
List
ArrayList
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。ArrayList继承于 AbstractList ,实现了 List, RandomAccess, Cloneable, java.io.Serializable 这些接口。RandomAccess是一个标志接口,表明实现这个这个接口的 List 集合是支持快速随机访问的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
ArrayList实现了Cloneable接口 ,即覆盖了函数clone(),能被克隆。
ArrayList实现了java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
与Vector的区别
ArrayList是List的主要实现类,底层使用Object[ ]存储,适用于频繁的查找工作,线程不安全 ;
Vector是List的古老实现类,底层使用Object[ ]存储,线程安全的。
与LinkedList区别
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全;
- 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
- 插入和删除是否受元素位置的影响: ①
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ②LinkedList采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
- 内存空间占用:
ArrayList的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
扩容机制
JDK8)ArrayList 有三种方式来初始化,构造方法源码如下:
细心的同学一定会发现 :以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
补充:JDK7 new无参构造的ArrayList对象时,直接创建了长度是10的Object[]数组elementData 。jdk7中的ArrayList的对象的创建类似于单例的饿汉式,而jdk8中的ArrayList的对象的创建类似于单例的懒汉式。JDK8的内存优化也值得我们在平时开发中学习。
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了
ensureCapacityInternal()方法 ,所以 minCapacity 此时为 10。此时,minCapacity - elementData.length > 0成立,所以会进入grow(minCapacity)方法。
- 当 add 第 2 个元素时,minCapacity 为 2,此时 e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,
minCapacity - elementData.length > 0不成立,所以不会进入 (执行)grow(minCapacity)方法。
- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
grow()方法
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
我们再来通过例子探究一下
grow() 方法 :- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入
hugeCapacity方法。数组容量为 10,add 方法中 return true,size 增为 1。
- 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
- 以此类推······
这里补充一点比较重要,但是容易被忽视掉的知识点:
- java 中的
length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
- java 中的
length()方法是针对字符串说的,如果想看这个字符串的长度则用到length()这个方法.
- java 中的
size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
LinkedList
LinkedList是一个实现了List接口和Deque接口的双端链表。 LinkedList底层的链表结构使它支持高效的插入和删除操作,另外它实现了Deque接口,使得LinkedList类也具有队列的特性; LinkedList不是线程安全的,如果想使LinkedList变成线程安全的,可以调用静态类Collections类中的synchronizedList方法:
如下图所示:
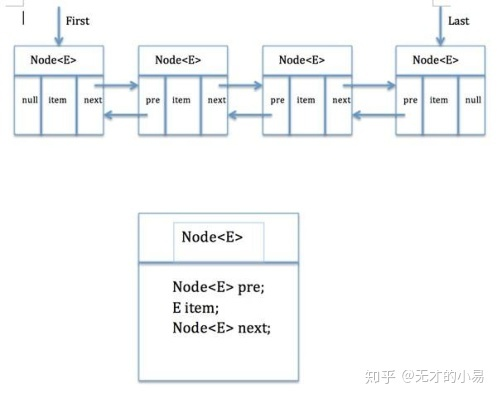
看完了图之后,我们再看LinkedList类中的一个
内部私有类Node
就很好理解了:
这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继结点。
HashMap
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现,是常用的Java集合之一。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考
treeifyBin方法。底层结构
1.8前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过
(n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。

1.8后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
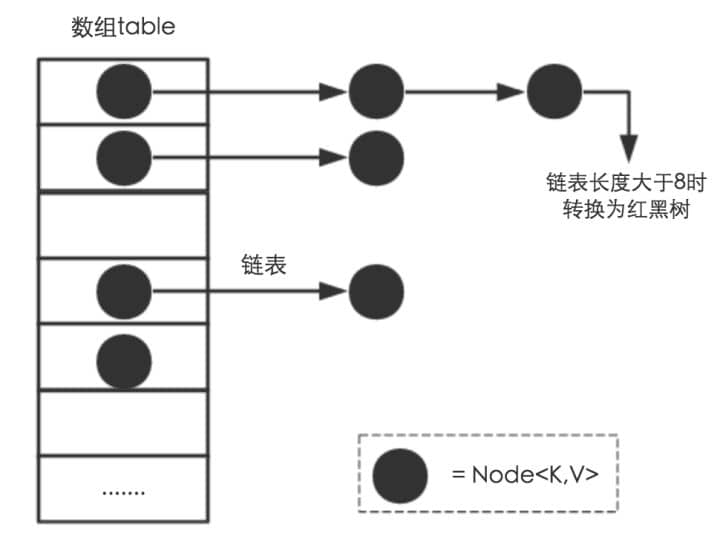
类的属性:
- loadFactor加载因子
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
- threshold
threshold = capacity \ loadFactor*,当Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
put方法(扩容)
HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
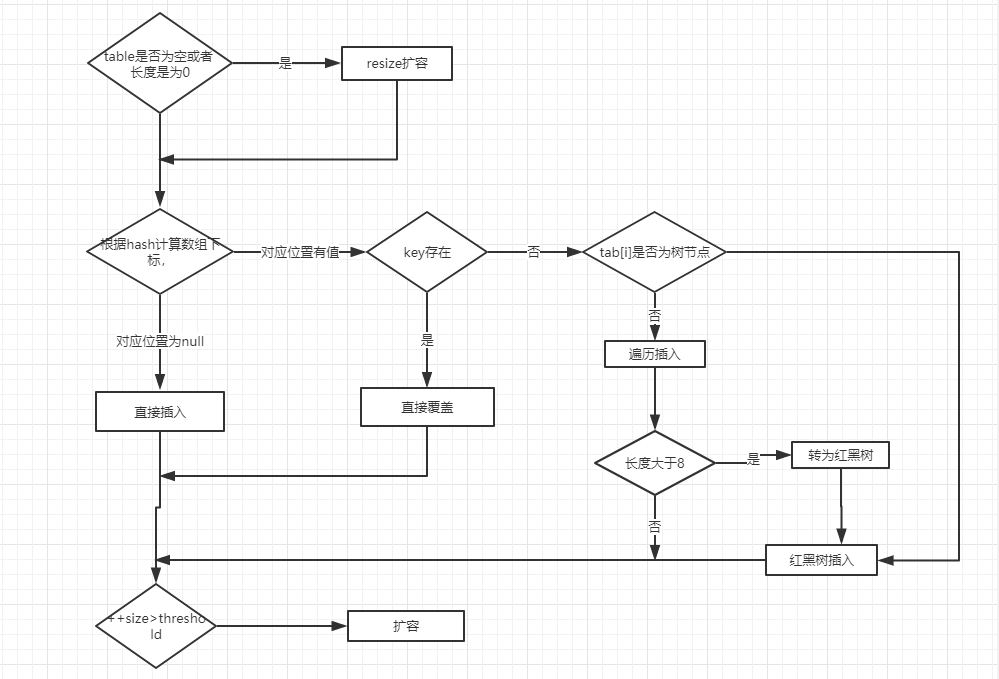
对putVal方法添加元素的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
ps:下图有一个小问题,来自 issue#608指出:直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行。
我们再来对比一下 JDK1.7 put方法的代码
对于put方法的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
resize方法
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
- LinkedList的底层结构是双端链表,支持高效的插入和删除操作,同时实现了Deque接口,也具有队列的特性。
- HashMap主要用来存放键值对,基于哈希表的Map接口实现,是常用的Java集合之一。JDK1.8之前的HashMap由数组+链表组成,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。JDK1.8以后,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
- 在进行扩容时,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的,要尽量避免resize。











