面向研发的 Agent 驱动工程框架
📖 项目简介
Java Harness Agent 是一套 Agent 驱动流程,架起了自然语言需求与生产级后端代码之间的桥梁。基于意图网关、生命周期状态机、知识图谱(LLM Wiki)和专业技能矩阵,实现了可持续演进、可断点续传、可自我纠偏、防膨胀的工程闭环。
✨ 核心特性
- 🎯 意图驱动:自然语言 → 结构化意图队列 → 可执行任务
- 🔄 生命周期状态机:Explorer → Propose → Review → Approval → Implement → QA → Archive
- 🧠 知识图谱:分层 Wiki 系统,支持双向导航
- 🛡️ 自我纠偏:自动守卫钩子、失败恢复、人类介入检查点
- 📊 契约先行:基于 OpenSpec 的设计优先于实现
- 🔌 技能矩阵:25+ 专业技能提供领域专家能力
- 📈 防膨胀机制:自动知识提取与归档,防止信息过载
✨ 核心特性深度解析
Java Harness Agent 的核心竞争力在于其四大核心特性的深度融合,每个特性都针对后端研发的具体痛点设计,形成了相互支撑、协同工作的完整体系。
1. 🎯 意图驱动:让需求落地更精准
意图驱动是Java Harness Agent 的核心设计理念,其核心目标是解决“自然语言需求与技术实现脱节”的问题。传统研发中,产品需求(PRD)往往是自然语言描述,研发人员需要花费大量时间理解需求、拆解需求、转化为技术方案,过程中容易出现需求偏差、理解不一致等问题。
Java Harness Agent 通过“意图网关”组件,将自然语言需求转化为结构化的意图队列,再将意图队列映射为可执行的研发任务,实现了“需求→意图→任务”的标准化转化。具体流程如下:
- 用户输入自然语言需求(如“新增一个查询用户信息的接口,支持按用户ID和手机号查询,返回用户基本信息和角色列表”);
- 意图网关接收需求后,结合LLM Wiki知识图谱中的上下文信息,对需求进行解析、拆分,提取核心意图(如“新增查询接口”“支持多条件查询”“返回指定字段”);
- 将核心意图整理为结构化的意图队列,明确每个意图的优先级、依赖关系和执行标准;
- 意图队列作为生命周期引擎的输入,引导研发流程按步骤推进,确保每个意图都能落地为具体的技术实现。
这种意图驱动的模式,不仅减少了需求理解的偏差,还让研发过程更具针对性,避免了“做无用功”,同时也为团队协作提供了统一的需求基准——所有研发人员都围绕同一套意图队列开展工作,确保方向一致。
2. 🔄 生命周期状态机:让研发流程更可控
后端研发是一个复杂的过程,涉及需求分析、方案设计、代码实现、测试验证、归档沉淀等多个环节,传统研发中,这些环节往往缺乏标准化的流转机制,容易出现流程混乱、环节遗漏、责任不清等问题。
Java Harness Agent 引入了“生命周期状态机”组件,将研发过程划分为7个标准化阶段,形成了“Explorer → Propose → Review → Approval → Implement → QA → Archive”的单向流转机制,每个阶段都有明确的目标、产出物和校验标准,确保研发流程可控、可追溯。
每个阶段的详细说明如下:
- Explorer(探索阶段):澄清需求边界、定义研发范围、识别潜在风险,产出《探索报告》,明确需求的目标、非目标、跨域影响面和异常分支;
- Propose(设计阶段):基于探索阶段的结论,设计技术方案,冻结API契约、数据模型、业务流程等,产出《OpenSpec契约文档》,作为后续研发的唯一依据;
- Review(评审阶段):对设计方案进行自动化技术评审,检查是否符合架构标准、API规范、SQL性能要求等,若评审不通过,返回Propose阶段修订;
- Approval(确认阶段):人类介入检查点,由研发负责人确认设计方案是否可行,冻结契约,授权进入实现阶段,同时为前端、QA等协作方提供契约依据;
- Implement(实现阶段):按照OpenSpec契约,在规范边界内实现代码,遵循Java工程标准、防御性编程指南,确保代码质量;
- QA(测试阶段):遵循TDD原则,进行单元测试、回归测试,确保代码功能符合需求,关键路径测试覆盖率达到100%,若测试失败,返回Implement阶段修复;
- Archive(归档阶段):提取研发过程中的稳定知识,更新LLM Wiki知识图谱,将OpenSpec契约、测试用例等归档,清理临时文件,完成研发闭环。
生命周期状态机的引入,让后端研发从“无序流转”转变为“标准化流转”,每个阶段的产出物都可追溯,每个环节的责任都可明确,有效降低了研发过程中的风险,提升了研发效率。
3. 🧠 知识图谱(LLM Wiki):让知识沉淀更高效
后端研发过程中,会产生大量的知识,包括API规范、数据模型、业务逻辑、架构决策、测试用例等,传统研发中,这些知识往往分散在代码注释、文档、团队成员的经验中,难以复用和传承,导致新人上手慢、老员工离职后知识流失等问题。
Java Harness Agent 构建了基于LLM Wiki的知识图谱,以Sitemap为根节点,形成分层、可导航、可演进的知识体系,实现了知识的集中管理、快速检索和自动沉淀。其核心设计特点如下:
- 分层结构:知识图谱分为根节点(Sitemap)、规范层(Schema)、活跃知识层(Wiki)和归档层(Archive),层次清晰,便于导航;
- 双向导航:支持从根节点下钻到具体的知识域(如API、数据模型、领域逻辑),也支持从具体知识反向关联到相关的规范和文档,实现知识的快速检索;
- 自动沉淀:在Archive阶段,系统会自动从OpenSpec契约、代码实现、测试用例中提取稳定知识,更新到对应的知识域索引中,无需人工手动维护;
- 防膨胀机制:设置知识索引的容量阈值(如500行),当索引超过阈值时,自动拆分为子目录,避免知识图谱过于庞大,确保检索效率;无法挂载到知识树的内容,优先归档,不污染活跃知识层。
LLM Wiki知识图谱的核心目录结构如下:
- KNOWLEDGE_GRAPH.md:知识图谱根节点,挂载所有顶级知识域入口,是Agent检索知识的强制起点;
- Schema/:规范层,包含OpenSpec契约模板、知识图谱结构规范等,确保知识的标准化;
- Wiki/:活跃知识层,按域隔离,包含API契约、数据模型、领域逻辑、架构决策、测试策略等,是研发过程中常用知识的集中存储区;
- Archive/:归档层,存储已完成研发任务的OpenSpec契约、临时文档等,保留可追溯性,但不参与日常检索。
通过LLM Wiki知识图谱,团队可以快速共享知识、复用经验,新人可以通过知识图谱快速熟悉项目规范和业务逻辑,老员工可以将经验沉淀为知识,实现知识的可持续传承。
4. 🛡️ 自我纠偏:让研发风险更可控
后端研发过程中,难免会出现代码规范不合规、SQL性能问题、跨域越权、测试失败等问题,传统研发中,这些问题往往需要人工发现和修正,效率低、风险高。Java Harness Agent 引入了完善的自我纠偏机制,通过钩子系统、失败恢复、人类介入检查点等方式,自动识别和修正研发过程中的问题,降低研发风险。
核心自我纠偏机制如下表所示:
机制 | 触发点 | 触发条件 | 产生效果 | 评判方式 |
guard_hook(守卫钩子) | 实现/改动过程中 | 代码风格不合规、数据权限越权、跨域污染、过度设计 | 立即阻断当前操作,提示问题所在,要求重写或获取显式授权 | 技能矩阵中的规范技能审查、项目规则核对 |
fail_hook(失败钩子) | 任意阶段失败 | 编译失败、测试失败、评审不通过、契约校验失败 | 状态降级回退到上一阶段,记录失败原因,触发重试计数 | 客观日志(编译输出、测试报告、评审结果) |
Max Retries(最大重试) | fail_hook 内 | 同一阶段连续失败达到阈值(默认3次) | 强制停止当前任务,请求人类介入排查问题 | 失败计数达到预设阈值 |
Approval (HITL) | Review 通过后 | 需要进入Implement阶段,冻结契约 | 由人类评审者授权是否进入实现阶段,契约冻结后不可随意修改 | 人类确认(YES/NO + 修改意见) |
Archive 写回 | 任务结束 | 新增/变更知识需要沉淀,契约需要归档 | 提取稳定知识更新到知识图谱,将契约归档,清理临时文件 | 规则校验、知识图谱连通性检查 |
Preferences 记忆 | Archive 前后 | 人类评分/反馈有代表性,可作为后续研发的参考 | 将经验沉淀为偏好/禁忌,下一轮研发的pre_hook生效 | 人类评分(1-10分)+ 文字反馈原因 |
这些自我纠偏机制,将“被动纠错”转变为“主动防错”,在研发过程中及时发现和解决问题,避免问题积累到后期,降低了研发成本和风险,同时也减少了人工干预的工作量。
5. 📊 契约先行:让研发协作更高效
Java Harness Agent 坚持“契约先行”的研发理念,将OpenSpec契约作为研发过程的核心依据,贯穿于整个生命周期。OpenSpec契约是一套标准化的文档模板,包含API签名、数据模型、SQL设计、业务流程、验收标准、JSON请求/响应示例等内容,明确了研发的边界和目标。
契约先行的优势主要体现在以下几个方面:
- 统一研发基准:所有研发人员都围绕同一套契约开展工作,避免了因理解偏差导致的代码不一致;
- 支持并行协作:在Approval阶段冻结契约后,前端可以基于契约构建UI,QA可以基于契约编写测试用例,后端可以同步实现代码,实现多角色并行协作,提升研发效率;
- 简化评审流程:评审阶段只需检查代码是否符合契约要求,无需重复确认需求,简化了评审流程;
- 便于维护和迭代:契约作为研发的“唯一事实来源”,后续需求迭代时,只需修改契约,再基于契约更新代码和文档,确保研发过程的可追溯性。
6. 🔌 技能矩阵:让专业能力更可复用
后端研发涉及多个专业领域,包括API设计、SQL优化、代码规范、测试策略、数据权限等,不同研发人员的专业能力存在差异,容易导致代码质量参差不齐。Java Harness Agent 构建了包含25+专业技能的技能矩阵,将每个专业领域的最佳实践、规范要求、工具用法封装为独立的技能,供研发过程中按需调用。
技能矩阵的核心设计特点:
- 模块化设计:每个技能独立封装,包含技能说明、使用场景、调用方式、校验标准等内容,便于维护和扩展;
- 阶段映射:每个生命周期阶段都有对应的推荐技能,确保研发过程中每个环节都能获得专业能力支撑;
- 标准化规范:技能中包含统一的规范要求,确保研发人员在调用技能时,能够遵循一致的标准;
- 可扩展性:支持新增自定义技能,满足团队的个性化需求,例如结合企业内部的代码规范、业务特点,新增专属技能。
技能矩阵的分类及核心技能说明将在后续章节详细介绍,通过技能矩阵,研发人员可以快速调用专业能力,降低专业门槛,确保代码质量和研发效率。
7. 📈 防膨胀机制:让知识体系更健康
随着研发任务的增加,知识图谱和文档会不断积累,若不加以控制,容易出现知识膨胀、检索效率降低、冗余信息过多等问题。Java Harness Agent 引入了严格的防膨胀机制,确保知识体系的健康和高效。
核心防膨胀规则如下:
- 索引拆分规则:任何知识域的索引文件(如API索引、数据模型索引)超过500行时,自动拆分为子目录,每个子目录对应一个细分领域,更新上级索引的挂载点,确保索引的简洁性;
- 知识筛选规则:只有稳定、可复用的知识才能写入活跃知识层(Wiki),临时文档、一次性需求的契约等,在Archive阶段归档,不进入活跃知识层;
- 挂载点规则:所有新增知识必须在LLM Wiki的Sitemap树中找到对应的挂载点,无法挂载的知识视为无效知识,优先归档;
- 定期清理规则:在Archive阶段,自动清理研发过程中的临时文件、冗余文档,确保项目结构清晰。
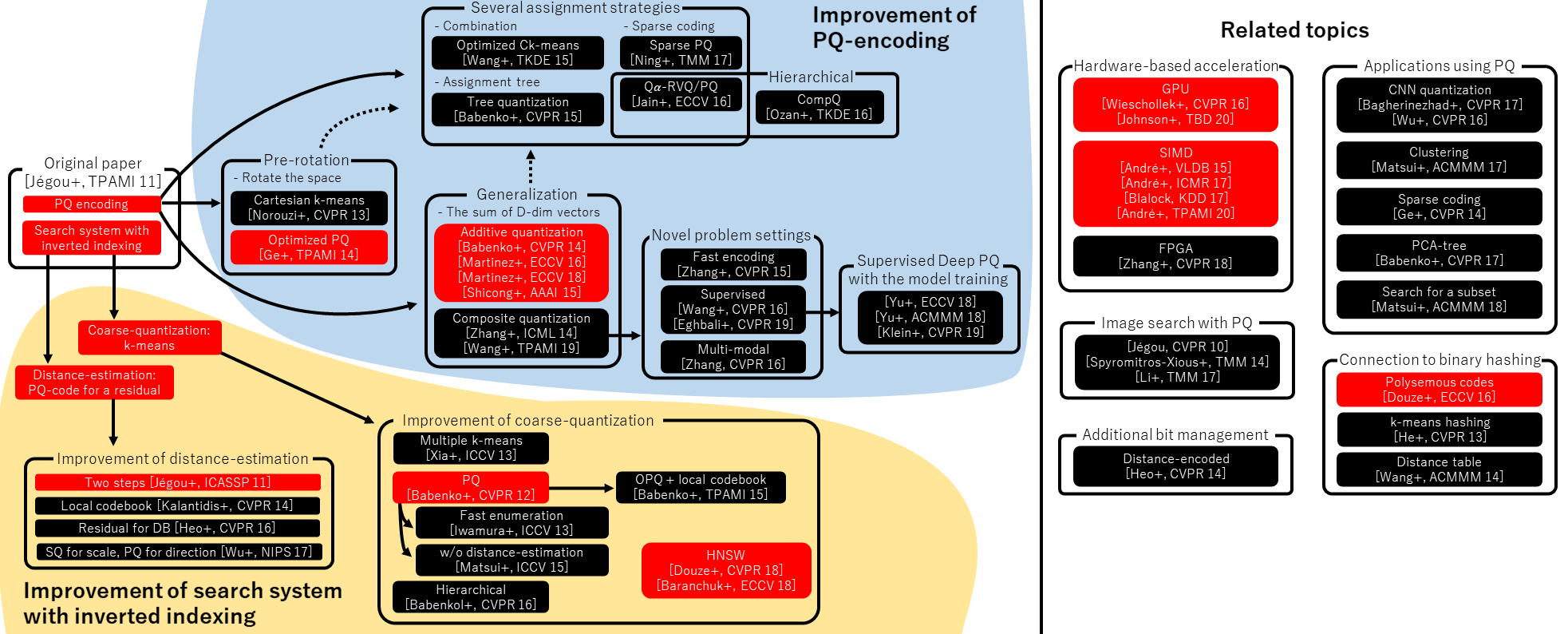
🏗️ 架构总览
核心组件
组件 | 职责 | 位置 |
意图网关 | 将自然语言转换为可执行意图队列 | |
上下文漏斗 | 双向知识检索与写回系统 | |
生命周期引擎 | 6 阶段状态机,自动流转 | |
钩子系统 | 前置/后置守卫、失败恢复、循环控制 | |
LLM Wiki | 以 sitemap 为根的分层知识图谱 | |
技能矩阵 | 25+ 领域专业专家能力 | |
脚本工具 | 确定性质量检查与辅助工具 |
Java Harness Agent 的架构设计遵循“高内聚、低耦合”的原则,将核心能力拆分为多个独立组件,组件之间通过标准化的接口交互,形成了一套完整的Agent驱动研发体系。
从架构图可以看出,Java Harness Agent 主要包含6个核心组件:意图网关、上下文漏斗、生命周期引擎、钩子系统、LLM Wiki知识图谱、技能矩阵,以及辅助组件脚本工具。每个组件的职责、位置和核心功能如下表所示:
组件 | 核心职责 | 位置 | 核心功能 |
意图网关(Intent Gateway) | 将自然语言需求转换为可执行意图队列 | 需求解析、意图提取、队列组装、断点续传 | |
上下文漏斗(Context Funnel) | 双向知识检索与写回系统 | 正向检索(从Sitemap下钻)、反向写回(归档提取)、知识挂载 | |
生命周期引擎(Lifecycle Engine) | 7阶段状态机,引导研发流程自动流转 | 阶段管理、任务调度、产出物校验、状态回退 | |
钩子系统(Hooks) | 前置/后置守卫、失败恢复、循环控制 | 规范校验、风险拦截、失败处理、队列消费 | |
LLM Wiki 知识图谱 | 以sitemap为根的分层知识存储与检索系统 | 知识存储、快速检索、自动沉淀、防膨胀管理 | |
技能矩阵(Skills) | 提供25+专业领域的专家能力支撑 | 规范引导、专业校验、能力复用、自定义扩展 | |
脚本工具(Scripts) | 确定性质量检查与辅助工具 | 图谱健康检查、契约结构验证、偏好标签检查 |
核心组件详细解析
1. 意图网关(Intent Gateway)
意图网关是Java Harness Agent 的入口组件,负责接收用户的自然语言需求,将其转化为结构化的意图队列,为后续的研发流程提供明确的目标。其核心设计思路是“先理解需求,再拆解任务”,避免研发过程中的盲目性。
意图网关的核心文件是
.agents/router/ROUTER.md,包含意图映射规则、队列组装逻辑、断点续传机制等内容。具体工作流程如下:- 需求输入:用户输入自然语言需求(可以是PRD文档、口头需求、需求工单等);
- 上下文检索:通过上下文漏斗,从LLM Wiki知识图谱中检索相关的知识(如相关API规范、数据模型、业务逻辑),辅助需求理解;
- 意图提取:对需求进行解析,提取核心意图,例如“新增接口”“修改表结构”“修复Bug”“性能优化”等;
- 队列组装:将核心意图按优先级、依赖关系,组装为结构化的意图队列(Launch Spec),每个意图都包含执行目标、依赖条件、产出物要求等;
- 持久化存储:将意图队列写入
.agents/router/runs/目录,实现断点续传——若研发过程中断,重新启动后可从上次中断的意图继续推进;
- 队列提交:将意图队列提交给生命周期引擎,启动研发流程。
意图网关的核心优势是“意图结构化”和“断点续传”,确保需求能够被准确理解和拆分,同时支持研发过程的中断恢复,提升研发的灵活性。
2. 上下文漏斗(Context Funnel)
上下文漏斗是连接意图网关、LLM Wiki知识图谱和生命周期引擎的核心组件,负责实现“正向检索”和“反向写回”的双向知识流转,确保研发过程中的上下文信息准确、完整。
上下文漏斗的核心文件是
.agents/router/CONTEXT_FUNNEL.md,定义了知识检索和写回的规则,具体功能如下:- 正向检索:当意图网关解析需求、生命周期引擎执行阶段任务时,上下文漏斗会从LLM Wiki的Sitemap根节点开始,按域索引下钻,检索相关的知识(如API规范、数据模型、架构决策),为研发提供上下文支撑;若索引中未找到相关知识,才允许使用兜底关键词搜索,避免“盲搜”导致的效率低下;
- 反向写回:当研发任务进入Archive阶段时,上下文漏斗会将研发过程中产生的稳定知识(如新增的API、修改的数据模型、优化的SQL),按照Sitemap的挂载规则,写回对应的知识域索引中,实现知识的自动沉淀;
- 知识校验:在知识写回前,对知识的规范性、完整性进行校验,确保写入知识图谱的知识符合项目规则和规范;
- 防膨胀控制:在知识写回时,检查目标索引的容量,若超过阈值,触发索引拆分机制,确保知识图谱的健康。
上下文漏斗的核心作用是“打通知识流转通道”,让研发过程中的知识能够快速检索和自动沉淀,避免知识碎片化,提升知识的复用率。
3. 生命周期引擎(Lifecycle Engine)
生命周期引擎是Java Harness Agent 的核心调度组件,负责管理研发流程的7个阶段,引导任务按步骤推进,确保每个阶段的产出物符合要求,实现研发流程的标准化和自动化。
生命周期引擎的核心文件是
.agents/workflow/LIFECYCLE.md,定义了每个阶段的目标、产出物、校验标准和流转规则。其核心功能如下:- 阶段管理:明确7个阶段的边界和目标,确保研发过程按“Explorer→Propose→Review→Approval→Implement→QA→Archive”的顺序流转,不允许跳过关键阶段;
- 任务调度:根据意图队列,为每个阶段分配对应的任务,调用相关的技能和工具,确保任务的高效执行;
- 产出物校验:对每个阶段的产出物进行校验(如探索报告的完整性、OpenSpec契约的规范性、测试用例的覆盖率),若校验不通过,触发fail_hook,回退到上一阶段;
- 状态回退:当某个阶段失败时,支持状态降级回退,记录失败原因,允许研发人员修正后重新推进;
- 队列消费:在Archive阶段完成后,通过loop_hook检查意图队列是否全部完成,若未完成,自动启动下一个意图的研发流程,实现多意图的批量处理。
生命周期引擎的核心优势是“流程标准化”和“自动化调度”,减少了人工干预,确保研发流程的一致性和可控性,提升了研发效率。
4. 钩子系统(Hooks)
钩子系统是Java Harness Agent 自我纠偏能力的核心载体,通过在生命周期的关键节点设置钩子函数,实现对研发过程的拦截、校验和修正,确保研发过程符合规范,降低风险。
钩子系统的核心文件是
.agents/workflow/HOOKS.md,定义了5种核心钩子类型,每种钩子的触发时机和功能如下:- pre_hook(前置钩子):在每个阶段开始前触发,用于装载该阶段所需的规范、技能和偏好设置,为阶段任务的执行提供基准;例如,在Implement阶段开始前,pre_hook会装载Java代码规范、API设计标准等;
- guard_hook(守卫钩子):在阶段任务执行过程中触发,用于校验任务执行的规范性,拦截违规操作;例如,在Implement阶段,guard_hook会检查代码是否符合Checkstyle规范、是否存在跨域越权等;
- post_hook(后置钩子):在每个阶段完成后触发,用于同步文档、记录日志、更新状态;例如,在QA阶段完成后,post_hook会记录测试结果,同步更新测试用例文档;
- fail_hook(失败钩子):在某个阶段失败时触发,用于处理失败场景,包括状态回退、记录失败原因、触发重试计数;例如,测试失败时,fail_hook会将状态回退到Implement阶段,记录测试失败的具体用例和原因;
- loop_hook(循环钩子):在Archive阶段完成后触发,用于检查意图队列是否全部完成,若未完成,自动启动下一个意图的研发流程,实现多意图的循环处理。
钩子系统的核心作用是“主动防错、自动纠偏”,将项目规则和规范嵌入到研发流程的每个节点,确保研发过程不偏离正轨,降低研发风险。
5. LLM Wiki 知识图谱
LLM Wiki 知识图谱是Java Harness Agent 的知识存储和检索核心,负责集中管理研发过程中的所有知识,实现知识的快速检索、自动沉淀和防膨胀管理。其核心目录结构如下:
各目录的核心功能详细说明:
- .agents/llm_wiki/KNOWLEDGE_GRAPH.md:知识图谱的根节点,仅挂载顶级知识域(如schema、wiki、archive)的入口,是Agent检索知识的强制起点,确保知识检索的规范性和高效性;
- purpose.md:定义了Java Harness Agent 的系统哲学、设计原则和核心目标,为研发人员提供统一的理念指引;
- schema/:规范层,包含OpenSpec契约模板(openspec_schema.md)和规范索引(index.md),确保研发过程中的契约和文档符合标准化要求;
- wiki/
- api/:存储所有API契约、接口规范、请求/响应示例等;
- data/:存储数据模型、表结构、SQL规范、索引设计等;
- domain/:存储领域模型、业务字典、业务逻辑等;
- architecture/:存储架构决策记录(ADR)、系统架构图、技术选型等;
- specs/:存储当前活跃的需求契约(未归档的OpenSpec);
- testing/:存储测试策略、测试用例、测试工具用法等;
- preferences/:存储研发偏好、禁忌规则、最佳实践等,用于指导后续研发。
:活跃知识层,按域隔离,存储研发过程中常用的、可复用的知识:
- archive/:冷存储层,存储已完成研发任务的OpenSpec契约、临时文档、废弃规范等,保留可追溯性,但不参与日常检索,避免污染活跃知识层。
LLM Wiki 知识图谱的核心优势是“分层管理、双向导航、自动沉淀、防膨胀”,确保知识的可复用性和检索效率,实现知识的可持续传承。
6. 技能矩阵(Skills)
技能矩阵是Java Harness Agent 的专业能力支撑核心,包含25+专业技能,覆盖意图解析、需求分析、系统设计、代码实现、测试验证、文档归档等后端研发的全流程,为研发过程中的每个环节提供专业的规范和能力支撑。
技能矩阵的核心设计原则是“模块化、标准化、可扩展”,每个技能独立封装在
.agents/skills/目录下,入口文件为SKILL.md,包含技能说明、使用场景、调用方式、校验标准等内容。技能矩阵的分类及核心技能说明如下:
(1)意图与生命周期类技能
这类技能主要用于意图解析和生命周期管理,确保研发流程的顺畅推进:
- intent-gateway:意图入口能力,协助理解需求并启动“先读图谱再下钻”的工作流,支持意图提取和队列组装;
- devops-lifecycle-master:生命周期主控编排,强制执行阶段边界,确保研发流程按标准化顺序流转;
- skill-graph-manager:维护技能知识图谱的双向链接,确保技能之间的关联性和一致性;
- trae-skill-index:技能总索引,帮助Agent快速发现和调用所需的专业技能。
(2)需求与设计类技能
这类技能主要用于需求分析和系统设计,确保需求理解准确、设计方案合理:
- product-manager-expert:需求澄清、范围界定、验收标准提炼,帮助研发人员准确理解产品需求;
- prd-task-splitter:将PRD拆分为结构化开发任务,明确任务依赖关系和执行顺序;
- devops-requirements-analysis:梳理PDD/SDD边界,输出可执行的需求规格和影响面分析;
- devops-system-design:系统设计与数据建模,包括表结构、索引、扩展性方案的设计;
- devops-task-planning:将设计方案拆分为实现任务清单,明确实现顺序和验证点。
(3)实现类技能
这类技能主要用于代码实现,确保代码质量和规范:
- devops-feature-implementation:按规格实现功能代码,强调TDD原则,确保代码符合规范;
- devops-bug-fix:缺陷定位、复现、修复与回归,确保Bug修复彻底,不引入新问题;
- utils-usage-standard:统一工具类/框架用法模式,避免风格碎片化;
- aliyun-oss:对象存储相关能力规范,包括多桶管理、环境隔离、预签名URL等。
(4)代码标准类技能
这类技能主要用于代码规范校验,确保代码风格、API设计、SQL编写等符合统一标准:
- global-backend-standards:全局后端标准索引入口,统一工程规范、分层规则和依赖管理;
- java-engineering-standards:Java工程分层与包结构规范,保证职责边界和可维护性;
- java-backend-guidelines:Java防御性编程、完整装配、分页等通用编码准则;
- java-backend-api-standard:API设计模式(动词/路径/响应结构等),避免API演进失控;
- java-javadoc-standard:统一Javadoc风格与注释规范,保证代码可读性;
- java-data-permissions:数据权限约束(查询过滤/动作校验),避免越权;
- mybatis-sql-standard:MyBatis SQL性能与安全守卫,避免隐式转换、JOIN风险等;
- error-code-standard:统一错误码与异常表达方式,避免前后端割裂;
- checkstyle:Java代码风格强制(Google/Sun混合规则),确保代码风格一致。
(5)测试与评审类技能
这类技能主要用于代码评审和测试验证,确保代码质量和功能正确性:
- devops-testing-standard:测试规范与TDD阶段指导,确保测试用例覆盖全面;
- code-review-checklist:强制评审清单,覆盖安全、性能、规范、可维护性等维度。
(6)文档类技能
这类技能主要用于文档生成和同步,确保文档与代码保持一致:
- api-documentation-rules:强制API文档生成与归档规则,避免“代码更新但文档缺失”;
- database-documentation-sync:数据库结构变更时,同步表文档、清单与ER图。
每个生命周期阶段与推荐技能的映射关系如下表所示,确保每个阶段都能获得对应的专业能力支撑:
🚀 快速上手
前置要求
- Java 17+
- Python 3.8+(可选脚本)
- Git
3 分钟入门
第一步:阅读项目规则 ⚡
从 项目规则 开始 - 这是定义执行纪律的主入口。
第二步:导航知识图谱 🗺️
从 Sitemap 根节点 开始,下钻到目标域:
- API 设计 →
wiki/api/index.md
- 数据模型 →
wiki/data/index.md
- 领域逻辑 →
wiki/domain/index.md
- 架构决策 →
wiki/architecture/index.md
第三步:运行第一个完整周期 🔄
按照 生命周期 完成一次任务:
💡 使用场景
场景 A:新增查询接口(不改表)
目标:创建只读端点(DTO/Controller/Service),不涉及表结构变更
关键产出:
- ✅
explore_report.md- 范围与影响面分析
- ✅
openspec.md- API 契约含 JSON 示例
- ✅ 按契约实现的代码(不过度设计)
- ✅ 单元测试与覆盖率证据
- ✅ 更新
wiki/api/中的 API 索引
场景 B:API + 数据库模式变更
目标:新接口同时新增/调整表结构与索引
关键路径:
- Propose:同时冻结 API 与 Data 契约
- Review:SQL 风险评估、索引利用、隐式转换检查
- QA:回归测试覆盖核心查询与边界条件
- Archive:同时更新
wiki/api/和wiki/data/索引
激活技能:
devops-system-design- 模式建模
mybatis-sql-standard- SQL 性能守卫
database-documentation-sync- ER 图更新
场景 C:Bug 修复(先复现后测试)
目标:修复缺陷,确保可复现、可回归、可追溯
工作流:
- Explorer:最小复现路径 + 根因假设
- QA:修复前先写失败测试(TDD 方法)
- Implement:修复实现使测试通过
- Archive:在
wiki/testing/或reviews/中记录模式
场景 D:性能优化
目标:优化 SQL/性能而不改变外部行为
关注点:
- Propose:文档化"行为不变"约束 + 回退策略
- Review:SQL 标准与索引利用作为最高优先级
- QA:对比证据(性能基准 + 正确性)
- Archive:将可复用性能规则提取到
preferences/
场景 E:重构(含边界守卫)
目标:提升可维护性而不引入需求漂移
守卫措施:
- 明确的"做什么/不做什么"范围定义
- 跨域修改需要显式授权
- 架构决策写回到
wiki/architecture/
场景 F:并行协作
目标:后端主导交付,前端/QA 可选并行工作
关键交接点:
- Approval 阶段:冻结的 OpenSpec 成为唯一事实来源
- 最小交接物:API 契约(JSON 示例)、验收标准(Given/When/Then)、错误码
- 后端内聚:其他细节保持后端内部(不强制外扩)
📚 生命周期阶段
Phase 1: Explorer 🔍
目的:澄清需求、定义范围、识别风险
技能:
product-manager-expert, devops-requirements-analysis, prd-task-splitter产出:
explore_report.md 包含:- 需求边界与非目标
- 跨域影响面分析
- 异常分支与边界情况
Phase 2: Propose 📝
目的:设计解决方案并冻结契约
技能:
devops-system-design, devops-task-planning产出:
openspec.md 包含:- API 签名与数据模型
- 数据库模式与索引
- 业务流程
- 验收标准
- JSON 请求/响应示例
Phase 3: Review 🔬
目的:针对标准的自动化技术评审
技能:
devops-review-and-refactor, global-backend-standards, java-*, mybatis-sql-standard评审矩阵:
- ✅ 架构与工程标准
- ✅ API 设计模式
- ✅ SQL 性能与安全
- ✅ 安全与数据权限
- ✅ 错误处理一致性
失败:触发
fail_hook → 返回 ProposePhase 3.5: Approval (HITL) 👥
目的:实现前的人类检查点
动作:向人类评审者展示 OpenSpec 摘要
问题:"设计已通过自动审查。是否进入实现阶段?"
结果:
- ✅ 是 → 进入 Implement 阶段(契约冻结)
- ❌ 否 + 反馈 → 返回 Propose 进行修订
并行触发:冻结契约使前端/QA agent 可以开始工作
Phase 4: Implement 💻
目的:在契约边界内实现代码
技能:
devops-feature-implementation, utils-usage-standard, aliyun-oss纪律:
- 不超过规范的过度设计
- 必须通过 Checkstyle 验证
- 应用防御性编程指南
- 尊重领域边界(
guard_hook)
Phase 5: QA Test 🧪
目的:遵循 TDD 原则的质量保证
技能:
devops-testing-standard, code-review-checklist要求:
- 关键路径测试覆盖率 ≥ 100%
- 所有检查清单项必须为绿色
- Bug 修复的回归测试
- 优化的性能基准
失败:触发
fail_hook → 返回 ImplementPhase 6: Archive 📦
目的:知识提取与清理
动作:
- 文档同步:自动触发 API 与 DB 文档更新
- 知识提取:将稳定规范合并到域索引
- 冷存储:将原始
openspec.md移至archive/
- 进化:请求人类评分(1-10)用于偏好学习
- 循环检查:读取
launch_spec.md→ 下一个意图或完成
防膨胀规则:
- 索引文件 > 500 行 → 拆分为子目录
- 无法挂载的内容 → 归档而非活跃区
- 所有知识必须在 sitemap 树中有挂载点
🛡️ 自我纠偏机制
机制 | 触发点 | 触发条件 | 产生效果 | 评判方式 |
guard_hook | 实现/改动过程中 | 风格不合规、权限/越权、跨域污染 | 立即阻断、要求重写或授权 | 规范技能审查、规则核对 |
fail_hook | 任意阶段失败 | 编译/测试/审查失败 | 状态降级回退;记录失败原因;触发重试计数 | 客观日志(编译/测试输出) |
Max Retries | fail_hook 内 | 同一阶段连续失败达到阈值(3次) | 强制停止并请求人类介入 | 失败计数达到阈值 |
Approval (HITL) | Review 通过后 | 需要进入 Implement | "冻结契约",由人类授权是否进入实现 | 人类确认(YES/NO + 修改意见) |
Archive 写回 | 任务结束 | 新增/变更知识需要沉淀 | 从 Spec 提取稳定知识、归档热文档、更新索引 | 规则校验、连通性检查 |
Preferences 记忆 | Archive 前后 | 人类评分/反馈有代表性 | 将经验沉淀为偏好/禁忌,下一轮 pre_hook 生效 | 人类评分 + 文字原因 |
🔧 技能矩阵
可用技能(25+)
意图与生命周期
- intent-gateway - 意图入口能力,启动"先读图谱再下钻"工作流
- devops-lifecycle-master - 生命周期主控编排,强制执行阶段边界
- skill-graph-manager - 维护技能知识图谱双向链接
- trae-skill-index - 技能总索引,快速发现能力
需求与设计
- product-manager-expert - 需求澄清、范围界定、验收标准提炼
- prd-task-splitter - PRD 分解为结构化开发任务
- devops-requirements-analysis - PDD/SDD 边界梳理,可执行需求规格
- devops-system-design - 系统设计与数据建模(FDD/SDD)
- devops-task-planning - 设计分解为实现任务清单
实现
- devops-feature-implementation - 功能编码,强调 TDD
- devops-bug-fix - 缺陷定位、复现、修复与回归
- utils-usage-standard - 统一工具类/框架用法模式
- aliyun-oss - 对象存储(多桶/环境隔离/预签名 URL)
代码标准
- global-backend-standards - 全局后端标准索引入口
- java-engineering-standards - Java 分层与包结构规范
- java-backend-guidelines - 防御性编程、完整装配、分页
- java-backend-api-standard - API 设计模式(动词/路径/响应结构)
- java-javadoc-standard - 统一 Javadoc 风格与注释规范
- java-data-permissions - 数据权限约束(查询过滤/动作校验)
- mybatis-sql-standard - MyBatis SQL 性能与安全守卫
- error-code-standard - 统一错误码与异常表达
- checkstyle - Java 代码风格强制(Google/Sun 混合)
测试与评审
- devops-testing-standard - 测试规范与 TDD 阶段指导
- code-review-checklist - 强制评审清单(安全/性能/规范/可维护性)
文档
- api-documentation-rules - 强制 API 文档生成与归档
- database-documentation-sync - DB 结构变更同步(表/清单/ER 图)
阶段 → 技能映射
阶段 | 推荐技能 |
Explorer | product-manager-expert, devops-requirements-analysis, prd-task-splitter |
Propose | devops-system-design, devops-task-planning |
Review | devops-review-and-refactor, global-backend-standards, java-\*/mybatis-sql-standard/error-code-standard |
Implement | devops-feature-implementation, devops-bug-fix, utils-usage-standard, aliyun-oss |
QA | devops-testing-standard, code-review-checklist |
Archive | api-documentation-rules, database-documentation-sync |
📂 项目结构
🔍 可选诊断工具
这些脚本提供确定性质量检查(仅报告,不修改文件):
图谱健康检查
检查项:死链、孤立文件、索引长度警告
契约结构验证
检查项:缺失关键段落、JSON 示例存在性
偏好标签检查
检查项:规则标签规范,便于精准检索
🎯 工程红线
🚫 不盲搜
始终从 Sitemap 开始 → 通过索引下钻。仅在索引失败时使用兜底搜索。
🚫 不越权
跨域修改需要在
openspec.md 中明确授权,并在 Review/HITL 阶段确认。🚫 不暴走
失败回退 + 最大重试阈值(3 次)。达到阈值时停止并请求人类介入。
🚫 不膨胀
- 规范必须在提取后归档
- 稳定知识必须提取到索引
- 超过 500 行的索引必须拆分为子目录
📖 相关文档
- 📘 工程手册(英文版):ENGINEERING_MANUAL.md - 详细的英文工程指南与工作流
- 🇺🇸 English README: README.md - Complete English version of this README
- 📌 项目规则:AGENTS.md - 主规则入口
- 🗺️ 知识图谱:.agents/llm_wiki/KNOWLEDGE_GRAPH.md - 根导航
- 🎯 意图网关:.agents/router/ROUTER.md
- 🔍 上下文漏斗:.agents/router/CONTEXT_FUNNEL.md
- ⚙️ 生命周期:.agents/workflow/LIFECYCLE.md
🙏 致谢
本框架灵感来源于:
- OpenSpec:契约优先开发方法论
- Harness:生命周期状态机与钩子系统
- LLM Wiki:具有防膨胀机制的可演进知识图谱
- Agentic Patterns:带人类介入检查点的自主 Agent 工作流
为可持续的智能后端开发而构建 ❤️