背景与核心要素
在分布式系统、高并发服务的日常运维与演进过程中,限流(Rate Limiting)始终是最核心、最复杂、也最容易被低估的稳定性手段之一。它既不像缓存那样立竿见影,也不像熔断那样“一刀切”直接拒绝,而是在流量洪峰与系统承载力之间寻找一条动态可持续的“细线”。
限流,顾名思义,就是限制流量的速度和规模,确保系统在可控范围内提供服务。它就像商场入口的保安,在人流过多时会引导大家有序进入,避免拥挤踩踏;又像高速公路的收费站,通过调节放行速度防止道路拥堵。在分布式系统架构中,限流是保障系统稳定性的最后一道防线,即使有缓存、消息队列、负载均衡等中间件的加持,没有合理的限流策略,系统依然可能在流量洪峰面前不堪一击。
本指南将带你系统学习四种经典限流算法:固定窗口、滑动窗口、令牌桶和漏桶。我们将从算法思想出发,深入剖析实现原理,提供可直接运行的代码示例,分析各自的优缺点,并结合实际应用场景,帮你构建完整的限流知识体系。无论你是刚接触高并发的新手,还是希望深入理解限流机制的资深开发者,这份指南都能为你提供清晰的学习路径和实用的技术参考。
1.1 为什么需要限流?
在数字洪峰时代,瞬时流量可能百倍于日常均值。没有限流的系统就像没有闸门的大坝,随时可能因流量过载而“溃坝”。限流的核心目标体现在三个维度:
- 可用性:防止 CPU、内存、线程、连接池等核心资源被瞬间耗尽,避免系统崩溃。
- 公平性:避免少数用户、IP 或大请求占用过多资源,导致其他正常请求被“饿死”。
- 可控性:为弹性伸缩、熔断、降级等其他稳定性策略提供流量数据支撑,形成协同防御体系。
1.2 什么是限流?
限流(Rate Limiting)是指通过控制单位时间内允许通过的请求数量,保护系统免受流量过载影响的技术手段。它的核心目标是:
- 防止系统因流量过大而崩溃或响应超时;
- 保证系统在承载范围内提供稳定、可预期的服务质量;
- 实现资源的合理分配和调度,优先保障核心业务;
- 为不同优先级的请求提供差异化服务,最大化用户体验。
限流不是简单的“一刀切”拒绝请求,而是一种精细化的流量治理策略。一个好的限流系统应该像智能交通信号灯,既能保证道路(系统资源)畅通,又能在高峰期合理调控车流(请求),避免拥堵。
1.3 核心要素四维模型
限流系统的设计需围绕四个核心维度展开,它们共同决定了限流策略的有效性和适用性:
维度 | 说明 | 举例 | 关键考量 |
限流对象 | 明确对“谁”实施限流 | 用户 ID、IP、接口、下游服务 | 粒度需平衡(过粗不公平,过细耗资源) |
限流维度 | 明确按“什么指标”计量流量 | QPS、并发数、带宽、连接数 | 需匹配系统瓶颈(CPU 瓶颈用 QPS,连接瓶颈用连接数) |
算法 | 明确如何控制流量速率 | 固定窗口、滑动窗口、令牌桶、漏桶 | 需结合业务对“突发流量”的容忍度 |
触发策略 | 明确流量超过阈值后如何处理 | 拒绝、排队、降级、异步化 | 需区分请求优先级(核心请求优先处理) |
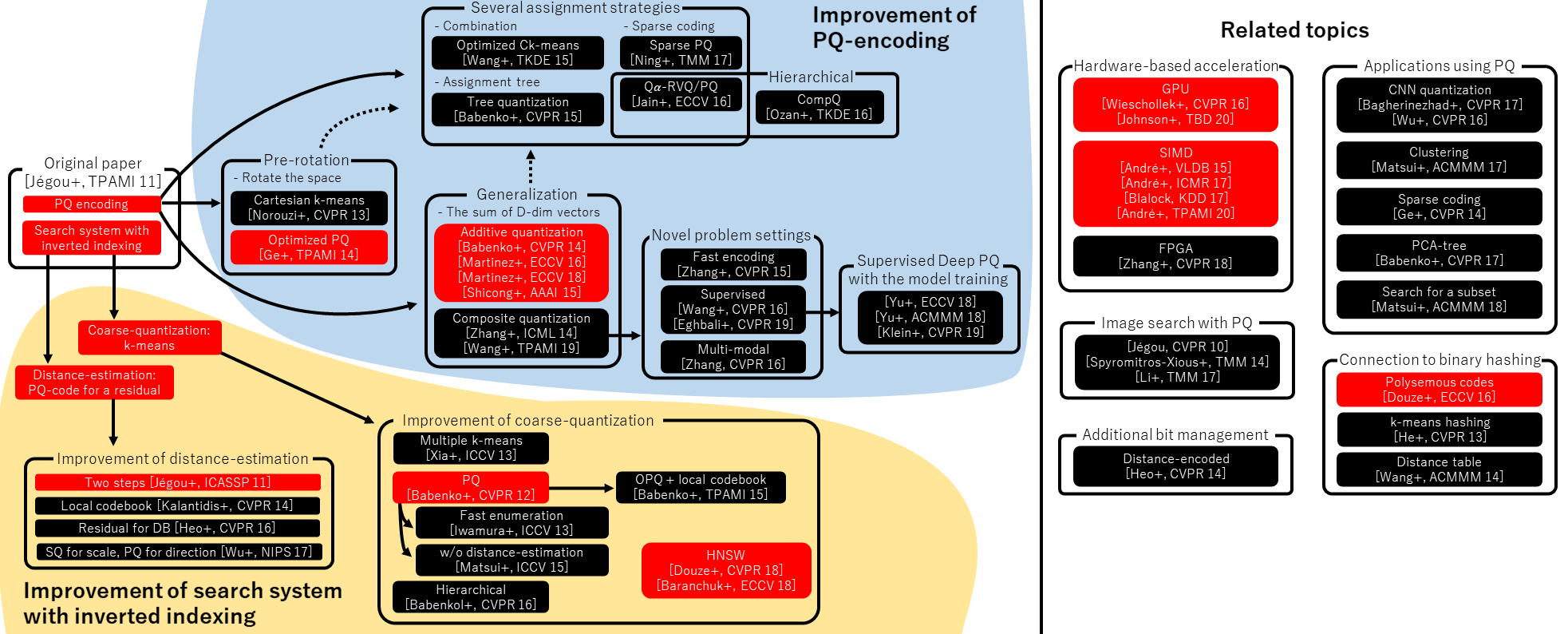
算法总览与选型
限流算法按特性可分为静态算法和动态算法。静态算法基于固定规则控制流量,实现简单且适用场景广泛;动态算法则会根据系统实时状态调整策略,复杂度更高,常用于精细化流量治理。
2.1 算法分类
- 静态算法:
- 固定窗口:按固定时间片计数,实现最简单但精度较低。
- 滑动窗口:将固定窗口拆分为子窗口,通过滑动计算流量,平衡精度与复杂度。
- 令牌桶:以固定速率生成令牌,请求需获取令牌才能通过,支持突发流量。
- 漏桶:请求先进入桶中,桶以固定速率处理请求,输出流量绝对平滑。
- 动态算法:
- BBR/Vegas:基于系统实时负载(如延迟、吞吐量)动态调整限流阈值,适用于复杂网络场景。
2.2 算法核心特性对比
算法 | 准确性 | 平滑性 | 突发支持 | 实现复杂度 | 资源消耗 |
固定窗口 | 低(临界问题) | 低(窗口切换可能突增) | 不支持 | 极低 | 极低 |
滑动窗口 | 中(依赖子窗口数量) | 中(子窗口越多越平滑) | 有限支持 | 中 | 中 |
令牌桶 | 高 | 中(允许突发) | 支持(桶容量决定) | 中 | 低 |
漏桶 | 高 | 高(绝对平滑) | 不支持 | 中 | 中(需队列存储) |
2.3 选型决策矩阵
场景描述 | 推荐算法 | 核心理由 |
API 网关统一入口,允许短期流量突发 | 令牌桶 | 支持 burst 流量,且长期速率可控 |
短信/邮件网关,需严格控制下游压力 | 漏桶 | 输出流量绝对平滑,避免下游过载 |
内部管理系统,流量低且精度要求不高 | 固定窗口 | 实现简单,开发维护成本低 |
秒杀/支付核心接口,需高精度流量控制 | 滑动窗口 | 子窗口机制可减少流量波动,精度高 |
网络传输场景,需动态适配链路状态 | BBR | 基于实时延迟调整,适配复杂网络 |
固定窗口 Fixed Window
3.1 核心思想
将时间划分为固定长度的窗口(如 1 秒),每个窗口内维护一个计数器,记录请求数量。当请求到达时,若当前窗口计数器未超过阈值,则允许通过并递增计数器;若超过阈值,则拒绝请求。窗口结束时,计数器清零并开启新窗口。
适用场景:内部低流量服务、对精度要求不高的场景(如后台管理系统接口)。
3.2 核心公式
设:
- 为窗口内允许的最大请求数(限流阈值),即
- 为窗口大小(单位:毫秒),即
- 为当前窗口的开始时间(单位:毫秒)
- 为当前请求到达时间(单位:毫秒)
- 为当前窗口内的请求计数(截至时间 的累计请求数)
1. 窗口有效性判断
当前时间 处于当前窗口内的条件:
若不满足,则触发窗口重置,更新窗口开始时间:
2. 请求允许通过条件
当请求在当前窗口内时,允许通过的判定公式:
通过后计数递增:
3. 完整逻辑公式化表达
其中,窗口重置操作满足:
3.3 临界问题与缺陷
固定窗口的最大问题是临界突发:在两个相邻窗口的边界处,可能出现超过阈值的流量。例如,窗口大小 1 秒,阈值 100:
- 第 0.9 秒收到 100 个请求(计数器=100,允许通过);
- 第 1.1 秒收到 100 个请求(进入新窗口,计数器=100,允许通过);
- 实际 0.2 秒内通过 200 个请求,远超阈值,但算法无法识别。
3.4 单机实现
3.5 分布式实现(Redis+Lua)
分布式场景下,需通过中心化存储(如 Redis)共享窗口状态,利用 Lua 脚本保证操作原子性:
3.6 优缺点总结
优点 | 缺点 |
实现简单,开发成本低 | 存在临界突发问题 |
资源消耗极低(仅需计数器) | 流量控制精度低 |
分布式实现简单(Redis 单 key) | 无法平滑处理窗口切换流量 |
滑动窗口 Sliding Window
4.1 核心思想
将固定窗口拆分为多个连续的子窗口(如 1 秒窗口拆分为 10 个 100ms 子窗口),每个子窗口独立计数。当时间滑动时,丢弃过期的子窗口,累加剩余子窗口的计数作为当前流量。子窗口数量越多,流量计算越精细,平滑性越好,但资源消耗也越高。
适用场景:对精度有一定要求的场景(如秒杀接口、支付接口)。
4.2 核心公式
设:
- 为大窗口大小(单位:毫秒),即
- 为子窗口数量,即
- 为子窗口大小(单位:毫秒),满足
- 为当前请求到达时间(单位:毫秒)
- 当前时间窗口范围为闭区间:
- 表示第 个子窗口,其时间范围为 为起始时间, 为结束时间)
- 为第 个子窗口的请求计数(即 内的请求数)
1. 有效子窗口判定
子窗口 属于有效子窗口的条件:其时间范围与当前时间窗口范围有交集,即:
2. 总请求数计算
所有有效子窗口的请求计数之和:
3. 请求允许通过条件
设限流阈值为 \( L \)(即 \( \text{limit} = L \)),则允许通过的判定公式:
4. 子窗口时间范围特性
由于子窗口连续且覆盖整个大窗口,满足:
即前一个子窗口的结束时间等于后一个子窗口的起始时间,且所有子窗口的并集为大窗口范围。
4.3 单机实现(基于数组环)
4.4 分布式实现(Redis+ZSET)
分布式场景下,用 ZSET 存储请求时间戳,通过范围查询计算有效请求数:
4.5 优缺点总结
优点 | 缺点 |
精度高于固定窗口 | 子窗口越多,计算成本越高 |
减少临界突发问题 | 分布式实现需存储所有请求时间戳,内存消耗较高 |
流量平滑性可通过子窗口数量调节 | 子窗口数量需提前规划(过多浪费资源,过少精度不足) |
令牌桶 Token Bucket
5.1 核心思想
系统维护一个固定容量的令牌桶,以固定速率(如 r 个/秒)向桶中添加令牌。当令牌数达到桶容量时,多余令牌会被丢弃。请求到达时,需从桶中获取 1 个(或多个)令牌,若获取成功则允许通过;若令牌不足,则拒绝请求或排队等待。
令牌桶的核心优势是支持突发流量:当桶中积累了足够令牌时,可一次性处理大量请求(最多不超过桶容量),但长期平均速率不会超过令牌生成速率。
适用场景:API 网关、允许短期流量波动的服务(如电商商品详情接口)。
5.2 核心公式
设:
- 为桶容量(最大令牌数),即
- 为令牌生成速率(单位:令牌/秒),即
- 为上次令牌更新时间(单位:秒),即
- 为当前请求到达时间(单位:秒),即
- 为当前令牌数(初始值为),即
- 为当前请求所需令牌数(默认值为 1)
1. 新增令牌数计算
基于时间差生成的新令牌数:
2. 更新令牌数
令牌数不能超过桶容量,更新公式:
3. 请求允许通过条件
当令牌数满足请求需求时允许通过:
4. 扣减令牌与更新时间
通过后扣减令牌并更新上次时间:
完整逻辑公式化表达
5.3 单机实现(无锁优化)
5.4 分布式实现(Redis+Lua)
分布式场景下,用 Hash 存储桶状态(当前令牌数、上次更新时间):
5.5 优缺点总结
优点 | 缺点 |
支持突发流量(桶容量范围内) | 分布式实现需处理时钟同步问题 |
长期速率可控(不超过生成速率) | 令牌数为浮点数,精度有限 |
实现简单,资源消耗低 | 无法严格保证流量平滑性 |
漏桶 Leaky Bucket
6.1 核心思想
系统维护一个固定容量的漏桶,请求到达时先进入桶中等待。桶以固定速率(如 r 个/秒)“漏水”(处理请求),若桶已满则新请求被拒绝。漏桶的核心特性是输出流量绝对平滑,无论输入流量如何波动,输出速率始终稳定。
适用场景:需严格控制下游服务压力的场景(如短信网关、第三方 API 调用)。
6.2 核心公式
设:
- 为桶容量(最大可容纳请求数),即
- 为漏水速率(单位:请求/秒),即
- 为时刻 桶内的请求数,即
- 为新请求到达时刻
1. 请求进入判定
新请求到达时,若桶未满则允许进入(计数递增),否则拒绝:
2. 漏水逻辑(连续时间模型)
漏水过程可表示为请求数随时间的递减函数,满足:
- 漏水间隔:(秒/请求),即每 时间处理 1 个请求
- 任意时刻 的桶内请求数:
其中 为上一次漏水时刻, 表示向下取整(计算时间段内的漏水量)
3. 离散时间模型简化
若以固定时间间隔触发漏水(如定时任务),设每次漏水处理 1 个请求,则:
核心约束
无论请求进入速率如何变化,单位时间内的最大漏水量(处理请求数)恒为 ,即:
6.3 单机实现(两种模式)
漏桶有两种实现模式:定时漏水(基于定时任务主动处理请求)和惰性漏水(请求到达时计算应漏水量)。
模式 1:定时漏水(基于 ScheduledExecutorService)
模式 2:惰性漏水(请求到达时计算漏水量)
6.4 分布式实现(Redis+List+Lua)
分布式场景下,用 List 存储待处理请求,通过 Lua 脚本控制入桶和漏水逻辑:
6.5 优缺点总结
优点 | 缺点 |
输出流量绝对平滑 | 不支持突发流量(桶满即拒) |
严格保护下游服务 | 需维护队列存储请求,资源消耗较高 |
实现逻辑直观 | 定时漏水模式可能有精度误差 |
分布式实现要点
单机限流仅需控制单个实例的流量,而分布式限流需协调多个实例的状态,面临一致性、时钟同步等挑战。
7.1 数据一致性保障
- 单 key 原子性:Redis Lua 脚本支持将多个命令打包执行,天然保证原子性(如令牌桶的状态更新)。
- 多实例竞争:若需跨 key 协调(如全局阈值),可使用 RedLock 或 Zookeeper 分布式锁,但会增加延迟。
- 最终一致性:允许短期不一致(如各实例本地缓存阈值),通过定期同步保证长期一致。
7.2 时钟同步问题
- 分布式场景下,各实例时钟可能存在偏差,应以 Redis 服务器时间为准(通过
TIME命令获取)。
- 令牌桶、滑动窗口等依赖时间计算的算法,需在 Lua 脚本中统一使用 Redis 时间,避免实例时钟偏差导致的误差。
7.3 热点 key 优化
- 高并发场景下,单个限流 key 可能成为 Redis 瓶颈,需通过哈希分片打散压力:
- 分片后需在客户端汇总各分片的计数,再判断是否超过总阈值。
阈值计算方法论
合理的限流阈值是限流效果的核心,需结合系统承载能力、业务场景和流量特征综合计算。
8.1 黄金标准:全链路压测
通过全链路压测获取系统极限 QPS,结合安全系数确定阈值:
其中:
- QPS_max:压测中系统稳定运行的最大 QPS(未出现明显延迟或错误)
- safety_factor:安全系数,通常取 0.7~0.9(核心服务取高值,非核心取低值)
8.2 无压测时的四阶梯法
- 历史监控法:基于历史峰值流量推算,适用于已有稳定运行的服务:
- 兄弟系统参考法:参考同规格、同业务类型的系统阈值,结合自身硬件差异调整:
- 理论估算法:基于系统响应时间和 CPU 核心数估算:
- 动态调优法:上线后根据实际运行状态微调:
- 若 P99 延迟 > 500ms 且限流比例 < 1%,降低阈值 10%;
- 若限流比例 > 5% 且 P99 延迟 < 200ms,提高阈值 10%。
性能压测与监控
限流策略上线前需通过压测验证效果,上线后需实时监控关键指标,确保限流生效且不影响正常服务。
9.1 压测工具与脚本
- wrk 压测示例(测试接口限流效果):
- JMeter 压测:适合复杂场景(如混合请求类型、带认证的接口),可自定义限流阈值验证用例。
9.2 关键监控指标
指标 | 含义 | 计算公式 | 告警阈值建议 |
qps | 实时请求量 | 单位时间内通过的请求数 | — |
throttle_rate | 限流比例 | 限流请求数 / 总请求数 | > 5% 持续 1 分钟 |
p99_latency | 99分位响应时间 | 99%的请求响应时间 ≤ 该值 | > 500ms 持续 30 秒 |
cpu_util | CPU 利用率 | 平均 CPU 使用率 | > 80% 持续 1 分钟 |
queue_size(漏桶) | 漏桶队列长度 | 当前待处理请求数 | > 容量的 80% |
常见误区与最佳实践
10.1 典型误区
- 误区1:全局单一阈值
风险:核心接口可能被非核心流量挤占。
正解:按业务优先级分级限流(如支付接口阈值 > 商品浏览接口)。
- 误区2:阈值写死在代码
风险:无法应对流量波动,需重启服务调整。
正解:通过配置中心(如 Nacos、Apollo)动态更新阈值,支持热生效。
- 误区3:限流后统一返回 429
风险:高优先级请求(如 VIP 用户)体验差。
正解:区分优先级,高优先级请求排队等待,低优先级直接拒绝。
- 误区4:忽略请求大小差异
风险:大请求(如批量导入)可能耗尽资源。
正解:按请求大小分级,大请求单独限流或采用并发数维度控制。
10.2 最佳实践
- 多层限流协同:网关层粗粒度限流 + 服务层细粒度限流(如网关限 IP,服务限用户 ID)。
- 限流标识设计:采用“业务+对象+维度”三元组(如
rate:order:user:123:qps),便于精细化控制。
- 失败降级策略:限流后返回缓存数据或默认值,避免直接返回错误(如商品详情限流后返回基础缓存信息)。
- 灰度发布:新限流策略先在低流量实例灰度,验证无误后全量推广。
总结
限流是高并发系统的“安全阀”,其核心价值不在于“限”,而在于“控”——通过合理的算法和策略,让系统在流量波动中保持稳定。四种经典静态算法各有侧重:
- 固定窗口适合简单场景,追求极致简洁;
- 滑动窗口平衡精度与成本,适合中等要求场景;
- 令牌桶支持突发流量,适合网关等入口场景;
- 漏桶保证输出平滑,适合下游保护场景。
限流的终极目标是构建“观测→计算→保护→调优”的闭环体系。记住:没有万能的算法,只有适合业务的策略,需结合压测数据、实时监控和业务优先级,持续优化限流方案,让系统在稳定性与用户体验之间找到最佳平衡点。