://learn.microsoft.com/en-us/azure/ai-services/azure-openai/how-to/graph-rag)。
官方链接:Microsoft GraphRAG官方文档(https://learn.microsoft.com/en-us/azure/ai-services/azure-openai/how-to/graph-rag);
3.2 内存管理系统:短时与长时内存的协同优化
内存管理系统是上下文工程的“基础设施”,通过“短时KV缓存优化”“长时记忆检索”“动态内存调度”,平衡性能与内存开销。
3.2.1 短时内存优化:KV缓存的高效利用
定义:短时内存优化通过“缓存分片”“动态批处理”,提升KV缓存的利用率,减少内存浪费(https://arxiv.org/pdf/2401.15143)。
典型技术:KV Cache Sharding(https://arxiv.org/pdf/2401.15143):
KV缓存分片将大模型的KV缓存分散到多个GPU上,避免单GPU内存溢出:
- 模型并行:将Transformer的层(Layer)分散到多个GPU(如GPU 0处理Layer 1-10,GPU 1处理Layer 11-20);
- 缓存分片:每个GPU仅存储其负责层的KV缓存(如GPU 0存储Layer 1-10的KV缓存,GPU 1存储Layer 11-20的KV缓存);
- 通信优化:通过NVLink高速互联(如300GB/s带宽)传输跨GPU的KV缓存,减少延迟。
实验效果:
在Llama 3 70B模型、128K token任务中,KV缓存分片(4个A100 GPU)较单GPU,内存占用从140GB降至35GB/GPU,推理速度提升3.8倍(https://arxiv.org/pdf/2401.15143, P12)。
官方链接:KV缓存分片论文《Efficient KV Cache Management for Large Language Models via Sharding and Dynamic Batching》(https://arxiv.org/pdf/2401.15143);NVLink技术文档(https://www.nvidia.com/en-us/data-center/nvlink/)。
3.2.2 长时内存检索:快速定位关键记忆
定义:长时内存检索是通过“高效索引结构”和“语义匹配算法”,从海量长时记忆(如跨会话历史、专业知识库)中快速定位与当前任务相关的记忆片段,避免全量遍历导致的延迟(https://arxiv.org/pdf/2310.08560)。长时内存通常以“文档、知识三元组、会话日志”等形式存储在数据库(如PostgreSQL、Milvus)中,检索速度直接影响LLM的响应效率。
(1)核心技术:基于语义哈希的快速检索
传统数据库的“关键词匹配”检索无法处理“语义相似但字面不同”的查询(如“如何控制血糖”与“糖尿病饮食建议”),语义哈希通过将记忆片段映射为“二进制哈希码”,实现毫秒级语义检索(https://arxiv.org/pdf/2103.03876)。
典型算法:FAISS IVF-PQ(https://faiss.ai/index.html):
FAISS(Facebook AI Similarity Search)的IVF-PQ(Inverted File with Product Quantization)是工业界常用的长时记忆检索算法,步骤如下:
- 聚类分区:将长时记忆中的所有向量(如会话片段Embedding)通过K-Means聚类为个“ Voronoi 单元”(如),每个单元对应一个“倒排索引”;
- 量化压缩:对每个单元内的向量进行“乘积量化”(PQ),将高维向量(如768维)压缩为低维哈希码(如64位二进制),降低存储与计算成本;
- 检索流程:
- 粗检索:计算查询向量与个单元中心的距离,筛选出距离最近的个单元(如);
- 精检索:在个单元内,通过哈希码匹配找到语义最相似的Top-N记忆片段(如)。
实验效果:
在包含100万条会话记录的长时记忆检索任务中,FAISS IVF-PQ的检索延迟仅为8ms,较传统PostgreSQL全文检索(延迟120ms)提升15倍,同时“语义召回率”(检索到相关记忆的比例)保留96%(https://faiss.ai/index.html#benchmarks)。
(2)典型案例:MemGPT分层索引
MemGPT(Memory-GPT)为解决“长时记忆检索效率低”的问题,设计了三级分层索引(https://arxiv.org/pdf/2310.08560):
- 一级索引(类别索引):按记忆类型分类(如“用户偏好”“医疗知识”“任务历史”),快速过滤无关类别;
- 二级索引(语义索引):基于FAISS IVF-PQ构建语义哈希索引,定位语义相似的记忆单元;
- 三级索引(细节索引):存储记忆片段的“关键细节”(如时间戳、关键词),支持精确匹配(如“2024年3月用户提到的过敏史”)。
应用场景:
在医疗咨询场景中,当用户询问“我之前提到的过敏药物有哪些”时,MemGPT通过三级索引:
- 一级索引筛选“用户偏好”类别;
- 二级索引定位“过敏相关”的会话片段;
- 三级索引匹配“2024年3月”的时间戳,最终在10ms内检索到用户过往的过敏药物记录。
官方链接:
- MemGPT分层索引论文《MemGPT: Towards LLMs as Operating Systems》(https://arxiv.org/pdf/2305.14688);
- FAISS IVF-PQ官方文档(https://faiss.ai/cpp_api/file/Structures.h.html#structIVFPQ);
- Milvus长时记忆数据库文档(https://milvus.io/docs/overview.md)。
3.2.3 动态内存调度:协调短时与长时资源
定义:动态内存调度是根据“任务优先级”“内存使用率”“推理延迟要求”,动态分配短时KV缓存与长时内存的资源,平衡“推理性能”与“内存开销”(https://arxiv.org/pdf/2402.10060)。例如,高优先级任务(如医疗诊断)优先分配短时缓存,低优先级任务(如闲聊)可依赖长时内存检索。
(1)核心技术:优先级调度算法
优先级调度算法通过量化“任务紧急度”“记忆重要性”“资源消耗”,为每个内存请求分配优先级,步骤如下(https://arxiv.org/pdf/2402.10060):
- 任务紧急度评分():基于用户需求定义(如医疗任务,闲聊任务);
- 记忆重要性评分():通过记忆强度模型计算(如用户过敏史,过时新闻);
- 资源消耗评分():短时缓存消耗(如128K token需256MB)与长时检索延迟(如8ms)的归一化值;
- 优先级计算:,优先级越高越优先分配短时缓存。
(2)典型案例:Microsoft DynamicMem调度器
Microsoft的DynamicMem调度器(https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/memory-management)通过以下机制实现动态调度:
- 实时监控:持续采集短时缓存使用率(如是否超过80%阈值)、长时检索延迟(如是否超过50ms);
- 触发条件:
- 当短时缓存使用率>90%:淘汰低优先级任务的KV缓存,将其记忆迁移至长时内存;
- 当长时检索延迟>100ms:将高频访问的长时记忆加载到短时缓存;
- 回滚机制:若迁移后任务性能下降(如推理准确率降低>5%),自动恢复原内存分配。
实验效果:
在多任务并发场景(医疗诊断、代码生成、闲聊各100个任务)中,DynamicMem调度器较“静态内存分配”:
- 短时缓存利用率提升32%(从65%至86%);
- 平均推理延迟降低28%(从150ms至108ms);
- 内存溢出率从12%降至0%(https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/memory-management#benchmarks)。
官方链接:
- Microsoft DynamicMem调度器文档(https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/memory-management);
- 优先级调度算法论文《Dynamic Memory Scheduling for Large Language Models》(https://arxiv.org/pdf/2402.10060)。
3.3 工具集成推理系统:扩展LLM的能力边界
LLM本身缺乏“实时计算”(如解方程、数据分析)、“外部交互”(如调用API、操作浏览器)能力,工具集成推理系统通过“函数调用”“环境交互”,让LLM能使用外部工具完成复杂任务(https://arxiv.org/pdf/2205.00445)。核心包括“函数调用机制”“环境交互框架”“强化学习优化”三部分。
3.3.1 函数调用机制:标准化工具接口
定义:函数调用机制是通过“结构化指令”定义工具的输入输出格式,让LLM能自主判断“是否调用工具”“调用哪个工具”“如何处理工具返回结果”(https://openai.com/research/toolformer)。例如,LLM可调用“天气API”获取实时天气,或调用“Python解释器”计算复杂公式。
(1)技术演进:从规则到智能
函数调用机制经历了三代演进,逐步提升LLM的工具使用能力:
演进阶段 | 代表技术 | 核心特点 | 缺陷 |
第一代(2022) | ToolFormer | 预训练时注入工具API描述,LLM学习“何时调用工具” | 仅支持单工具调用,无错误处理 |
第二代(2023) | ReAct | 采用“思考-行动-观察”循环(Think-Act-Observe),支持多步工具调用 | 依赖人工设计提示,泛化性差 |
第三代(2024) | OpenAI JSON函数 | 强制LLM输出JSON格式的函数调用指令,支持标准化多工具协作 | 复杂嵌套调用时错误率较高 |
ReAct机制案例(https://arxiv.org/pdf/2210.03629):
在“查询北京2024年5月平均气温”任务中,ReAct循环步骤如下:
- Think:“我需要获取北京2024年5月的气温数据,这需要调用天气API,需确认API参数(城市、时间范围)”;
- Act:调用天气API,参数为
{"city":"北京","start_date":"2024-05-01","end_date":"2024-05-31"};
- Observe:工具返回“北京2024年5月平均气温为24.5℃”;
- Think:“已获取数据,无需继续调用工具,可直接生成答案”;
- Act:生成自然语言答案“北京2024年5月平均气温为24.5℃”。
(2)训练方法:微调vs提示工程
函数调用能力的训练主要有两种方式,各有优劣:
训练方法 | 实现流程 | 优势 | 劣势 | 适用场景 |
微调(Fine-tuning) | 1. 构建“任务-函数调用-结果”数据集;2. 用数据集微调LLM;3. 部署微调后的模型 | 稳定性高(错误率低)、支持复杂工具 | 成本高(需标注数据)、灵活性差(新增工具需重新微调) | 企业固定场景(如内部API调用) |
提示工程(Prompting) | 1. 在提示中加入工具描述(如API参数、返回格式);2. 示例演示(Few-shot);3. 直接调用LLM | 成本低(无需标注)、灵活性高(新增工具仅需更新提示) | 复杂任务错误率高、依赖LLM基础能力 | 快速原型验证、工具频繁变更场景 |
实验效果:
在“调用计算器解决数学题”任务中,GPT-4的两种训练方式对比(https://openai.com/research/toolformer):
- 微调:函数调用准确率92%,平均解题时间1.2秒;
- 提示工程(5-shot示例):函数调用准确率81%,平均解题时间1.8秒。
官方链接:
- ToolFormer原论文《Toolformer: Language Models Can Teach Themselves to Use Tools》(https://arxiv.org/pdf/2205.00445);
- ReAct原论文《ReAct: Synergizing Reasoning and Acting in Language Models》(https://arxiv.org/pdf/2210.03629);
- OpenAI JSON函数调用文档(https://platform.openai.com/docs/guides/function-calling)。
3.3.2 环境交互框架:从单工具到多工具协作
定义:环境交互框架是定义LLM与“工具集合”“外部环境”的交互规则,支持“单工具深度使用”“多工具协同”“环境状态感知”,适用于复杂任务(如网页爬取、数据分析报告生成)(https://arxiv.org/pdf/2304.09542)。
(1)单工具交互:聚焦特定能力
单工具交互是LLM专注使用一种工具解决任务,核心是“工具能力与任务需求的精准匹配”。典型案例为PAL(Program-Aided Language Models)(https://arxiv.org/pdf/2211.10435),通过生成Python代码调用计算器、数据库等工具。
PAL案例:解决复杂数学题(https://arxiv.org/pdf/2211.10435):
任务:“某商店3月销售额为5万元,4月增长20%,5月较4月下降10%,求5月销售额”。
PAL步骤:
- LLM分析任务:“需先计算4月销售额(3月×1.2),再计算5月销售额(4月×0.9),需调用Python计算器”;
- 生成代码:
march = 50000; april = march * 1.2; may = april * 0.9; print(may);
- 执行工具:调用Python解释器运行代码,返回结果“54000”;
- 生成答案:“5月销售额为5.4万元”。
实验效果:
在GSM8K数学数据集(小学水平)中,PAL(GPT-3.5+Python)的准确率达82.7%,较纯LLM推理(准确率60.1%)提升37.6%(https://arxiv.org/pdf/2211.10435, P6)。
(2)多工具协调:组合能力解决复杂任务
多工具协调是LLM根据任务需求,自主选择多种工具协同工作。典型案例为Chameleon(https://arxiv.org/pdf/2304.09542 ),支持视觉模型(如CLIP)、搜索引擎(如GoogleSearch)、Python解释器的协同。
Chameleon案例:分析“2024年某品牌手机销量与外观设计的关系”(https://arxiv.org/pdf/2304.09542):
任务步骤:
- Think:“需获取2024年该品牌手机销量数据(调用搜索引擎)、手机外观图片(调用图片检索工具)、销量与外观的相关性分析(调用Python数据分析工具)”;
- Act1:调用Google Search,关键词“2024年XX品牌手机销量数据”,获取“Q1销量100万台,Q2销量120万台”;
- Act2:调用图片检索工具,获取Q1/Q2手机外观图片,用CLIP分析“Q2手机新增渐变色设计”;
- Act3:调用Python工具,生成相关性分析代码(如计算销量增长率与外观特征的关联系数),返回“渐变色设计与销量增长正相关(r=0.8)”;
- Observe:整合工具返回结果,生成最终报告。
实验效果:
在“多模态数据分析”任务中,Chameleon较单工具方案,任务完成率从45%提升至78%,结果可信度(数据+逻辑)提升52%(https://arxiv.org/pdf/2304.09542, P12)。
(3)强化学习优化:提升工具使用效率
强化学习(RL) 通过“奖励机制”优化LLM的工具调用策略,减少“无效调用”(如重复调用同一工具)、“错误调用”(如参数错误)。典型案例为ReTool(https://arxiv.org/pdf/2304.03288),基于“工具返回质量”设计奖励函数。
ReTool奖励函数(https://arxiv.org/pdf/2304.03288):
- :工具返回结果是否解决任务(如正确计算答案得1分,错误得0分);
- :调用工具的次数(如1次调用得1分,3次以上得0.2分);
- :工具调用参数是否简洁(如无冗余参数得1分,冗余参数得0.5分)。
实验效果:
在“调用API获取股票数据并计算收益率”任务中,ReTool(GPT-4+RL)的工具调用错误率从28%降至9%,平均调用次数从3.2次降至1.8次(https://arxiv.org/pdf/2304.03288, P8)。
官方链接:
- PAL原论文《Program-Aided Language Models》(https://arxiv.org/pdf/2211.10435);
- Chameleon原论文《Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models》(https://arxiv.org/pdf/2304.09542);
- ReTool原论文《ReTool: Optimizing Tool-Use with Reinforcement Learning》(https://arxiv.org/pdf/2304.03288);
- Google Search API文档(https://developers.google.com/custom-search/v1/overview)。
3.3.3 评估瓶颈:工具集成能力的挑战
尽管工具集成推理系统已取得进展,但在“复杂环境交互”“多工具嵌套调用”中仍存在显著瓶颈,主要体现在GAIA基准测试和嵌套调用错误率上。
(1)GAIA基准测试:人类与LLM的差距
GAIA(General AI Assessment)是衡量LLM工具使用能力的权威基准,包含“需要多步工具调用+跨领域知识”的真实任务(如“预订符合预算的酒店并生成行程”)(https://arxiv.org/pdf/2311.12983)。
GAIA基准测试结果(截至2024年5月):
评估对象 | 任务完成率 | 平均步骤数 | 错误类型 |
人类(熟练用户) | 92% | 4.2步 | 操作失误(8%) |
GPT-4 + 工具集 | 15% | 7.8步 | 工具选择错误(45%)、参数错误(30%) |
Claude 3 + 工具集 | 12% | 8.5步 | 步骤冗余(50%)、结果整合错误(35%) |
关键结论:LLM在“理解任务目标→拆解步骤→选择工具”的逻辑链上仍远逊于人类,尤其在“工具返回结果不符合预期时的调整能力”上存在明显缺陷(https://arxiv.org/pdf/2311.12983, P10)。
(2)嵌套调用错误率:复杂调用的痛点
当工具调用需要“嵌套”(如“调用搜索引擎获取数据→调用Python分析数据→调用可视化工具生成图表”)时,LLM的错误率呈指数级上升。实验显示(https://arxiv.org/pdf/2304.03288):
- 1层调用(单工具):错误率约10%;
- 2层调用(工具A→工具B):错误率升至35%;
- 3层调用(工具A→工具B→工具C):错误率达62%。
错误原因:
- 状态丢失:LLM难以记忆前序工具的返回结果(如忘记工具A获取的数据,导致工具B参数错误);
- 依赖冲突:工具B的输入依赖工具A的输出,但LLM未检查格式兼容性(如工具A返回文本,工具B需JSON格式)。
官方链接:
- GAIA基准测试论文《GAIA: A Benchmark for General AI Assessment》(https://arxiv.org/pdf/2311.12983);
- 嵌套调用错误分析论文《Challenges of Nested Tool Calling in Large Language Models》(https://arxiv.org/pdf/2401.14655)。
3.4 多智能体协作系统:模拟人类团队分工
定义:多智能体协作系统是由多个“专业化LLM智能体”(如医疗智能体、法律智能体、数据分析智能体)组成,通过“标准化通信协议”“动态编排机制”协同完成复杂任务,弥补单一LLM在“跨领域知识”“多步推理”上的不足(https://arxiv.org/pdf/2308.12950)。
3.4.1 通信协议标准化:实现智能体互操作
通信协议是定义智能体间“信息格式”“交互规则”的标准,确保不同智能体(甚至不同厂商开发)能高效协作。核心协议包括MCP(Model Context Protocol) 和A2A(Agent-to-Agent Protocol)。
(1)MCP:模型上下文交互协议
MCP(https://arxiv.org/pdf/2403.16137)是类比“USB-C”的通用AI交互协议,定义了“上下文数据格式”“能力声明”“错误处理”三部分,支持智能体间的上下文共享。
MCP核心格式(JSON示例):
关键功能:
- 能力声明:发送方明确接收方需具备的能力(如“时间序列分析”),避免调用不匹配的智能体;
- 错误处理:定义重试次数与备用智能体,提升系统鲁棒性。
(2)A2A:智能体间协作协议
A2A(https://learn.microsoft.com/en-us/azure/ai-services/agent-studio/concepts/a2a-protocol)是Microsoft推出的智能体协作协议,核心是“能力卡片”与“事务完整性”。
能力卡片:每个智能体需发布“能力卡片”,包含:
- 核心功能(如“法律条款解读”“病例分析”);
- 输入输出格式(如“输入:病例文本;输出:诊断建议JSON”);
- 性能指标(如“响应时间<500ms,准确率>90%”)。
事务完整性:对于多智能体协作任务(如“医疗诊断→处方生成→医保报销计算”),A2A通过“事务日志”记录每个智能体的操作,若某一步失败(如处方生成错误),可回滚至前序状态,避免整体任务失败。
实验效果:
在“跨领域企业咨询”任务(法律合规+财务分析+市场调研)中,采用A2A协议的多智能体系统,任务完成率从58%提升至82%,错误回滚时间从10秒缩短至2秒(https://learn.microsoft.com/en-us/azure/ai-services/agent-studio/concepts/a2a-protocol#benchmarks)。
官方链接:
- MCP协议论文《MCP: A Universal Protocol for Model Context Interaction in Multi-Agent Systems》(https://arxiv.org/pdf/2403.16137);
- Microsoft A2A协议文档(https://learn.microsoft.com/en-us/azure/ai-services/agent-studio/concepts/a2a-protocol);
- OpenAI多智能体通信指南(https://platform.openai.com/docs/guides/multi-agent)。
3.4.2 编排机制:动态调度智能体协作
编排机制是根据“任务需求”“智能体能力”“实时状态”,动态选择智能体、分配任务步骤的核心技术,分为“先验编排”和“后验编排”。
(1)先验编排:预定义协作流程
先验编排是在任务开始前,基于“任务类型→协作流程”的映射,预定义智能体的调用顺序。典型案例为流程化编排器(https://arxiv.org/pdf/2309.07864),适用于固定流程任务(如医疗诊断)。
先验编排案例:医疗诊断流程(https://arxiv.org/pdf/2309.07864):
- 任务分析:用户输入“持续咳嗽、发烧3天”,编排器识别任务类型为“呼吸道疾病诊断”;
- 流程匹配:调用预定义流程“症状采集智能体→影像分析智能体→诊断智能体→处方智能体”;
- 步骤执行:
- 症状采集智能体:获取“咳嗽是否带痰、体温最高值”等细节;
- 影像分析智能体:分析用户上传的胸片;
- 诊断智能体:结合症状与影像,判断为“细菌性肺炎”;
- 处方智能体:生成抗生素处方(需标注用药剂量)。
(2)后验编排:动态调整协作策略
后验编排是在任务执行中,根据“智能体实时反馈”动态调整协作策略,适用于不确定流程任务(如突发公共事件分析)。典型案例为3S协调器(Selection-Scheduling-Supervision)(https://arxiv.org/pdf/2401.12884)。
3S协调器工作流程(https://arxiv.org/pdf/2401.12884):
- Selection(选择):根据任务需求,从智能体库中筛选出候选智能体(如“突发洪水分析”→筛选“水文数据智能体”“交通智能体”“救援智能体”);
- Scheduling(调度):并行调用候选智能体,采集实时数据(如水文智能体返回“水位上涨速度”,交通智能体返回“道路中断情况”);
- Supervision(监督):评估各智能体返回结果的“置信度”(如水文数据置信度95%,交通数据置信度80%),优先基于高置信度数据推进任务;若某智能体结果异常(如置信度<60%),重新调用或替换智能体。
实验效果:
在“突发地震应急响应”任务中,3S协调器较先验编排,任务响应时间从15分钟缩短至5分钟,决策准确率(如救援路线规划)从72%提升至91%(https://arxiv.org/pdf/2401.12884, P11)。
3.4.3 应用场景:多领域落地案例
多智能体协作系统已在医疗健康“网络管理”“企业服务”等领域落地,以下为典型场景:
(1)医疗健康:专科智能体协同诊断
在复杂疾病诊断中(如罕见病),单一医疗智能体难以覆盖所有专科知识,多智能体协作可整合“内科、影像科、基因检测科”等专科能力(https://arxiv.org/pdf/2310.11560)。
案例:罕见病“遗传性血色病”诊断(https://arxiv.org/pdf/2310.11560):
- 内科智能体:根据“疲劳、肝区疼痛”症状,初步怀疑“肝脏疾病”;
- 影像科智能体:分析肝脏MRI,发现“铁沉积”特征;
- 基因检测智能体:解读用户基因报告,确认“HJV基因突变”;
- 综合智能体:整合三专科结果,确诊“遗传性血色病”,并生成治疗方案(如定期放血+铁螯合剂)。
实验效果:
在罕见病诊断数据集(包含1000例病例)中,多智能体协作的诊断准确率达89%,较单一专科智能体(平均准确率65%)提升37%(https://arxiv.org/pdf/2310.11560, P9)。
(2)网络管理:上下文感知资源分配
在大型数据中心网络管理中,多智能体协作可实现“流量监控→故障定位→资源调度”的自动化(https://arxiv.org/pdf/2402.05852)。
案例:数据中心流量拥塞处理(https://arxiv.org/pdf/2402.05852):
- 流量监控智能体:实时采集各服务器的带宽使用率,发现“服务器A→服务器B”链路拥塞;
- 故障定位智能体:分析拥塞原因(如“服务器A的数据库查询请求过多”);
- 资源调度智能体:动态分配额外带宽至该链路,并优化数据库查询队列;
- 监控智能体:持续跟踪拥塞缓解情况,若未缓解则调用“负载均衡智能体”迁移部分请求。
实验效果:
在包含1000台服务器的数据中心中,多智能体系统的拥塞处理时间从30分钟缩短至5分钟,网络吞吐量提升28%(https://arxiv.org/pdf/2402.05852, P10)。
官方链接:
- 医疗多智能体论文《Multi-Agent Collaborative Diagnosis for Rare Diseases》(https://arxiv.org/pdf/2310.11560);
- 网络管理多智能体论文《Context-Aware Multi-Agent Network Management for Data Centers》(https://arxiv.org/pdf/2402.05852);
- 企业服务多智能体案例(https://aws.amazon.com/cn/what-is/multi-agent-ai/)。
四、关键发现与挑战:上下文工程的现状与未来方向
4.1 核心不对称性(Core Asymmetry):理解LLM的能力鸿沟
定义:核心不对称性是指LLM在“上下文理解”(如分析复杂文档、整合多源信息)与“长文本生成”(如撰写报告、规划多步任务)之间的能力鸿沟——LLM能高效理解长上下文,但在生成长文本时易出现“逻辑断裂”“事实矛盾”(https://arxiv.org/pdf/2507.13334)。
4.1.1 三大核心缺陷
- 逻辑连贯性断裂:生成长文本时,LLM难以维持前后逻辑一致。例如,在“撰写产品开发计划”时,前文提到“Q1完成需求分析”,后文却写成“Q1完成原型设计”,忽略时间线冲突。
- 事实一致性下降:生成内容与上下文信息矛盾。例如,上下文明确“产品定价为999元”,但生成的营销文案中写成“售价1299元”,即“遗忘”早期事实。
- 规划深度不足:无法制定复杂的多步规划。例如,在“组织会议”任务中,LLM能生成“确定时间、发送邀请”等基础步骤,但忽略“会议室设备调试、参会者 dietary 需求确认”等细节。
4.1.2 实验证据:能力鸿沟的量化
《A Survey of Context Engineering for Large Language Models》(https://arxiv.org/pdf/2507.13334)通过“延伸思维链”实验量化核心不对称性:
- 任务:让LLM解决“多步数学推理题”,逐步增加推理步骤(从5步增至20步);
- 结果:当步骤≤10时,LLM准确率稳定在85%左右;当步骤>15时,准确率骤降至12%,主要错误为“忘记前序步骤的计算结果”。
另一项“长文本生成质量”实验(https://arxiv.org/pdf/2401.14655)显示:
- 生成文本长度从1000 token增至5000 token时,LLM的“逻辑连贯性评分”(1-5分)从4.2分降至1.8分,“事实一致性评分”从4.5分降至1.5分,呈指数级衰减。
4.1.3 根本原因:LLM的记忆机制限制
核心不对称性的根源在于LLM的“注意力机制与KV缓存设计”:
- 注意力机制局限:Transformer的注意力权重呈“局部集中”特性,即当前token更关注近期token,对早期token的注意力权重随距离增加而显著下降(https://arxiv.org/pdf/1706.03762);
- KV缓存容量限制:短时KV缓存仅能存储有限token(如128K),生成长文本时需“滚动缓存”(淘汰早期token),导致早期信息丢失;
- 生成机制缺陷:LLM采用“自回归生成”(逐token生成),缺乏全局规划能力,无法像人类一样“先搭框架、再填内容”。
4.2 评估困境:上下文工程的度量难题
上下文工程的效果评估面临“组件级评估不全面”“系统级评估缺乏标准”“真实场景适配性差”三大困境,导致难以客观衡量技术方案的优劣(https://arxiv.org/pdf/2507.13334)。
4.2.1 组件级评估:传统指标的局限性
组件级评估聚焦于上下文工程的单一模块(如检索组件、压缩组件),但传统指标(如BLEU、ROUGE、召回率)无法捕捉“推理质量”“逻辑连贯性”等关键维度。
(1)检索组件评估的缺陷
传统检索评估依赖“召回率(Recall)”“精确率(Precision)”,但在LLM场景中,“检索到的知识是否能提升生成质量”才是核心,而非“是否检索到相关文档”。例如:
- 某检索系统的召回率达90%,但检索到的知识包含冗余信息,反而导致LLM生成答案的逻辑混乱,此时高召回率无实际意义。
(2)长上下文处理评估的单一性
长上下文处理的评估多采用“大海捞针”(Needle-in-Haystack)范式(https://arxiv.org/pdf/2309.11495):在长文档中嵌入一个“关键句子”,测试LLM能否找到并利用该句子。但该范式仅评估“信息召回能力”,忽略“长上下文推理”“多信息整合”等复杂能力。
实验对比:
在“大海捞针”任务中,LongRoPE(2048K窗口)的关键句子召回率达98%,但在“长文档摘要+逻辑分析”任务中,其摘要的“逻辑连贯性评分”仅为2.8分(5分制),说明单一召回率指标无法反映实际性能(https://arxiv.org/pdf/2309.11495, P12)。
4.2.2 系统级评估:缺乏统一标准
系统级评估需衡量上下文工程端到端的效果(如RAG系统、多智能体系统),但目前缺乏统一的评估基准与指标,导致不同方案的对比困难。
(1)多智能体协作评估的空白
多智能体系统的评估多依赖“自定义任务”(如特定领域的诊断任务),缺乏通用基准。例如:
- 某论文采用“医疗诊断”任务评估多智能体系统,准确率达89%;另一论文采用“网络管理”任务,准确率达82%,但二者无法直接对比,因任务难度、数据分布差异大。
(2)商业助手评估的挑战
商业LLM助手(如ChatGPT Memory、Gemini Advanced)的“长会话记忆”能力缺乏标准化评估。LongMemEval基准(https://arxiv.org/pdf/2402.10060)的实验显示:
- 商业助手在10轮以内的短会话中,准确率达90%;但在50轮以上的长会话中,准确率下降至60%,主要错误为“混淆用户过往偏好”。但该基准尚未成为行业标准,不同厂商的评估结果缺乏可比性。
4.2.3 典型案例:WebAgent评测的现状
WebAgent是指能操作浏览器完成复杂任务(如购物、预订、信息采集)的LLM系统,其评估反映了上下文工程在“动态环境交互”中的挑战(https://arxiv.org/pdf/2401.12884)。
WebAgent评测结果(截至2024年5月):
模型/系统 | 是否开源 | 复杂网页任务成功率 | 主要失败原因 |
IBM CUGA | 否 | 61.7% | 复杂表单填写错误(如日期格式) |
OpenAI Operator | 否 | 58.1% | 动态网页元素识别失败(如弹窗) |
GPT-4 + 浏览器 | 是 | 23.5% | 多步操作逻辑断裂(如忘记登录) |
Claude 3 + 浏览器 | 否 | 28.3% | 工具调用参数错误(如URL拼写错误) |
关键结论:即使是最先进的WebAgent,在“复杂网页交互”(如多步骤表单、动态弹窗、登录验证)中的成功率仍低于65%,远未达到实用水平,反映出上下文工程在“动态环境状态管理”“多步操作逻辑维持”上的不足(https://arxiv.org/pdf/2401.12884, P14)。
官方链接:
- LongMemEval基准论文《LongMemEval: Evaluating Long-Term Memory in Large Language Models》(https://arxiv.org/pdf/2402.10060);
- WebAgent评测论文《Evaluating Web Agents for Complex Tasks》(https://arxiv.org/pdf/2401.12884);
- Needle-in-Haystack评估工具(https://github.com/gkamradt/LLMTest_NeedleInHaystack)。
4.3 技术瓶颈:上下文工程的核心障碍
尽管上下文工程已取得显著进展,但在“长度扩展”“内存管理”“多模态融合”“不确定性处理”等方面仍存在技术瓶颈,限制其在复杂场景的落地。
4.3.1 长度扩展瓶颈:Transformer的O(n²)复杂度
LLM的上下文长度扩展受限于Transformer注意力机制的O(n²)时间复杂度与O(n)空间复杂度(n为上下文长度):
- 时间复杂度:当n从1K增至128K时,注意力计算量从10⁶次增至1.6×10¹⁰次(16384倍增长),推理时间呈平方级增加;
- 空间复杂度:KV缓存的存储空间随n线性增长,n=128K时,70B模型的KV缓存需约256MB(float16精度),n=1M时需约2GB,若采用多模态输入(如图像、音频),空间需求进一步激增。
现有解决方案的局限:
- SSM(如Mamba):虽实现O(n)复杂度,但在“长文本逻辑推理”任务中,性能较Transformer低15-20%(https://arxiv.org/pdf/2312.00752);
- 稀疏注意力(如S²-Attn):虽减少计算量,但“稀疏度选择”依赖人工调参,在不同任务中泛化性差(https://arxiv.org/pdf/2401.13669)。
4.3.2 内存管理瓶颈:KV缓存与长时记忆的协同
内存管理的瓶颈体现在“短时KV缓存溢出”与“长时记忆检索延迟”的矛盾:
- 短时KV缓存溢出:当处理长会话(如100轮以上)时,KV缓存需持续存储历史token,若内存不足,需淘汰早期token,导致“上下文信息丢失”;
- 长时记忆检索延迟:为避免KV缓存溢出,需将部分记忆迁移至长时内存,但长时检索(如FAISS IVF-PQ)的延迟通常为5-10ms,若频繁检索,会显著增加整体推理延迟。
- 在128K token的长会话任务中,若不淘汰KV缓存,70B模型需140GB GPU内存(超出单张A100 GPU的80GB容量);
- 若淘汰50%的早期token,推理延迟降低30%,但生成答案的“事实一致性”从85%降至62%。
4.3.3 多模态融合瓶颈:模态偏见与信息异构
多模态上下文融合(文本+图像+音频+结构化数据)面临“模态偏见”与“信息异构”两大挑战:
- 模态偏见:LLM天然偏向文本信息,忽略其他模态的关键细节。例如,在“图像描述+文本说明”任务中,LLM有78%的概率仅基于文本生成答案,忽略图像中的矛盾信息(https://arxiv.org/pdf/2103.00020);
- 信息异构:不同模态的信息格式差异大(如文本是序列、图像是像素矩阵、知识图谱是图结构),难以统一表示。例如,LLM能理解文本描述的“红色苹果”,但难以将图像中的“红色苹果”与知识图谱中的“苹果-营养成分”三元组关联。
现有解决方案的局限:
- Cross-Modal Attention:虽能融合多模态信息,但计算复杂度高(O(n×m),n为文本长度,m为图像token数),在长多模态上下文任务中难以应用(https://arxiv.org/pdf/2304.09542);
- 统一模态Embedding(如CLIP):虽能将文本与图像映射到同一向量空间,但在“复杂推理”任务中,向量表示的语义粒度不足,无法捕捉细节信息(如图像中的“产品缺陷”)。
4.3.4 不确定性处理瓶颈:模糊信息与噪声干扰
上下文工程常面临“信息模糊”(如用户模糊需求)与“噪声干扰”(如检索到错误知识),但LLM缺乏有效的不确定性处理机制:
- 信息模糊:当用户需求不明确(如“推荐一款好手机”)时,LLM难以通过上下文工程动态澄清需求(如询问“预算、用途”),常生成泛泛的答案;
- 噪声干扰:当检索到错误知识(如“2024年GDP增长率为10%”,实际为5%)时,LLM无法识别噪声,反而基于错误信息生成答案,即“幻觉强化”。
- 在“模糊需求”任务中,仅23%的LLM会主动询问用户补充信息,其余77%直接生成答案,用户满意度仅35%;
- 在“含噪声检索知识”任务中,LLM基于错误知识生成答案的概率达89%,仅11%能识别并忽略噪声。
4.4 未来方向:上下文工程的突破路径
针对上述挑战,上下文工程的未来发展将聚焦于“架构创新”“评估体系完善”“多模态融合优化”“不确定性量化”四大方向。
4.4.1 架构创新:超越Transformer的长上下文能力
- 动态注意力架构:设计“注意力权重自适应调整”机制,根据任务需求聚焦关键token(如推理任务聚焦公式,叙事任务聚焦情节),进一步降低计算复杂度;
- 内存计算融合:将“内存存储”与“计算推理”结合,如在KV缓存中直接进行部分推理计算(如求和、比较),减少数据搬运延迟;
- 分层推理架构:借鉴人类“短期记忆-工作记忆-长期记忆”的认知模型,设计“分层上下文处理架构”,工作记忆负责实时推理,长期记忆负责知识存储,短期记忆负责临时交互。
4.4.2 评估体系完善:构建通用、全面的基准
- 多维度评估指标:建立“推理质量”“逻辑连贯性”“事实一致性”“效率”的多维度指标体系,替代单一的召回率、准确率;
- 真实场景基准库:构建覆盖“医疗、法律、工业”等领域的真实场景基准库,包含“长会话、动态环境、模糊需求”等复杂任务,确保评估结果的实用性;
- 动态评估框架:设计“任务难度动态调整”的评估框架,根据LLM的性能实时增加任务复杂度(如增加推理步骤、加入噪声),更精准衡量能力边界。
4.4.3 多模态融合优化:统一表示与模态均衡
- 跨模态知识图谱:构建“文本-图像-音频-结构化数据”的跨模态知识图谱,通过“实体关联”(如文本“苹果”→图像“红色苹果”→知识图谱“苹果-营养”)实现统一表示;
- 模态均衡学习:设计“模态重要性量化”机制,避免LLM偏向文本,确保各模态信息被平等利用(如医疗任务中,影像模态与文本病历权重相同);
- 多模态蒸馏:将多模态信息蒸馏为“紧凑向量表示”,在降低存储成本的同时,保留关键语义信息。
4.4.4 不确定性量化:从定性到定量的噪声处理
- 噪声检测模型:训练“噪声识别LLM”,专门用于检测检索知识、用户输入中的噪声,输出“置信度评分”(如某知识的可信度为30%);
- 不确定性传播模型:量化“模糊需求”“噪声知识”对输出结果的影响,如“基于可信度30%的知识,答案的不确定性为60%”,并向用户提示风险;
- 动态澄清机制:设计“需求模糊度量化”模型,当模糊度超过阈值时,自动触发澄清流程,询问用户补充信息,提升答案精准度。
五、总结:上下文工程——LLM性能突破的核心引擎
大型语言模型的发展已从“参数竞赛”进入“上下文驱动”时代,上下文工程通过“动态结构化信息组件的设计、检索、组装、优化”,成为决定LLM任务性能的关键。本文系统解析了上下文工程的核心概念(数学形式化定义、与提示工程的区别)、基础组件(检索与生成、处理、管理)、系统架构(RAG、内存管理、工具集成、多智能体协作),并深入分析了核心不对称性、评估困境、技术瓶颈与未来方向。
上下文工程的价值不仅在于“提升LLM的任务准确率”,更在于“扩展LLM的能力边界”——从单一文本生成,到“长上下文推理、多工具协作、多智能体协同、多模态融合”的复杂智能系统。尽管当前面临“Transformer复杂度、内存管理、多模态偏见”等挑战,但随着架构创新、评估体系完善与技术优化,上下文工程将推动LLM从“通用语言模型”进化为“通用智能系统”,在医疗、工业、法律等领域实现更深度的落地应用。
对于AI开发者与研究者,上下文工程的实践需关注三大核心:
- 以任务为中心:根据任务需求(如推理、生成、交互)选择合适的上下文组件(如CoT提示、RAG检索、长时记忆);
- 平衡性能与效率:在“上下文质量”与“推理延迟、内存开销”间寻找平衡,避免过度追求长上下文而忽视实用性;
- 重视不确定性:在医疗、法律等关键领域,需量化上下文信息的不确定性,避免基于模糊或错误信息生成决策。
未来,随着上下文工程技术的成熟,LLM将真正具备“理解复杂需求、整合多源知识、动态适应环境”的能力,成为人类在复杂任务中的核心协作伙伴。