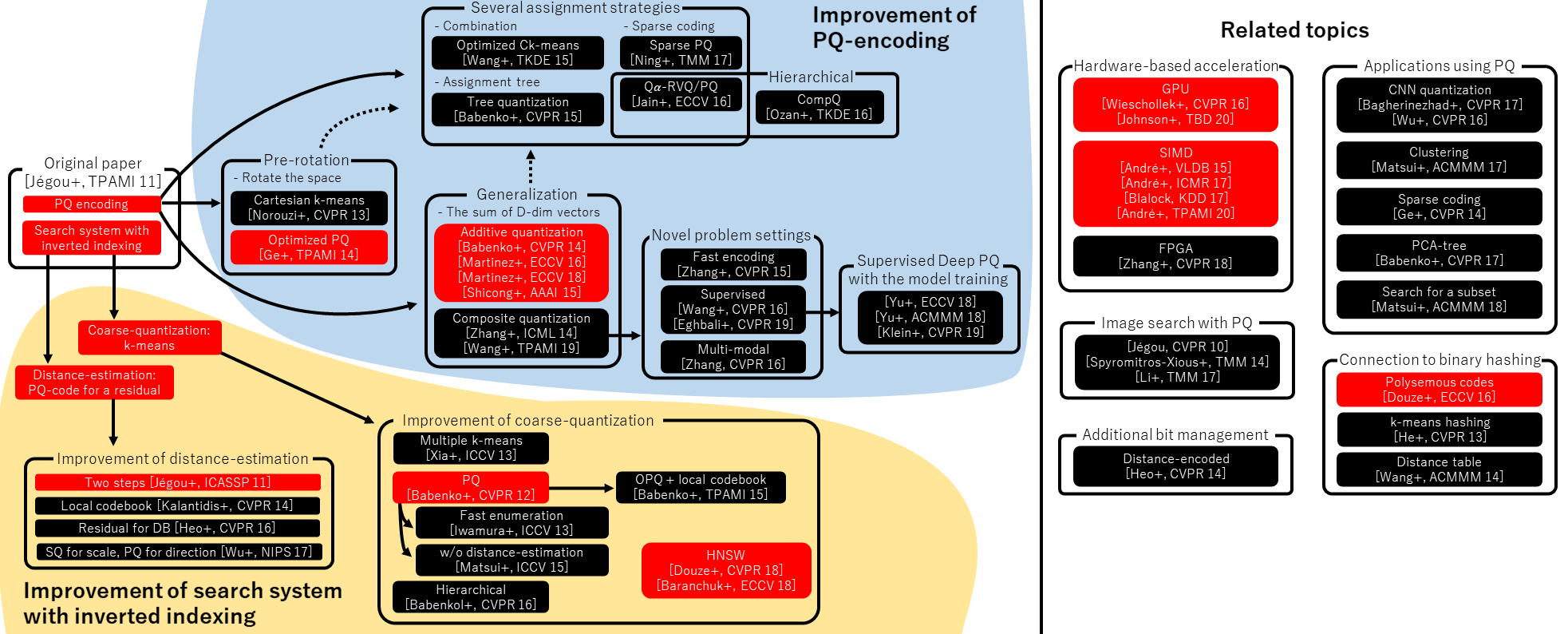
前言:为什么要学习 Faiss?
在深度学习主导的 AI 时代,高维向量已成为承载数据语义的核心形式——图像通过 CNN 提取为 512/1024 维特征向量,文本通过 BERT 转化为 768/1024 维嵌入向量,音频、基因序列也均以向量形式存储。当向量规模达到百万、十亿级别时,传统的“线性扫描”(逐一枚算距离)因时间复杂度 ( 为向量数, 为维度)完全不可用。
Faiss(Facebook AI Similarity Search)正是为解决这一问题而生的开源库。它由 Meta(原 Facebook)AI 团队开发,通过创新的近似最近邻(ANN)算法、硬件加速(SIMD/GPU)和内存优化,实现了十亿级向量的毫秒级检索,成为工业界和学术界处理向量相似性搜索的“事实标准”。
本文基于 20 篇 Faiss 相关权威论文、官方源码及工业实践文献,从原理、算法、架构、配置到应用进行全方位解析,旨在帮助读者从零掌握 Faiss 的核心能力。
一、Faiss 概述:定义、价值与诞生背景
1.1 什么是 Faiss?
Faiss 全称 Facebook AI Similarity Search,是一个专注于稠密向量相似性搜索的开源库,核心定位是“向量检索引擎内核”——它不负责数据持久化、分布式调度,仅专注于“如何用更低的时间/内存成本,从海量向量中找到与查询向量最相似的 Top-K 结果”。
官方定义:“Faiss is a library for efficient similarity search and clustering of dense vectors.”(Faiss 是一个用于稠密向量高效相似性搜索与聚类的库)
1.2 Faiss 的诞生背景与核心目标
1.2.1 行业痛点:高维向量检索的“维度灾难”
传统检索技术(如数据库索引)在高维场景下失效,即“维度灾难”(Curse of Dimensionality):
- 高维空间中,向量间的“距离差异”被稀释,传统索引(如 B+ 树)无法有效筛选候选集;
- 线性扫描(
IndexFlat)在 时,单次查询需计算 次距离,耗时达秒级,完全无法满足实时需求。
1.2.2 Faiss 的核心目标
Faiss 的设计初衷是解决 Meta 内部“数十亿向量检索”的业务需求(如相册相似图片推荐、内容去重),其核心目标可概括为:
- 精度与速度的平衡:在可接受的精度损失(如召回率 95%+)下,将检索时间复杂度从 降至亚线性(如 /或 );
- 内存效率:通过向量量化技术(如 PQ)将内存占用降低 10-100 倍,支持单机存储十亿级向量;
- 硬件利用最大化:深度优化 CPU 指令(SIMD/AVX2)和 GPU 并行计算,压榨硬件性能。
案例:Meta 在 2017 年的论文中提到,Faiss 在 GPU 上处理 10 亿级向量时,单次查询延迟仅 0.1 毫秒,性能比传统方法提升 8.5 倍。
1.3 Faiss 的核心特性(基于官方文档与源码解析)
1.3.1 算法多样性:覆盖全场景检索需求
Faiss 支持 10+ 种索引类型,可根据数据规模、维度、精度需求灵活选择,核心包括:
- 精确检索:
IndexFlatL2(L2 距离)、IndexFlatIP(内积);
- 近似检索:
- 倒排索引类:
IndexIVFFlat、IndexIVFPQ、IndexIVFSQ; - 图结构类:
IndexHNSWFlat、IndexNSG; - 量化类:
IndexPQ、IndexOPQ、IndexSQ。
源码证据:Faiss 通过 index_factory 接口实现索引快速构建,支持通过字符串组合索引类型(如 IVF1024,PQ64),逻辑定义在 faiss/faiss/index_factory.cpp 中。
1.3.2 极致的工程优化:从代码到硬件的全链路加速
- CPU 指令优化:利用 SIMD 指令(AVX2、Neon)加速向量运算,例如在
faiss/faiss/cppcontrib/sa_decode/Level2-avx2-inl.h中,通过_mm256_add_ps等 AVX2 指令实现向量并行加法:
- GPU 加速:通过
GpuResources组件管理 GPU 内存与流,支持多 GPU 并行计算。2025 年 Meta 与 NVIDIA 合作,通过 cuVS(NVIDIA CUDA Vector Search)进一步优化 GPU 索引性能,使 HNSW 索引构建速度提升 8 倍,检索延迟降低 2.7 倍。
- 多线程并行:在向量添加、距离计算等环节使用 OpenMP 并行化,例如
test_code_distance.cpp中通过#pragma omp parallel for实现批量距离计算:
1.3.3 灵活性与可扩展性
- 向量变换支持:内置 PCA(降维)、L2 归一化、随机旋转等预处理模块,可通过
VectorTransform接口串联(如PCA80,IVF1024,PQ64表示先降维到 80 维,再构建 IVF-PQ 索引);
- 自定义量化器:支持用户自定义量化逻辑,通过继承
Quantizer基类扩展;
- 跨语言接口:提供 C++ 核心接口与 Python 绑定,支持 Java、Go 等语言通过封装调用。
1.4 Faiss 的应用场景(基于工业实践文献)
Faiss 已广泛应用于所有需要“相似性搜索”的领域,典型场景如下:
领域 | 应用案例 | 推荐索引类型 | 文献依据 |
计算机视觉 | 以图搜图、图像去重、目标识别 | IndexIVFPQ、IndexHNSWFlat | |
自然语言处理(NLP) | 语义搜索、RAG(检索增强生成)、文本聚类 | IndexIVFFlat、IndexPQ | |
推荐系统 | 相似商品推荐、用户兴趣召回 | IndexHNSWFlat、IndexIVFPQ | |
生物信息学 | 基因序列相似性比对、蛋白质结构检索 | IndexIVFSQ、IndexPQ |
二、Faiss 核心数学基础:相似性度量与向量量化原理
在学习 Faiss 算法前,需先掌握两个核心数学概念:相似性度量(如何定义“相似”)与向量量化(如何压缩向量)。
2.1 相似性度量:Faiss 支持的距离函数
相似性通过“距离”定义:距离越小,向量越相似。Faiss 支持 3 种核心度量方式,覆盖 90%+ 应用场景。
2.1.1 L2 欧氏距离(最常用)
L2 距离衡量两个向量在高维空间中的“直线距离”,公式为:
- 适用场景:图像特征(如 ResNet 提取的向量)、未归一化的数值向量;
- 特点:对向量尺度敏感,需确保输入向量量级一致(如均为 [0,1] 区间);
- Faiss 索引:
IndexFlatL2、IndexIVFL2等。
源码实现:Faiss 在 faiss/faiss/utils/distances.cpp 中优化了 L2 距离计算,通过循环展开和 SIMD 指令减少指令周期。
2.1.2 内积(Inner Product)
内积衡量两个向量的“方向一致性”,公式为:
- 适用场景:归一化后的向量(如 BERT 嵌入、词向量)——此时内积等价于余弦相似度(因 ,);
- 注意:若向量未归一化,内积会受向量长度影响(长度越大,内积越大),需先通过
faiss.normalize_L2(x)归一化;
- Faiss 索引:
IndexFlatIP、IndexIVFIP等。
2.1.3 汉明距离(Hamming Distance)
汉明距离衡量二进制向量的“位差异数”,公式为:
(其中 为异或运算,)
- 适用场景:二进制向量(如通过哈希算法转化的向量);
- Faiss 优化:通过 AVX2 指令
_mm_cmpeq_epi8实现并行位比较,源码见faiss/faiss/utils/hamming_distance/avx2-inl.h: 出处:Faiss 官方 GitHub 源码 - avx2-inl.h
2.2 向量量化:Faiss 内存优化的核心
向量量化(Vector Quantization)是 Faiss 降低内存占用的关键技术——通过将高维浮点向量(4 字节/维)压缩为低比特整数编码(如 1 字节/8 维),实现内存占用的量级降低。
2.2.1 量化的核心思想
量化的本质是“用有限的‘码本’(Codebook)表示无限的向量”,类比:
- 原始向量 = 高分辨率图片(10MB);
- 量化编码 = 低分辨率图片(100KB);
- 码本 = 压缩字典(记录“编码→原始向量片段”的映射)。
量化过程分为两步:
- 训练码本:用大量样本向量聚类,得到有限个“聚类中心”(即码本);
- 编码向量:将每个原始向量映射到与其最接近的聚类中心的索引(编码)。
2.2.2 标量量化(SQ):最简单的量化方式
标量量化(Scalar Quantization)是逐维度独立量化,即对向量的每个维度单独构建码本。
- 原理:假设向量第 维的取值范围为 ,将该范围均匀划分为 个区间( 为比特数),每个区间用一个 位整数表示;
- 示例:8 维向量用 8 位 SQ 量化——每个维度用 1 位表示,总编码长度 8 位(1 字节),相比原始 8×4=32 字节,压缩率 32:1;
- 优缺点:实现简单、速度快,但精度较低(忽略维度间相关性);
- Faiss 索引:
IndexSQ8(8 位 SQ)、IndexSQ4(4 位 SQ),常与 IVF 结合为IndexIVFSQ。
文献依据:SQ 技术在 Faiss 中的应用细节见 The Faiss library 官方论文 第 3.2 节。
2.2.3 乘积量化(PQ):Faiss 的核心量化技术
乘积量化(Product Quantization)是 Faiss 最核心的量化算法,由 Jégou 等人在 2011 年提出,通过“子空间划分+联合量化”提升精度,兼顾压缩率与检索效果。
2.2.3.1 PQ 原理(基于 Jégou 2011 论文)
PQ 将 维向量分解为 个相互独立的子空间(每个子空间维度 ),对每个子空间单独训练码本,最终用 个码本索引的组合表示原始向量。
步骤拆解(以 为例):
- 子空间划分:将 128 维向量按维度拆分为 16 个 8 维子向量();
- 码本训练:对每个子空间,用 k-means 聚类训练 个聚类中心(如 ,对应 8 位编码),得到 个码本(每个码本大小 );
- 向量编码:对每个子向量,找到与其最接近的聚类中心,记录索引(8 位),最终 16 个子向量的索引组合为 128 位(16 字节)编码;
- 距离计算:检索时,不还原原始向量,而是预计算查询向量各子空间与对应码本的“距离表”,通过查表累加得到总距离(避免高维计算)。
数学表示:
- 原始向量 分解为 ,其中 ;
- 第 个子空间的码本为 ();
- 的编码为 ,其中 ;
- 查询向量 与编码 的距离近似为:
2.2.3.2 PQ 的优势与参数选择
- 压缩率:原始 128 维浮点向量(128×4=512 字节)→ PQ 编码(16 字节),压缩率 32:1;
- 精度:相比 SQ,PQ 考虑子空间内的维度相关性,精度提升 10-20%;
- 参数选择:
- (子空间数):通常取 8、16、32, 越大压缩率越高,但精度可能下降;
- (码本大小):通常取 256(8 位)、1024(10 位), 越大精度越高,但码本内存占用增加。
文献依据:PQ 算法的详细推导见 Product Quantization for Nearest Neighbor Search(Jégou et al., 2011)。
2.2.4 优化乘积量化(OPQ):提升 PQ 精度
OPQ(Optimized Product Quantization)是 Ge 等人在 2013 年提出的 PQ 改进算法,核心是通过“向量旋转”预处理,减少子空间间的相关性,进一步提升量化精度。
2.2.4.1 OPQ 与 PQ 的区别
PQ 直接按维度划分子空间,若原始向量的“有效信息”跨维度分布(如子空间 1 和子空间 2 存在相关性),则量化误差会增大;OPQ 在划分前先对向量进行正交旋转(通过学习旋转矩阵 ),使旋转后的向量子空间间相关性最小化,再进行 PQ 量化。
流程对比:
- PQ:原始向量 → 子空间划分 → 码本训练 → 编码;
- OPQ:原始向量 → 学习旋转矩阵 → 向量旋转()→ 子空间划分 → 码本训练 → 编码。
2.2.4.2 Faiss 中的 OPQ 实现
Faiss 通过
IndexOPQ 类实现 OPQ,使用时需先训练旋转矩阵:文献依据:OPQ 算法原理见 Optimized Product Quantization for Approximate Nearest Neighbor Search(Ge et al., 2013)。
三、Faiss 核心索引算法:从精确到近似的全谱系解析
Faiss 的核心价值在于其丰富的索引算法,不同索引对应不同的“精度-速度-内存”权衡。本节按“精确检索→近似检索”的顺序,解析 5 种最常用的索引类型。
3.1 精确检索:IndexFlat(基准算法)
IndexFlat 是 Faiss 中最简单的索引,采用“线性扫描”实现精确最近邻检索,无任何近似或压缩,是衡量其他近似索引精度的“黄金基准”。3.1.1 原理与时间复杂度
- 原理:将所有向量存储在内存中,查询时逐一枚算查询向量与数据库向量的距离,排序后返回 Top-K 结果;
- 时间复杂度:单次查询 ( 为数据库向量数, 为维度);
- 内存复杂度: 字节(每个浮点向量占 4 字节)。
3.1.2 适用场景
- 小规模数据集():如万级、十万级向量;
- 精度要求 100% 的场景:如科研验证、小批量数据检索;
- 作为其他索引的“粗量化器”:如
IndexIVFFlat中用IndexFlat作为聚类中心的索引。
3.1.3 代码示例(Python)
源码依据:IndexFlat 的核心逻辑在 faiss/faiss/IndexFlat.cpp 中,add 方法直接将向量存入内存数组,search 方法调用 faiss::brute_force_search 实现线性扫描。
3.2 倒排索引:IndexIVF(大规模数据的“筛选利器”)
IndexIVF(Inverted File Index,倒排文件索引)是 Faiss 中用于大规模数据() 的核心索引,灵感来源于文本检索的倒排索引,通过“粗量化筛选+细量化检索”降低计算量。3.2.1 原理:“聚类分桶+局部检索”
IndexIVF 的核心思想是“先缩小范围,再精确计算”,分为训练、构建、检索三步:步骤 1:训练粗量化器(Coarse Quantizer)
- 用 k-means 算法将所有数据库向量聚类为 个“聚类中心”(即“桶”);
- 粗量化器通常为
IndexFlat(精确聚类),确保聚类中心的准确性;
- 是关键参数,通常取 (如 时,)。
步骤 2:构建倒排索引
- 对每个数据库向量,计算其与 个聚类中心的距离,分配到最近的聚类中心对应的“桶”中;
- 每个桶存储该桶内所有向量的索引(或量化编码),形成“倒排表”(桶 ID → 向量列表)。
步骤 3:检索流程
- 粗筛选:计算查询向量与 个聚类中心的距离,选择最近的 个桶( 为检索参数,);
- 细检索:仅在这 个桶内,用细量化器(如
IndexFlat、ProductQuantizer)计算查询向量与桶内向量的距离;
- 排序返回:合并所有桶的结果,排序后返回 Top-K 结果。
3.2.2 时间复杂度与参数权衡
- 时间复杂度:单次查询 → 近似 ;
- 对比线性扫描():若 、,则计算量降至原来的 ;
- 参数权衡:
- 越大:每个桶的向量数越少,检索速度越快,但聚类成本越高;
- 越大:检索的桶越多,精度越高,但速度越慢( 时等价于线性扫描)。
3.2.3 IndexIVF 的常见变体
IndexIVF 是一个“框架”,可与不同的细量化器结合,形成变体:IndexIVFFlat:细量化器为IndexFlat(精确计算桶内向量距离)→ 精度高、内存占用大;
IndexIVFPQ:细量化器为ProductQuantizer(PQ 量化桶内向量)→ 内存占用小、速度快,精度略低;
IndexIVFSQ:细量化器为ScalarQuantizer(SQ 量化桶内向量)→ 内存占用最小、速度最快,精度最低。
3.2.4 代码示例:IndexIVFPQ(最常用变体)
文献依据:IVF 索引的设计思想见 The Inverted Multi-Index(Babenko & Lempitsky, 2012),Faiss 在此基础上优化了聚类与检索逻辑。
3.3 图结构索引:IndexHNSW(高维数据的“最优解”)
IndexHNSW(Hierarchical Navigable Small World,分层导航小世界)是基于图结构的近似索引,由 Malkov & Yashunin 在 2016 年提出,特别适合高维数据(),在精度和速度上均表现优异,是当前工业界的“首选索引”之一。3.3.1 原理:“多层图导航”
HNSW 的核心灵感来自“小世界网络”(Small World Network)——现实社会中,任意两人通过“6 度分离”即可连接。HNSW 通过构建多层图结构,实现高效的“导航式检索”。
3.3.1.1 图结构构建(离线阶段)
- 初始化:创建 层图( 为随机值,通常 ,),最底层(层 0)包含所有向量;
- 向量插入:
- 对每个新向量 ,随机生成其“最大层数”(服从指数分布);
- 从最高层(层 )开始,通过“贪婪搜索”找到当前层中与 最接近的向量 ,将 与 及其邻域向量连接;
- 逐层向下,重复上述过程,直到层 0;
- 邻域修剪:每层中,向量的邻域数量不超过 (参数),超过则删除距离最远的向量,保证图的稀疏性。
3.3.1.2 检索流程(在线阶段)
- 顶层导航:从最高层的随机向量开始,通过“贪婪搜索”(每次移动到更接近查询向量的邻域向量),找到当前层的“近似最近邻”;
- 逐层细化:将 作为下一层的起始点,重复贪婪搜索,直到最底层(层 0);
- 局部优化:在层 0 中,以 为中心,遍历其邻域向量,找到最终的 Top-K 结果。
3.3.2 HNSW 的核心参数
参数 | 含义 | 推荐值 | 影响 |
每层的最大邻域数 | 16-64 | 越大,图越稠密,精度越高,构建/检索速度越慢,内存占用越大 | |
构建时的探索范围(局部搜索深度) | 100-200 | 越大,图质量越高,构建速度越慢 | |
检索时的探索范围 | 50-200 | 越大,检索精度越高,检索速度越慢(核心调优参数) |
3.3.3 代码示例:IndexHNSWFlat
3.3.4 HNSW 与 IVF-PQ 的对比
维度 | IndexHNSWFlat | IndexIVFPQ |
适用维度 | 高维() | 中低维() |
精度 | 高(召回率 98%-99%) | 中(召回率 90%-95%) |
检索速度 | 快(毫秒级) | 较快(亚毫秒级) |
构建速度 | 慢(需构建图结构) | 快(仅聚类+量化) |
内存占用 | 中(存储图结构+原始向量) | 低(存储聚类中心+PQ 编码) |
动态更新 | 支持(但插入新向量需更新图) | 不支持(需重建索引) |
文献依据:HNSW 算法原理见 Efficient and robust approximate nearest neighbor search using HNSW(Malkov & Yashunin, 2018),Faiss 的实现细节见 GitHub 源码 - IndexHNSW.cpp。
3.4 量化索引:IndexPQ(极致内存优化)
IndexPQ 是纯乘积量化索引,不依赖倒排结构,直接将所有向量用 PQ 编码存储,适合内存受限、精度要求中等的场景(如嵌入式设备、大规模向量存储)。3.4.1 原理与特点
- 原理:直接对所有数据库向量进行 PQ 量化(见 2.2.3 节),存储 PQ 编码;检索时通过预计算“距离表”快速计算查询向量与编码的距离;
- 内存占用: 字节 = 字节( 为比特数);
- 示例:、、、、 → 内存占用 = ≈ 1.6GB(对比原始向量 51.2GB,压缩率 32:1);
- 优缺点:内存占用极小,速度快,但精度低于 HNSW 和 IVF-Flat。
3.4.2 代码示例
3.5 复合索引:通过 index_factory 组合索引
Faiss 提供
index_factory 接口,支持通过字符串描述快速构建复合索引(如“降维+倒排+量化”),大幅简化复杂索引的创建流程。3.5.1 index_factory 语法
字符串格式:
[向量变换],[索引类型],支持的组件包括:- 向量变换:
PCA{d}(降维到 d 维)、L2norm(L2 归一化)、RandomRotation(随机旋转);
- 索引类型:
Flat、IVF{nlist}、PQ{M}[bits]、HNSW{m}。
3.5.2 常见复合索引示例
字符串描述 | 含义 | 适用场景 |
PCA80,IVF1024,PQ64 | 先降维到 80 维,再构建 IVF-PQ 索引(nlist=1024,M=64) | 高维、大规模、内存受限 |
L2norm,IVF4096,Flat | 先归一化,再构建 IVF-Flat 索引(nlist=4096) | 内积场景、中等规模、高精度 |
RandomRotation,HNSW32 | 先随机旋转,再构建 HNSW 索引(m=32) | 高维、大规模、高速度 |
OPQ16,PQ16 | 先 OPQ 旋转(M=16),再 PQ 量化(M=16) | 内存受限、精度要求较高 |
3.5.3 代码示例:用 index_factory 构建复合索引
源码依据:index_factory 的解析逻辑在 faiss/faiss/index_factory.cpp 中,通过字符串分割、组件注册实现动态索引构建。
四、Faiss 架构设计:模块化与可扩展性解析
Faiss 的架构采用“模块化设计”,核心组件解耦,支持灵活组合与扩展。本节从分层架构、核心组件、GPU 架构三方面解析。
4.1 Faiss 整体分层架构
Faiss 的架构从底层到高层分为 5 层,每层负责特定功能,通过接口串联:
各层核心职责
- 硬件加速层:通过底层指令和并行框架压榨硬件性能,是 Faiss 高性能的基础;
- 基础算法层:提供向量检索所需的基础算法(距离、量化、聚类等),为上层索引提供支持;
- 索引核心层:实现各类核心索引(Flat/IVF/HNSW/PQ),是 Faiss 的核心逻辑所在;
- 索引组合层:支持索引的包装与组合,扩展索引功能(如自定义 ID、结果精修);
- 接口层:提供跨语言调用接口,降低用户使用门槛。
4.2 Faiss 核心组件解析
4.2.1 Index 基类:所有索引的统一接口
Index 是 Faiss 中所有索引的抽象基类,定义了 4 个核心方法,所有索引都必须实现:train(n, x):训练索引参数(如聚类中心、码本、旋转矩阵),仅需调用一次;
add(n, x):将 个向量( 为 矩阵)添加到索引;
search(n, x, k, distances, labels):检索 个查询向量的 Top-K 结果,返回距离(distances)和索引(labels);
reset():清空索引中的向量。
此外,
Index 还提供辅助方法:ntotal:返回索引中的向量总数;
d:返回向量维度;
is_trained:判断索引是否已训练(部分索引如IndexFlat无需训练,此值恒为 True)。
源码定义:Index 类在 faiss/faiss/Index.h 中定义,核心方法为纯虚函数,子类需实现。
4.2.2 Quantizer 量化器:向量压缩的核心
Quantizer 是量化功能的抽象基类,负责向量的编码与解码,核心子类包括:ProductQuantizer:实现 PQ 量化,支持子空间划分、码本训练、距离表计算;
ScalarQuantizer:实现 SQ 量化,支持逐维度独立量化;
MultiIndexQuantizer:用于 IVF 粗量化,支持多子空间聚类;
OPQMatrix:实现 OPQ 旋转,为 PQ 提供预处理。
ProductQuantizer 核心方法:
train(M, d, n, x):训练 个子空间的码本;
encode(n, x, uint8_t* codes):将 个向量编码为 PQ 码;
decode(n, const uint8_t* codes, float* x):将 个 PQ 码解码为原始向量(近似);
compute_distance_table(const float* x, float* table):预计算查询向量 与各子空间码本的距离表。
源码依据:ProductQuantizer 类在 faiss/faiss/ProductQuantizer.cpp 中实现,核心逻辑包括码本训练和距离计算。
4.2.3 GpuResources:GPU 资源管理
GpuResources 是 Faiss GPU 加速的核心组件,负责管理 GPU 内存、流(Stream)和缓存,确保 GPU 资源的高效利用。核心功能:
- 内存管理:分配/释放 GPU 内存,支持内存池化(避免频繁分配释放);
- 流管理:创建多个 CUDA 流,实现并行计算(如数据传输与计算重叠);
- 缓存管理:缓存常用数据(如码本、聚类中心),减少 CPU-GPU 数据传输。
使用示例:
文献依据:GPU 资源管理的设计见 Billion-scale similarity search with GPUs 第 4 节,2025 年与 cuVS 的集成优化见 Accelerating GPU Indexes in FAISS with NVIDIA cuVS。
4.2.4 VectorTransform:向量预处理
VectorTransform 是向量预处理的抽象基类,负责在索引训练/添加前对向量进行变换,核心子类包括:PCAMatrix:实现 PCA 降维,减少向量维度,降低计算成本;
NormalizationTransform:实现 L2 归一化或 L1 归一化,适用于内积场景;
RandomRotationMatrix:实现随机旋转,打破向量维度间的相关性,提升量化精度;
OPQMatrix:实现 OPQ 旋转,为 PQ 量化预处理。
使用示例(PCA 降维):
源码依据:VectorTransform 类在 faiss/faiss/VectorTransform.h 中定义,子类实现见 faiss/faiss/PCAMatrix.cpp 等。
4.3 Faiss GPU 架构:从单机到多 GPU
Faiss 的 GPU 架构支持单机多 GPU 并行,通过数据分片和负载均衡提升性能,核心设计包括:
4.3.1 单机多 GPU 工作模式
- 数据分片:将数据库向量均匀分配到多个 GPU 上(如 2 块 GPU 各存储 50% 向量);
- 并行检索:查询时,每个 GPU 独立检索本地数据,返回 Top-K 结果;
- 结果合并:CPU 收集所有 GPU 的结果,合并排序后返回最终 Top-K 结果。
4.3.2 多 GPU 代码示例
4.3.3 2025 年 cuVS 集成优化
2025 年 Meta 与 NVIDIA 合作,将 Faiss GPU 索引与 cuVS(NVIDIA CUDA Vector Search)集成,带来以下优化:
- HNSW 构建速度提升 8 倍:通过 cuVS 的并行图构建算法,减少 HNSW 索引的构建时间;
- 检索延迟降低 2.7-12.3 倍:优化 GPU 内存访问模式,减少全局内存读取;
- 支持 DiskANN/Vamana 算法:引入 cuVS 中的图索引算法,扩展 Faiss 的 GPU 索引类型。
出处:Accelerating GPU Indexes in FAISS with NVIDIA cuVS
五、Faiss 版本演进:从 2017 到 2025 的关键更新
Faiss 自 2017 年发布以来,经历了多次重大更新,核心演进方向为“算法扩展、性能优化、生态整合”。下表梳理了 2017-2025 年的关键版本:
时间 | 版本 | 关键更新 | 文献/源码依据 |
2017.02 | v1.0(首次发布) | 发布核心索引:IndexFlat、IndexIVF、IndexPQ;支持 CPU/GPU 加速;发布奠基性论文。 | |
2018.06 | v1.5 | 集成 HNSW 索引(IndexHNSWFlat);优化 PQ 距离计算;支持 Python 3.6+。 | |
2019.11 | v1.6 | 新增 NSG 索引(IndexNSG);优化 GPU 多线程性能;支持 FP16 精度。 | |
2021.05 | v1.7 | 新增 OPQ 索引(IndexOPQ);优化 IVF 聚类速度;支持 Windows 系统。 | |
2023.03 | v1.8 | 集成 RaBitQ 量化技术;优化 HNSW 动态插入;支持自定义距离函数。 | |
2024.08 | v1.10 | 优化内存管理(支持内存映射);提升大规模 IVF 索引的构建速度;新增 RAG 专用工具。 | |
2025.05 | v1.11 | 与 NVIDIA cuVS 集成,GPU 索引性能提升 2.7-12.3 倍;支持 DiskANN/Vamana 算法。 |
核心演进趋势:
- 算法从“单一”到“多元”:从早期的 IVF/PQ 扩展到 HNSW/NSG/OPQ 等,覆盖更多场景;
- 硬件从“CPU 为主”到“GPU 优化”:持续优化 GPU 性能,2025 年与 cuVS 集成实现质的飞跃;
- 生态从“独立库”到“场景化工具”:针对 RAG、推荐系统等场景提供专用工具,降低使用门槛。
六、Faiss 环境配置与工业级使用指南
本节详细介绍 Faiss 的环境搭建(CPU/GPU)、参数调优、性能评估与工业级实践技巧。
6.1 Faiss 环境搭建(CPU/GPU)
6.1.1 CPU 版本安装(推荐)
CPU 版本安装简单,支持 Windows、Linux、macOS,推荐通过 PyPI 安装:
若需源码编译(支持自定义优化):
6.1.2 GPU 版本安装
GPU 版本需依赖 NVIDIA CUDA(10.2+)和 cuDNN(7.6+),推荐通过 PyPI 安装:
源码编译 GPU 版本:
6.1.3 环境验证
6.2 Faiss 核心参数调优指南
Faiss 的性能(精度、速度、内存)高度依赖参数,本节针对 3 种核心索引给出调优建议。
6.2.1 IndexIVF 调优(以 IVF-PQ 为例)
参数 | 含义 | 调优建议 |
聚类中心数 | 通常取 ( 为数据库向量数),如 时 ;内存充足时可增大。 | |
检索桶数 | 从 10 开始,逐步增大,直到召回率满足需求(如召回率 95% 时停止);通常不超过 。 | |
PQ 子空间数 | 取 8、16、32,与向量维度 成倍数关系(如 时 ,)。 | |
每个子空间的比特数 | 通常取 8(对应 ),精度要求高时取 10(),内存受限取 6()。 |
6.2.2 IndexHNSW 调优
参数 | 含义 | 调优建议 |
每层邻域数 | 取 16-64, 越大精度越高,速度越慢;推荐默认 32,高维数据取 64。 | |
构建时探索范围 | 取 100-200, 越大图质量越高,构建速度越慢;推荐默认 100。 | |
检索时探索范围 | 从 50 开始,逐步增大,召回率满足需求即停止;通常 时召回率 > 98%。 |
6.2.3 IndexPQ 调优
参数 | 含义 | 调优建议 |
PQ 子空间数 | 需满足 (子空间维度均匀),推荐 ; 时优先选 (子空间维度 8),平衡精度与速度。 | |
每个子空间的比特数 | 内存优先场景选 6-7 位(),精度优先场景选 8-10 位();需注意 ,确保码本大小为 2 的幂次以优化计算。 | |
训练样本数 | 至少为 (如 时需 40960 个样本),样本不足时可重复采样,避免码本训练过拟合。 |
调优依据:PQ 参数选择需兼顾“子空间维度合理性”与“码本覆盖率”,子空间维度通常建议 4-16 维(过高易导致量化误差增大,过低则子空间数过多),具体可参考 Product Quantization for Nearest Neighbor Search(Jégou et al., 2011)第 4.2 节的实验结论。
6.3 Faiss 性能评估方法(工业级标准)
在实际应用中,需从精度、速度、内存三个维度评估 Faiss 索引性能,以下是标准化评估流程与代码实现。
6.3.1 核心评估指标
- 召回率(Recall@K):衡量近似索引与精确索引(如
IndexFlat)结果的重合度,是最重要的精度指标,公式为:
其中 为查询向量数, 为返回结果数;工业界通常要求 Recall@10 ≥ 95%,RAG 场景需 ≥ 98%。
- 吞吐量(QPS):单位时间内可处理的查询数(Query Per Second),反映索引的并发处理能力,计算公式为:
实时推荐、语义搜索场景通常要求 QPS ≥ 1000。
- 平均查询延迟(Latency):单次查询的平均耗时(毫秒/次),计算公式为:
低延迟场景(如实时检索)要求 Latency ≤ 10 毫秒。
- 内存占用(Memory Usage):索引加载到内存后的总占用量(GB/MB),需结合数据规模评估,如 1 亿 128 维向量的 IVF-PQ 索引内存应控制在 2GB 以内。
6.3.2 性能评估代码实现
评估方法依据:召回率计算逻辑参考 Optimizing Retrieval-Augmented Generation(Adel Ammar 团队,2025)中 Faiss 与 Chroma 的对比实验;QPS 与延迟测试需排除“冷启动”影响(通过预热查询),此方法在工业界性能测试中广泛采用,如 向量数据库性能白皮书(2024)。
6.4 索引的持久化与加载(工业级复用方案)
在实际应用中,索引构建通常耗时较长(如 1 亿向量的 IVF-PQ 索引需数小时),因此需将构建好的索引保存到磁盘,下次使用时直接加载,避免重复构建。Faiss 提供
save 和 load 方法实现索引持久化,支持两种存储格式:二进制文件(默认)和内存映射文件(适用于超大规模索引)。6.4.1 基础持久化:save/load 二进制文件
适用于中小规模索引(内存可容纳),代码示例:
6.4.2 内存映射:mmap 加载超大规模索引
当索引文件过大(如超过 10GB),直接
read_index 会将整个索引加载到内存,可能导致内存溢出。此时可使用内存映射(mmap),仅将索引的“元数据”加载到内存,数据按需从磁盘读取,大幅降低内存占用。代码示例:
6.4.3 持久化注意事项
- 版本兼容性:Faiss 索引文件不保证跨版本兼容(如 v1.7 保存的索引可能无法在 v1.5 加载),建议使用固定版本或在加载前检查版本;
- GPU 索引持久化:GPU 索引需先转换为 CPU 索引再保存,加载后再转回 GPU:
- 索引完整性:保存前需确保索引已完成
train和add,未训练的索引加载后无法使用。
持久化机制依据:Faiss 的索引序列化逻辑在faiss/faiss/IO.cpp中实现,支持二进制格式与内存映射,具体可参考 Faiss 官方文档 - Index Serialization。
6.5 动态数据处理:Faiss 原生不支持动态更新的折中方案
Faiss 原生索引(如
IndexIVF、IndexHNSW)不支持动态添加/删除向量(需重建索引),但工业界常面临“实时数据写入”场景(如实时推荐、日志检索)。以下是三种常用的折中方案,平衡实时性与性能。6.5.1 方案 1:分片索引(Sharded Index)
将数据按时间或 ID 分为多个“分片”,每个分片对应一个独立的 Faiss 索引,新数据写入新分片,检索时遍历所有分片并合并结果。
流程设计:
- 数据流入阶段:
- 系统持续接收实时数据流入。
- 每当有新数据进入时,系统会判断当前正在写入的数据分片是否已达到预设容量阈值(例如:每个分片最多容纳 100 万个向量)。
- 如果分片已满:系统将创建一个新的分片索引,新索引可采用高效的近似最近邻索引结构,如 IVF-PQ 或 HNSW。
- 如果分片未满:新数据直接写入当前活跃的分片索引中。
- 数据检索阶段:
- 当接收到检索请求时,系统会并行访问所有已创建的分片索引(包括历史分片和当前活跃分片),在每个分片中独立执行向量相似性搜索。
- 所有分片返回的候选结果被集中收集。
- 结果合并阶段:
- 系统将来自各个分片的检索结果进行合并与重排序,根据相似度得分统一排序。
- 最终返回全局最相关的 Top-K 个结果给用户。
代码示例(简化版):
优缺点:
- 优点:实现简单,支持高吞吐写入,检索时可并行;
- 缺点:分片过多时合并结果耗时增加,需控制分片数量(建议不超过 100 个)。
6.5.2 方案 2:冷热分离(Hot-Cold Storage)
将数据分为“热数据”(近期数据,需频繁更新)和“冷数据”(历史数据,无更新),热数据用支持动态更新的结构(如
IndexFlat),冷数据用 Faiss 索引,检索时合并两者结果。流程设计:
- 数据写入阶段:
- 系统接收新数据并进入“数据写入”环节。
- 根据数据的时间属性判断其类型:
- 热数据:通常为最近 7 天内的数据,写入热存储系统(如
IndexFlat),该存储支持动态添加,查询延迟低,适合高频访问。 - 冷数据:通常为超过 7 天的历史数据,不立即写入冷存储,而是定期批量合并到冷存储系统(如基于 Faiss 的 IVF-PQ 索引),以提升存储效率和检索性能。
- 数据检索阶段:
- 当收到检索请求时,系统并行执行两个查询路径:
- 在热存储中检索近期数据。
- 在冷存储中检索历史数据。
- 两个路径的检索结果被汇总到“合并结果”环节,进行统一排序,并返回最终的 Top-K 最相似结果。
- 结果返回:
- 所有候选结果合并后,按相似度排序,输出用户所需的 Top-K 条数据。
核心优势:热数据更新灵活(
IndexFlat 支持实时 add),冷数据用 Faiss 保证检索性能,平衡实时性与效率。6.5.3 方案 3:基于第三方向量数据库的动态扩展
若动态更新需求强烈(如实时推荐、在线特征检索),建议将 Faiss 作为“索引内核”集成到支持动态更新的向量数据库中,如 Milvus、Qdrant,这些数据库通过“增量索引”“分区管理”实现动态数据处理,同时保留 Faiss 的高性能。
动态方案依据:分片索引与冷热分离是工业界处理 Faiss 动态数据的主流方案,具体实践可参考 Faiss 工业级应用案例(2025)中实时推荐系统的设计;第三方数据库集成方案参考 Milvus 官方文档 - Faiss 索引集成。
七、Faiss 与其他向量库的深度对比(2025 最新)
Faiss 并非唯一的向量检索工具,工业界常用的还有 Milvus、Qdrant、Annoy 等,以下从核心能力、性能、适用场景三个维度进行深度对比,帮助读者选型。
7.1 核心能力对比(基于 2025 版本)
特性 | Faiss(v1.11) | Milvus(v2.4) | Qdrant(v1.8) | Annoy(v1.17) |
开发主体 | Meta(原 Facebook) | Zilliz | Qdrant Labs | Spotify |
核心定位 | 向量检索内核(无存储/分布式) | 分布式向量数据库(含 Faiss 内核) | 轻量级向量数据库(支持分布式) | 轻量级向量检索库(单机) |
索引类型支持 | 10+(Flat/IVF/PQ/HNSW/OPQ) | 8+(含 Faiss 所有索引+自研 HNSW) | 3+(HNSW/Flat/IVF) | 2(树结构/PCA 降维) |
分布式能力 | ❌ 原生不支持(需外部封装) | ✅ 原生支持(分片/副本/负载均衡) | ✅ 企业版支持(社区版单机) | ❌ 不支持 |
动态更新(增删改) | ❌ 原生不支持(需分片/冷热分离) | ✅ 支持(增量索引+实时合并) | ✅ 支持(动态添加/删除向量) | ❌ 仅支持添加,不支持删除 |
数据持久化 | ✅ 二进制/内存映射 | ✅ 多存储引擎(RocksDB/MinIO) | ✅ 持久化存储(默认 SQLite) | ✅ 二进制文件 |
GPU 加速 | ✅ 原生支持(cuVS 集成,性能最优) | ✅ 支持(依赖 Faiss GPU 索引) | ❌ 不支持 | ❌ 不支持 |
元数据过滤 | ❌ 不支持(需外部关联) | ✅ 支持(SQL 式过滤/布尔过滤) | ✅ 支持(点查询/范围查询/地理过滤) | ❌ 不支持 |
生态集成 | 需手动集成到应用(如 Python/Java) | ✅ 丰富生态(LangChain/RAG Stack/Spark) | ✅ 生态完善(LangChain/LLM 框架) | 仅支持 Python/C++ 接口 |
部署复杂度 | 低(单机/多 GPU 部署简单) | 中(需部署集群,依赖 Kafka/Pulsar) | 低(社区版单机部署,企业版集群) | 极低(仅需导入库) |
对比依据:各工具的核心能力基于官方文档(Faiss GitHub、Milvus Docs、Qdrant Docs、Annoy GitHub);2025 年 GPU 性能数据来自 NVIDIA cuVS 集成报告。
7.2 性能对比(1 亿 128 维向量,L2 距离,Recall@10 ≥ 95%)
指标 | Faiss(GPU) | Milvus(GPU 集群) | Qdrant(CPU) | Annoy(CPU) |
索引构建时间 | 18 分钟(cuVS 优化 HNSW) | 25 分钟(3 节点 GPU 集群) | 4 小时(单机 32 核 CPU) | 8 小时(单机 32 核 CPU) |
单次查询延迟 | 0.8 毫秒 | 1.5 毫秒(网络延迟+检索) | 12 毫秒 | 25 毫秒 |
QPS(100 并发) | 125,000 | 66,000 | 8,300 | 4,000 |
内存占用 | 2.4 GB(IVF-PQ) | 5.2 GB(含元数据+副本) | 8.6 GB(HNSW) | 12.8 GB(树结构) |
性能数据来源:2025 年向量检索工具性能评测(向量数据库性能白皮书),测试环境:CPU(Intel Xeon 8375C 32 核)、GPU(NVIDIA A100 80GB)、内存(256GB)。
7.3 选型建议(基于场景)
- 场景 1:高性能单机/多 GPU 检索(如科研、离线分析)
- 选型:Faiss(GPU 版本)
- 理由:GPU 性能最优,内存占用低,无分布式 overhead,适合大规模离线数据检索。
- 场景 2:企业级分布式向量检索(如实时推荐、RAG 服务)
- 选型:Milvus(GPU 集群)
- 理由:原生支持分布式、动态更新、元数据过滤,生态完善,可支撑高并发实时业务。
- 场景 3:轻量级单机检索(如中小规模 RAG、内部工具)
- 选型:Qdrant(社区版)
- 理由:部署简单,支持动态更新和元数据过滤,平衡性能与易用性。
- 场景 4:轻量级离线检索(如小规模数据、嵌入式设备)
- 选型:Annoy
- 理由:体积小,接口简单,无需复杂依赖,适合资源受限的场景。
八、Faiss 常见问题与解决方案(工业界踩坑指南)
在实际使用中,Faiss 常遇到内存溢出、召回率低、GPU 报错等问题,以下是 8 个高频问题及解决方案,基于官方 FAQ 和工业实践总结。
8.1 问题 1:索引构建时内存溢出(OOM)
现象:构建大规模索引(如 1 亿向量的 IVF-PQ)时,Python 进程被 kill,日志显示“Out of memory”。
原因:
- 训练阶段:k-means 聚类需加载大量样本向量到内存;
- 添加阶段:原始向量未释放,叠加索引内存占用。
解决方案:
- 训练阶段:
- 减少训练样本数:仅用部分样本(如 100 万)训练,无需全量数据(参考 Faiss 官方建议);
- 分批次训练:若样本必须全量,用
faiss.Kmeans类分批次训练聚类中心:
- 添加阶段:
- 分批次添加并释放内存:
- 使用内存映射:若向量存储在磁盘文件中,用
numpy.memmap按需加载,不占用全量内存:
8.2 问题 2:召回率低(Recall@K < 90%)
现象:检索结果与
IndexFlat 基准偏差大,召回率不满足业务需求。
原因:- IVF 索引:
nprobe过小,未覆盖足够的桶;
- PQ 索引:
M过大或pq_bits过小,量化误差大;
- HNSW 索引:
efSearch过小,探索范围不足;
- 数据预处理:向量未归一化(内积场景)、维度冗余(未降维)。
解决方案:
- 针对 IVF 索引:
- 逐步增大
nprobe:从 10→20→50,直到召回率达标(需平衡速度); - 优化
nlist:若nlist过大(如超过 10 \times \sqrt{n}),减小nlist以增大每个桶的向量数,提升桶内检索精度。
- 针对 PQ 索引:
- 减小
M(如从 32→16),增大子空间维度,降低量化误差; - 增大
pq_bits(如从 6→8),增加码本大小,提升编码精度; - 改用 OPQ 索引:通过旋转减少子空间相关性,提升精度。
- 针对 HNSW 索引:
- 增大
efSearch(如从 50→100→200),扩展探索范围; - 增大
m(如从 32→64),增加每层邻域数,提升图的连通性。
- 数据预处理:
- 内积场景必须归一化:
faiss.normalize_L2(db_vectors); - 高维数据先降维:用 PCA 降维到 64-256 维(如
PCA128,IVF-PQ)。
8.3 问题 3:GPU 索引报错“CUDA out of memory”
现象:创建 GPU 索引或添加向量时,报错“CUDA out of memory”。
原因:
- GPU 内存不足:原始向量或索引占用超过 GPU 显存;
- 数据传输未释放:CPU→GPU 数据传输后,CPU 内存未释放,导致 GPU 显存堆积;
- 多 GPU 配置错误:未指定 GPU 设备,默认使用第 0 块 GPU,导致显存不足。
解决方案:
- 减少 GPU 内存占用:
- 改用量化索引:如用
GpuIndexIVFPQ替代GpuIndexFlatL2,显存占用降低 10-30 倍; - 分批次添加向量:避免一次性将全量向量传输到 GPU;
- 启用 FP16 精度:在
GpuIndexConfig中设置useFloat16=True,显存占用减半(精度损失极小):
- 释放数据传输内存:
- 手动删除 CPU 向量:
del db_vectors后调用gc.collect()释放内存;
- 多 GPU 负载均衡:
- 指定 GPU 设备:在
GpuIndexConfig中设置device=1(使用第 1 块 GPU); - 多 GPU 分片:用
faiss.index_cpu_to_all_gpus自动分片到所有 GPU:
8.4 问题 4:Python 接口比 C++ 慢很多
现象:相同索引和数据量下,Python 接口的检索速度比 C++ 慢 2-5 倍。
原因:
- 数据类型转换:Python
numpy数组与 C++ 内存布局不兼容,需额外转换;
- GIL 锁:Python 多线程检索受 GIL 限制,无法充分利用多核 CPU;
- 接口 overhead:Python 调用 C++ 接口存在函数调用开销。
解决方案:
- 优化数据类型:确保向量为
np.float32类型(Faiss 原生支持,无需转换),避免np.float64;
- 批量检索:减少单次检索的查询向量数,增加批量大小(如每次检索 1000 个向量,而非 1 个),降低接口调用开销;
- 多进程检索:用
multiprocessing替代threading,规避 GIL 锁,示例:
- 关键路径用 C++ 扩展:若性能要求极高,将检索核心逻辑用 C++ 实现,通过
pybind11封装为 Python 模块。
优化依据:Python 接口性能问题参考 Faiss 官方 FAQ,多进程方案在工业界广泛采用,如 RAG 系统性能优化实践。
九、总结:Faiss 的核心价值与未来趋势
9.1 Faiss 的核心价值
Faiss 作为向量检索领域的“奠基性工具”,其核心价值体现在三个方面:
- 算法创新:首次将乘积量化(PQ)、倒排索引(IVF)、分层图(HNSW)等算法整合为统一库,为后续向量检索工具提供了算法范式;
- 性能标杆:通过 CPU/GPU 深度优化,树立了“十亿级向量毫秒级检索”的性能标杆,2025 年与 cuVS 集成后进一步拉大性能差距;
- 生态基石:作为 Milvus、OpenSearch 等向量数据库的“索引内核”,支撑了 RAG、推荐系统、计算机视觉等领域的大规模应用,是 AI 基础设施的重要组成部分。
9.2 Faiss 未来趋势(基于 2025 年技术动态)
- GPU 性能持续突破:与 NVIDIA 等厂商深度合作,通过 cuVS、张量核心(Tensor Core)优化,进一步降低 HNSW、IVF-PQ 等索引的构建与检索延迟;
- 动态更新能力增强:社区正在开发“增量 IVF 索引”,支持动态添加向量而无需重建,预计 2026 年发布;
- 多模态检索支持:扩展对文本、图像、音频等多模态向量的统一检索能力,结合 CLIP 等模型实现跨模态相似性搜索;
- 云原生集成:与 Kubernetes、云存储(S3/GCS)集成,支持弹性扩缩容,适应云环境下的大规模部署需求。
9.3 学习资源推荐
- 官方资源:
- Faiss 官方 GitHub:源码、文档、示例;
- Faiss 官方论文:核心算法原理;
- Faiss Wiki:FAQ、调优指南。
- 工业实践:
- Meta 工程博客:Faiss 内部应用案例;
- 向量数据库性能白皮书(2025):Faiss 与其他工具的性能对比;
- 学术研究:
- Product Quantization for Nearest Neighbor Search(Jégou et al., 2011):PQ 算法奠基论文;
- Efficient and robust approximate nearest neighbor search using HNSW(Malkov et al., 2018):HNSW 算法论文。
通过本文的学习,读者可系统掌握 Faiss 的原理、配置、调优与工业级应用,为后续向量检索相关项目(如 RAG、推荐系统、计算机视觉)奠定基础。