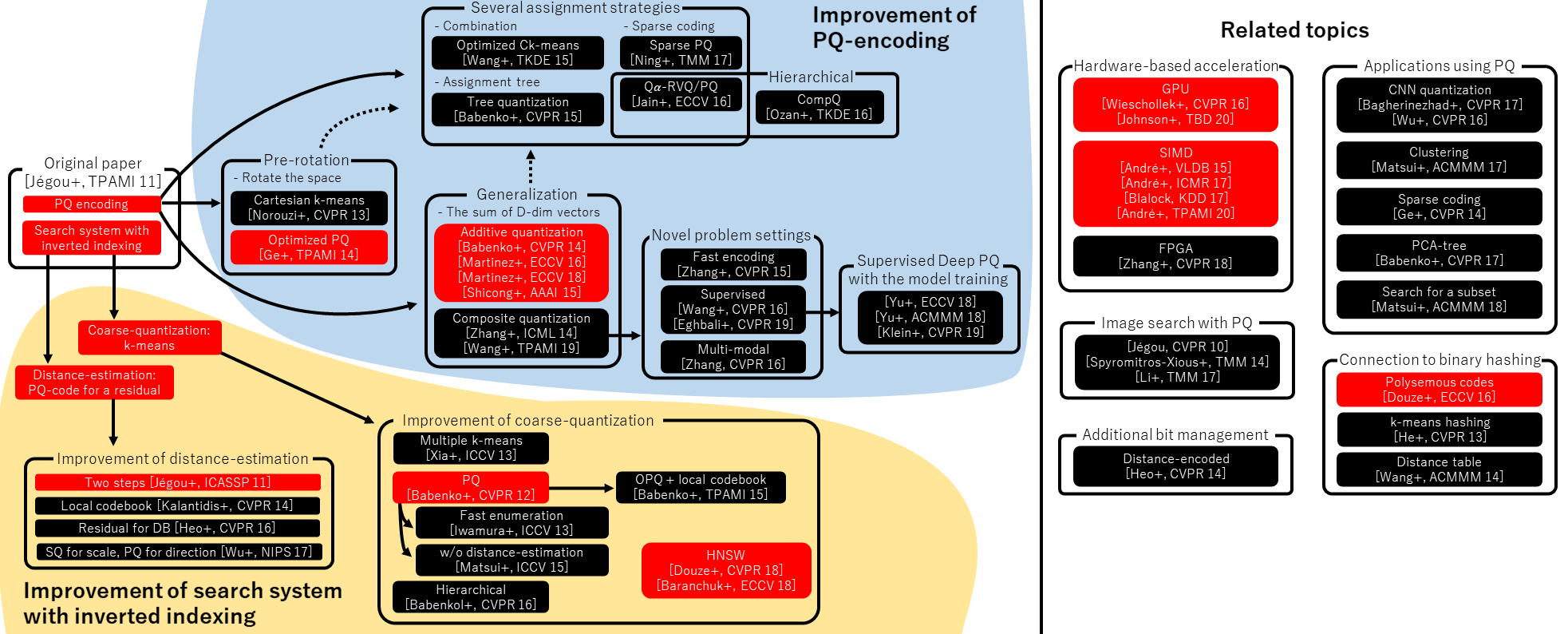
序言:幻觉的破灭与工程的觉醒
2026 年,我们依然在和 AI 的“幻觉”作斗争。
当你对着各种号称“全自动”的 AI 编程助手输入一句:“帮我加个租户资产管理的接口”,你期待它像一个高级架构师一样,考虑分层、事务、多租户隔离、深分页 OOM 防御。但现实往往是:它一顿操作猛如虎,直接在
Controller 里写了 500 行连环数据库插入代码,不仅没有 @Transactional 事务回滚,还把底层的实体类改得面目全非。等你指出编译错误,它又陷入了无限重试的死循环,直到烧光你的 API 预算,留下一个烂摊子。这不是大模型不够聪明,而是我们用错了大模型。
如果说 OpenAI、Google 和 Anthropic 是在制造动力澎湃的“V8 引擎”,那么业界流行的 AutoGPT 就像是造了一辆没有方向盘和刹车的汽车,直接把引擎绑在轮子上裸奔。
本文将跳出“提示词工程(Prompt Engineering)”的范畴,从第一性原理出发,深度剖析大语言模型(LLM)的物理缺陷。并结合近期开源的 Java Harness Agent 项目,全景拆解这套机器对机器(M2M)的操作系统——看看它是如何通过“认知刹车”、“生命周期门控”和“多角色矩阵”,给大模型穿上工业级的“拘束衣”,将一个“失控的概率引擎”驯化为高度可控的超级工程师的。
第一部分:剥开大模型的画皮——大模型的物理现实与六大工程原罪
在设计 Agent 架构之前,我们必须先回答一个核心问题:大模型真的会思考吗?
答案是残酷的:大模型绝对没有人类意义上的“内隐思考(Internal Thinking)”。
现阶段的 Transformer 模型是纯粹的前馈网络(Feed-forward Network),本质上是一个 Next-Token Predictor(下一个词预测器)。它在输出第一个字的时候,根本不知道自己最后一个字要写什么。它没有人类大脑中的“工作记忆区(Working Memory)”来在后台打草稿、推演、推翻、再推演。它输出的每一个字,就是它“思考”的全部过程。
基于这个物理现实,大模型在复杂的软件工程中,天然带有 六大不可逾越的原罪:
原罪一:缺乏全局规划的“快思考”机器(想到哪写哪)
因为没有后台打草稿的能力,大模型极易顺着上一句话往下写。
- 开发痛点:在“租户资产管理”案例中,大模型为了完成“插入资产”的任务,直接在 Controller 里调用了三次 Repository。它完全忽略了跨表操作的事务一致性问题,因为它在生成第一行代码时,根本没有往后推演到“如果第三步失败了怎么办”。
原罪二:长上下文的注意力稀释(Lost in the Middle)
Transformer 的自注意力机制(Self-Attention)是全局计算的。
- 开发痛点:当你为了让它了解项目,把 10 个 Java 文件(几万 Token)塞进上下文时,每一个 Token 都在争夺注意力权重。结果就是,你写在提示词最前面的《项目编码规范》(如:必须使用
CustomerException),其权重被海量代码稀释殆尽。模型写代码时瞬间“走神”,直接抛出了原生的RuntimeException。
原罪三:预训练本能的“引力坍缩”(指令漂移)
大模型的基座是被海量的 GitHub 开源代码和 StackOverflow 问答训练出来的。
- 开发痛点:在它的神经网络中,“用户提问 -> 直接甩出普通代码”的激活概率是 99%。哪怕你要求它“严格遵守 RESTful 规范,不要改动公共拦截器”,随着对话拉长,它会顺着“阻力最小的路径”滑下去,屈服于预训练的本能,越权修改不该动的文件。
原罪四:陷入“局部最优解”的赌徒(死循环)
大模型在排错时是极其固执的。
- 开发痛点:面对一个复杂的
mvn compile报错,模型在贪婪解码(Greedy Decoding)时,极容易困在“局部最优解”的数学陷阱里。它会连续 10 次给出极其相似但依然报错的修复方案,直到触发平台的强行熔断(Max Tool Call Loop Reached)。
原罪五:无状态的失忆症患者(缺乏全局状态)
- 开发痛点:哪怕它在这个会话里表现得像个战神,一旦对话窗口关闭,它就彻底清空了对这个项目所有的认知。下次你让它改同一个模块,它又要从头开始摸索。它无法像人类一样积累“领域经验”。
原罪六:多路由的分类坍塌(薛定谔的意图)
- 开发痛点:如果你给它 10 条复杂的路由规则(“如果是查文档走 A,修 Bug 走 B...”),它经常会发生条件坍塌。抓取了用户句子里的“代码”两个字,就自动挂载了“重构系统”的沉重工作流,导致大炮打蚊子。
原罪七:多步推理的错误级联(Cascading Failures)与执行精度衰减
业界流行的 Agent 框架喜欢让模型“自主规划、自主执行”。但大模型是基于概率分布的预测器(Probabilistic Predictor)。
- 根本原因与痛点:假设模型每一步工具调用的准确率高达 95%,如果让它连续自主执行 10 步,整体成功率就会暴跌到 59%($0.95^{10}$);20 步更是低至 36%。在实际开发中,只要中间某一步工具调用返回了非预期结果(比如查错了一张表,或者 API 抛出了庞大的错误 JSON),模型极易产生“自信的幻觉(Hallucination with tools)”。它不会意识到自己错了,而是基于错误的上游结果继续往下编造代码,最终导致整个任务链条全线崩溃,前期消耗的 Token 全部打水漂。
原罪八:上下文爆炸与二次方成本增长(Quadratic Token Cost)
- 根本原因与痛点:Transformer 的自注意力机制计算复杂度是上下文长度的平方($O(N^2)$)。在多步 Agent 工作流中,第 N 步需要携带前 N-1 步所有的系统提示词、工具调用记录、大段的代码返回和内部思考过程。随着对话轮次增加,Token 消耗呈指数级爆炸。这不仅带来了极其高昂的 API 成本,还会严重加剧“注意力稀释”,让模型在庞杂的上下文中彻底迷失,变成一个反应迟钝的傻子。
第二部分:理想丰满,现实骨感——常规解决方案的局限
面对上述物理缺陷,业界目前流行的常规解法往往治标不治本,甚至引入了新的灾难:
- 解决上下文瓶颈:RAG 与向量数据库
- 做法:把代码切块存入 Vector DB,用余弦相似度搜索。
- 局限:向量搜索是模糊匹配(Semantic Search)。它经常把名字相似但逻辑毫无关系的代码塞给大模型。这导致了“精准的垃圾输入,产出精准的垃圾输出(Garbage In, Garbage Out)”。
- 解决自治能力:ReAct 循环与无约束 AutoGPT
- 做法:给模型一个目标,让它
Thought -> Action -> Observation无限循环。 - 局限:这是对模型能力的严重高估。一辆没有刹车的车,一旦遇到编译报错,直接陷入死循环,一晚上烧掉几百美金的 API 费用,最后代码库一片狼藉。
- 解决长程遗忘:依赖超长上下文窗口模型
- 做法:使用支持 200K 甚至 1M 上下文的模型,每次把整个项目塞进去。
- 局限:不仅极其昂贵(“思考税”极高),而且依旧无法解决注意力稀释(Lost in the Middle)的物理法则。
第三部分:Java Harness Agent 架构全景解剖
“不要把方向盘交给引擎。”
这是
Java Harness Agent 的核心哲学。它放弃了对“全知全能 AGI”的浪漫幻想,承认了大模型“会幻觉、会遗忘、会陷入死循环”的现实。它用软件工程中最经典的手段(状态机、契约设计、权限隔离、日志回写),为这台概率引擎打造了一套极其坚固的约束线束(Harness)。

下面,我们来看看这套系统是如何在各个节点,通过巧妙的机制,逐一击破大模型的原罪的。
节点 1:会话起点 —— 意图网关(Intent Gateway)
解决问题:多路由分类坍塌(原罪六)
在这个节点,系统不让大模型做复杂的长程推理分类。相反,它通过
ROUTER.md 定义了极简的“硬路由”和“快捷指令(Shortcut DSL)”。- 机制:强制协议头与快捷指令
模型在任何输出前,必须首先打印状态:
[Intent Check] intent=Change | profile=@standard。 同时,支持人类直接下达快捷指令: @patch:小型 Bug 修复。直接跳过前期繁琐的方案设计,进入代码修改。@standard:新功能开发。强制走完完整的需求、设计、评审、开发闭环。@learn:纯阅读问答。
- 疗效:把多维度的模糊判断降维成了单步枚举选择,彻底消除了指令漂移。
节点 2:每一次行动前 —— 动态认知刹车(Dynamic Cognitive Brake)
解决问题:缺乏思考能力(原罪一)与注意力稀释(原罪二)
既然大模型不会“后台打草稿”,那我们就强迫它在“前台”大声把思考过程念出来。在任何工具调用或写代码前,大模型必须输出一段
<Cognitive_Brake> XML 块。- 机制:强制结构化 CoT(思维链)
- 数学原理:大模型预测动作 $A$ 的概率从 $P(A|Context)$ 变成了 $P(A|Context, Brake)$。因为 $Brake$ 包含了极其丰富的架构约束信息,它作为极高权重的近距离上下文,瞬间收束了生成动作的概率空间。
- 疗效:大模型在写出“涉及跨表,必须使用 Facade 处理事务”这句话后,接下来的代码就绝对不会忘记加
@Transactional了。
节点 3:贯穿全流程 —— 多角色矩阵(Role Matrix)
解决问题:预训练本能的引力坍缩(原罪三)
为了防止模型“自由发挥”,系统在不同的生命周期阶段,强行给大模型挂载不同的虚拟角色(Personas)。
- 机制:角色代入与 Few-Shot 肌肉记忆
- 在 Explorer 阶段:挂载
@Ambiguity Gatekeeper(专挑需求毛病)。 - 在 Implement 阶段:挂载
@Focus Guard(物理级防爆墙)和@Security Sentinel。 在AGENTS.md中,系统注入了完美的Standard Workflow Saga范本(Few-Shot)。当模型看到范本中“As @Focus Guard, strict boundary is Controller. Zero drift.”时,会在其神经网络中高亮激活与“边界控制”相关的预训练权重。
- 疗效:模型不再是一个“全栈黑客”,而是一个恪尽职守的流水线工人。不该改的文件,一行都不会碰。
节点 4:执行与测试阶段 —— 双重门控与绝对止损(HITL & Strict Retries)
解决问题:陷入局部最优解的死循环(原罪四)与 多步推理的错误级联(原罪七)
这是对业界 AutoGPT 模式的最强力纠偏。系统将长链条切断,设立了物理断路器。
- 机制 1:Approval Gate (人类审批门控)
在
Propose阶段产出openspec.md(技术蓝图) 和focus_card.md(修改边界) 后,模型必须 STOP。只有人类点头同意方案,才能进入编码阶段。这彻底阻断了多步自主执行带来的错误级联,将 20 步的脆弱长链条切分为由人类确认的绝对安全检查点。
- 机制 2:Validation Gate & STRICT MAX RETRIES: 2
代码写完后,再次 STOP。人类允许后才开始执行
mvn compile。 如果编译失败,模型最多只能尝试自动修复 2次。超过 2 次,必须立即放弃并向人类求助(fail_hook触发 Escalation Protocol)。
- 疗效:彻底斩断了“方向错误导致重写上千行代码”和“编译报错无限循环烧光 Token”的灾难。用人类的介入引入“新的高权重变量”,打破数学死循环与概率衰减。
5. 节点 5:检索阶段 —— 知识漏斗与预算控制(Context Funnel)
解决问题:长上下文的注意力稀释(原罪二)与 上下文爆炸的二次方成本(原罪八)
- 机制:Budget Limits 与 Search Sub-Agent
系统给模型设定了严格的阅读预算:
Wiki ≤ 3, Code ≤ 8。 如果遇到庞大的代码库扫描,首选调用原生的 Search Sub-Agent(如 Trae, Claude Code 等平台的子代理)。让子代理去脏活累活(读 10 万行代码),然后只向主 Agent 返回 500 字的浓缩摘要。如果没有子代理,则严格执行贫民版预算兜底。
- 疗效:保持了主上下文窗口的绝对纯净,防止大模型“变瞎”,并从根本上遏制了 Token 消耗的二次方爆炸增长。
6. 节点 6:任务终点 —— 异步归档(Async Archive & WAL)
解决问题:无状态的失忆症患者(原罪五)与 上下文爆炸的二次方成本(原罪八)
- 机制:WAL (Write-Ahead Log) 碎片化沉淀
借用数据库底层的日志机制。在当前会话完成任务后(建议在新开的干净会话中),强制大模型把刚学到的领域知识、新增的 API 提取成 Markdown 碎片,写入知识库域的
wal/目录(例如.agents/llm_wiki/wiki/**/wal/YYYYMMDD_xxx.md)。后续由脚本将碎片“压缩/合并”进索引(index),避免单文件无限膨胀。
- 疗效:用极低的成本实现了项目知识的永久、无损沉淀。大模型真正拥有了可跨越会话的“长期记忆”,且新任务无需携带上一个任务庞大冗长的聊天记录,实现了成本与性能的双赢。
第四部分:把规则从“提示词”落地成“确定性门禁”——脚本工具的作用与使用时机
很多人以为 Agent 工程只是在“写 Prompt”。但只要你让模型碰过一次真实工程,就会发现:提示词是软约束,脚本与门禁才是硬约束。
当 Agent 具备“会写代码、会改文件、会调用工具”的能力时,它也同时具备了“会越权、会误删、会被注入诱导”的风险。工业化的做法不是寄希望于模型“自觉”,而是把关键约束变成可执行的脚本,让它在关键节点自动触发,并用退出码(PASS/WARN/FAIL)把结果交还给人类决策。
下面以本仓库
.agents/scripts/ 目录为例,梳理这套“脚本工具链”的设计思想:它不是为了替代人类,而是为了让人类能用更低的成本做更强的治理。4.1 统一入口:把“该跑哪些检查”从人脑迁移到 CLI
- 代表入口:
.agents/scripts/gates/run.py
- 核心思想: 将“门禁检查集合”做成一个确定性运行器,根据 intent/profile/phase 选择要跑的检查,并生成结构化报告(而不是把所有规则塞进 prompt 里让模型临场发挥)。
- 你应该在什么时候用:
- 进入 Implement 前:确认
focus_card.md已冻结、范围不漂移。 - 提交代码前 / PR 前:跑一遍 strict gate,避免把“缺 WAL、缺证据、越界改动、潜在密钥泄露”等问题带到评审阶段。
- 多人协作时:把“对 Agent 的信任”转移为“对门禁脚本的信任”,让团队协作变成可复现的工程流程。
4.2 门禁脚本(gates):把高风险点变成“可被机器阻断”的规则
门禁脚本的共同特征是:只读检查、快速执行、输出清晰、失败可解释。
- 范围与漂移治理:
focus_card_gate.py、scope_guard.py - 何时用: 任何 Change 类任务开始前与编码后都应跑一次。
- 为什么要这么做: 这是对“预训练本能引力坍缩(指令漂移)”最有效的解法之一——你让模型写十遍“不要越界”,都不如一次
scope_guard的 FAIL 来得硬。
- 知识写回治理:
writeback_gate.py、wal_template_gate.py - 何时用: 进入 Archive 之前;或在交付胶囊(delivery capsule)生成后。
- 为什么要这么做: 大模型的“记忆”不是可靠资产,文件系统里的 WAL 才是。强制写回把一次性的思考转化为可复用的组织知识。
- 安全与合规治理:
secrets_linter.py、migration_gate.py - 何时用: 任何涉及外部凭证、配置文件、SQL 迁移的任务,都应该默认跑。
- 为什么要这么做: 业界已将“间接提示词注入(Indirect Prompt Injection)”视为 Agent 的核心安全问题:当模型阅读网页、邮件、文档等外部内容时,恶意指令可能混入上下文并诱导其执行危险动作。OWASP LLM Prompt Injection Prevention Cheat Sheet 与 OpenAI 的安全说明都强调“将工具权限收窄、对关键动作做用户确认/隔离”是重要防线。Understanding prompt injections
- 交付物结构治理:
delivery_capsule_gate.py、api_breaking_gate.py、dependency_gate.py - 何时用: 当你要交付一个可审计的结果(API 变更、依赖变更、对外接口变更)时。
- 为什么要这么做: 让“证据链”先于“信任链”。Agent 的结果必须可被复核,而不是只能被相信。
4.3 知识库脚本(wiki):把“可导航、可检索、可压缩”做成自动化维护
- Wiki 体检:
wiki_linter.py - 何时用: 当知识库增长到一定规模、出现死链/孤岛/超长文档倾向时。
- 为什么要这么做: 对 Agent 而言,知识库不是“越大越好”,而是“越可导航越好”。否则就会发生注意力稀释与上下文爆炸。
- 契约结构检查:
schema_checker.py - 何时用: openspec.md 写完后、进入实现前。
- 为什么要这么做: 让“设计质量”先于“编码速度”,减少后期返工。
- WAL 压缩合并:
compactor.py - 何时用: 当 wal/ 碎片积累到一定规模,需要把增量变成稳定索引时。
- 为什么要这么做: WAL 是追加写,索引是可读可查;压缩器负责把“增量知识”周期性收敛为“稳定知识”。
- 零残留审计:
zero_residue_audit.py - 何时用: 发布/开源前;或者当你怀疑仓库混入了运行态残留、路径漂移、或文档索引失真时。
- 为什么要这么做: Agent 仓库必须可移植。任何环境残留都会在后续任务中污染上下文,诱发不可预测的行为。
4.4 辅助工具(tools):让“运行态”不污染“长期记忆”
- 工件归档:
archive_session_artifacts.py - 何时用: 一个任务结束后,将 runs 中临时生成的 openspec/focus_card 归档到 archive,避免 runs 目录成为“伪长期记忆”。
- 为什么要这么做: 把运行态与长期资产严格隔离,是对抗上下文膨胀与检索噪声的关键。
4.5 什么时候“必须用脚本”,什么时候“可以不用”
- 强烈建议必须用:
- 任何会修改代码库/文档库的 Change 任务(尤其是多人协作、PR 流程)。
- 任何涉及安全、凭证、SQL 迁移、依赖升级、对外 API 变更的任务。
- 任何你已经在历史上踩过坑的类别:把坑固化成门禁,变成永久回归测试。
- 可以不用(或降级为 quick):
- 纯粹阅读问答、纯分析、一次性探索(Learn/DocQA),且不落地变更。
- 极小的 patch,且范围明确、风险低(但仍建议至少跑 scope/secret 两项基础门禁)。
这套脚本工具链背后的原则只有一句话:把不确定性交给模型,把确定性交给工程。
第五部分:Token 经济学——用“思考税”对冲“返工险”
这套架构极其“重”,它必然会消耗比简单代码补全工具更多的 Token。但这是一笔极其划算的经济学买卖。
我们以开发一个跨表事务功能为例,对比三种工程模式在最新旗舰模型(如 GPT-5.4, Claude 3.7 Sonnet)下的真实 ROI:
开发范式 | 行为特征 | 隐性成本与风险 | 最终评价 |
纯对话 / Copilot | 缺乏上下文,直接生成代码。 | 极高的返工率。忘记加事务、漏字段。需要人类反复写 Prompt 去纠正。 | Token 极省,但极其消耗人类时间。 |
无约束的 Auto-Agent | 盲目调用 SearchCodebase 扫库,遇到编译报错陷入死循环重试。 | 灾难级损耗。因上下文过载和死循环,迅速烧光 Token 预算,触发平台熔断。 | 不可控,高风险。 |
Java Harness Agent | 缴纳适量的“思考税”(认知刹车),利用漏斗限流,写好 openspec.md 并在 Approval Gate 停下。 | 成本确定且可控。架构错误在前期被人类拦截,语法错误被左移验证消化。 | 甜点位 (The Sweet Spot)。用可控的 Token 消耗换取了高质量交付。 |
成本转移范式:
每次强制输出
<Cognitive_Brake> 和加载 SSOT,确实会产生约 ~2000 Input / ~500 Output 的“思考税”。但通过双重门控和防死循环机制,它省下了成千上万个盲目搜索的 Input Token,以及方向错误导致代码重写的海量 Output Token。结语:通往 Agentic OS 的未来
如果我们希望 AI 不仅仅是一个打字机,而是一个能够参与工程交付的“数字劳动力”,我们就必须停止把它当作“可以独立负责结果的人类”来对待。
从 2023 到 2026,大模型的能力边界变化得太快:上下文窗口、工具调用、代码能力、推理稳定性都在快速迭代。今天“必须靠流程兜底”的问题,明天可能被模型升级缓解;但反过来,模型一旦拥有更强的行动力,安全与治理的风险也会同步放大。正因如此,我们设计一套流程时,不应赌某一代模型的“发挥”,而应建立一种**模型无关(Model-Agnostic)**的工程防线:模型越强,流程越能释放效率;模型不稳定时,流程能把损失限制在可控范围内。
Java Harness Agent 的精髓在于克制:它不幻想用提示词把概率引擎训练成“永远正确的工程师”,而是用脚本门禁、生命周期状态机、HITL 停机点、知识写回与压缩,把不确定性包进一个可审计、可回放、可止损的流程里。大模型在这里的角色不是“替你负责”,而是“替你加速”。把方向盘留在人的手里,把油门交给模型,把刹车交给工程——这才是让智能体真正可落地、可规模化的道路。